Challenges in Mechanistically Interpreting Model Representations

0
Sign in to get full access
Overview
- This paper discusses new approaches for studying model representations, particularly in the context of machine learning and AI systems.
- The authors argue that current frameworks for understanding model representations have limitations and propose new directions for research in this area.
- Key focus areas include feature representations, mechanistic interpretability, and information-theoretic approaches to understanding model representations.
Plain English Explanation
The paper explores new ways to study how machine learning models work under the hood. Current methods for analyzing model representations - the features and internal structures that models use to make decisions - have some limitations. The authors suggest exploring new directions to get a better handle on how these models operate.
One area they highlight is feature representations. This looks at the specific features or characteristics that models use as the building blocks for their decisions. Another focus is mechanistic interpretability, which aims to open up the "black box" of machine learning models and understand the underlying mechanisms driving their behavior.
The paper also discusses applying information theory as a framework for studying model representations. This could provide new insights into how models represent and process information.
Overall, the goal is to develop richer and more nuanced ways of understanding how complex machine learning systems work, with applications in areas like model performance analysis and AI safety.
Technical Explanation
The paper argues that current frameworks for studying model representations, such as feature visualization and probing, have important limitations. The authors propose exploring new research directions to develop more comprehensive and insightful approaches.
One key area is feature representations. The paper suggests going beyond simple feature attribution to analyze the hierarchical and compositional structure of features learned by models. This could reveal deeper insights into how models extract and combine relevant information.
The authors also highlight the importance of mechanistic interpretability - understanding the internal mechanisms and causal dynamics driving a model's behavior. This goes beyond simply identifying salient features to uncover the underlying computational principles at work.
In addition, the paper discusses applying information-theoretic frameworks to model representations. This could provide a principled way to quantify and analyze how models represent and transform information, potentially leading to new interpretability techniques.
The paper outlines several research directions in these areas, including developing new mathematical frameworks, designing interpretability-focused model architectures, and conducting targeted experiments to probe model representations.
Critical Analysis
The paper makes a compelling case for the limitations of current approaches to model interpretability and the need for new frameworks. The authors identify important open questions and promising research directions that could significantly advance the field.
However, the paper also acknowledges the significant challenges involved. Developing truly mechanistic interpretability for complex machine learning models remains an open and difficult problem. Information-theoretic approaches, while promising, may also face practical hurdles in terms of scalability and the ability to produce interpretable insights.
Additionally, the paper does not delve into potential ethical and societal implications of these research directions. As model interpretability becomes more sophisticated, it will be important to consider how these techniques could be applied responsibly and with appropriate safeguards.
Overall, the paper provides a thoughtful and well-reasoned roadmap for new avenues of research on model representations. While the challenges are substantial, the potential benefits in terms of improving model performance, safety, and transparency make this a valuable area of exploration.
Conclusion
This paper outlines an ambitious agenda for developing new frameworks to study model representations in machine learning. By exploring feature representations, mechanistic interpretability, and information-theoretic approaches, the authors argue that researchers can gain deeper insights into how complex AI systems operate.
These advancements could have significant implications, from enhancing model performance analysis to improving AI safety and robustness. While the technical hurdles are considerable, the potential payoffs in terms of understanding and trust in machine learning make this a crucial area of research to pursue.
Ultimately, the paper highlights the importance of continuing to push the boundaries of model interpretability. As machine learning becomes more pervasive, developing richer and more nuanced approaches to understanding model representations will be key to realizing the full potential of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Challenges in Mechanistically Interpreting Model Representations
Satvik Golechha, James Dao
Mechanistic interpretability (MI) aims to understand AI models by reverse-engineering the exact algorithms neural networks learn. Most works in MI so far have studied behaviors and capabilities that are trivial and token-aligned. However, most capabilities important for safety and trust are not that trivial, which advocates for the study of hidden representations inside these networks as the unit of analysis. We formalize representations for features and behaviors, highlight their importance and evaluation, and perform an exploratory study of dishonesty representations in `Mistral-7B-Instruct-v0.1'. We justify that studying representations is an important and under-studied field, and highlight several challenges that arise while attempting to do so through currently established methods in MI, showing their insufficiency and advocating work on new frameworks for the same.
Read more7/15/2024

1
A Practical Review of Mechanistic Interpretability for Transformer-Based Language Models
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, Ziyu Yao
Mechanistic interpretability (MI) is an emerging sub-field of interpretability that seeks to understand a neural network model by reverse-engineering its internal computations. Recently, MI has garnered significant attention for interpreting transformer-based language models (LMs), resulting in many novel insights yet introducing new challenges. However, there has not been work that comprehensively reviews these insights and challenges, particularly as a guide for newcomers to this field. To fill this gap, we present a comprehensive survey outlining fundamental objects of study in MI, techniques that have been used for its investigation, approaches for evaluating MI results, and significant findings and applications stemming from the use of MI to understand LMs. In particular, we present a roadmap for beginners to navigate the field and leverage MI for their benefit. Finally, we also identify current gaps in the field and discuss potential future directions.
Read more7/4/2024
🗣️
0
The Cognitive Revolution in Interpretability: From Explaining Behavior to Interpreting Representations and Algorithms
Adam Davies, Ashkan Khakzar
Artificial neural networks have long been understood as black boxes: though we know their computation graphs and learned parameters, the knowledge encoded by these weights and functions they perform are not inherently interpretable. As such, from the early days of deep learning, there have been efforts to explain these models' behavior and understand them internally; and recently, mechanistic interpretability (MI) has emerged as a distinct research area studying the features and implicit algorithms learned by foundation models such as large language models. In this work, we aim to ground MI in the context of cognitive science, which has long struggled with analogous questions in studying and explaining the behavior of black box intelligent systems like the human brain. We leverage several important ideas and developments in the history of cognitive science to disentangle divergent objectives in MI and indicate a clear path forward. First, we argue that current methods are ripe to facilitate a transition in deep learning interpretation echoing the cognitive revolution in 20th-century psychology that shifted the study of human psychology from pure behaviorism toward mental representations and processing. Second, we propose a taxonomy mirroring key parallels in computational neuroscience to describe two broad categories of MI research, semantic interpretation (what latent representations are learned and used) and algorithmic interpretation (what operations are performed over representations) to elucidate their divergent goals and objects of study. Finally, we elaborate the parallels and distinctions between various approaches in both categories, analyze the respective strengths and weaknesses of representative works, clarify underlying assumptions, outline key challenges, and discuss the possibility of unifying these modes of interpretation under a common framework.
Read more8/13/2024
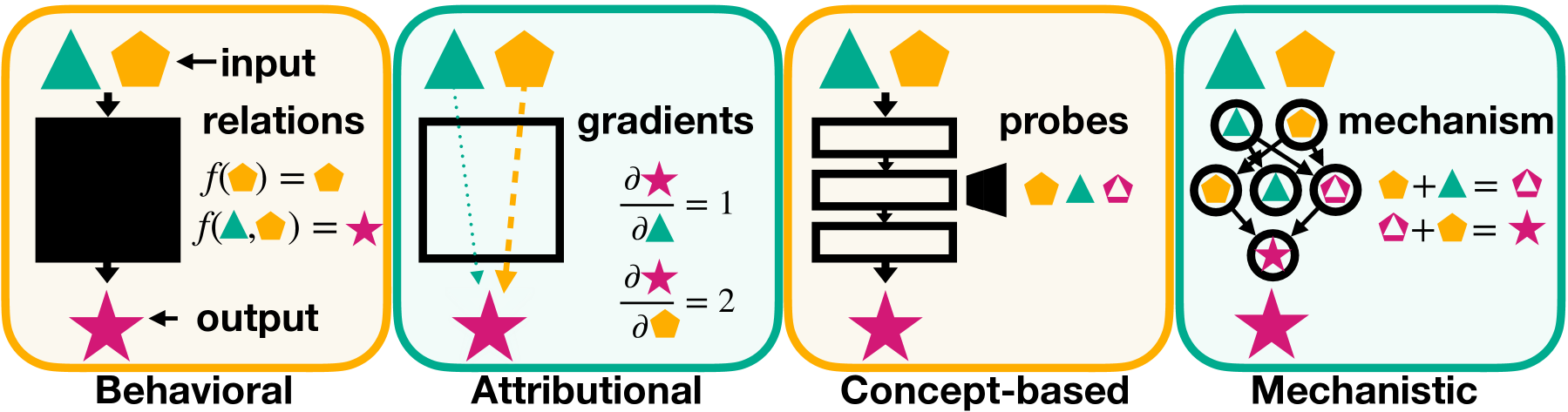
0
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska, Efstratios Gavves
Understanding AI systems' inner workings is critical for ensuring value alignment and safety. This review explores mechanistic interpretability: reverse engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding. We establish foundational concepts such as features encoding knowledge within neural activations and hypotheses about their representation and computation. We survey methodologies for causally dissecting model behaviors and assess the relevance of mechanistic interpretability to AI safety. We examine benefits in understanding, control, alignment, and risks such as capability gains and dual-use concerns. We investigate challenges surrounding scalability, automation, and comprehensive interpretation. We advocate for clarifying concepts, setting standards, and scaling techniques to handle complex models and behaviors and expand to domains such as vision and reinforcement learning. Mechanistic interpretability could help prevent catastrophic outcomes as AI systems become more powerful and inscrutable.
Read more8/27/2024