Chaos-based reinforcement learning with TD3

0
Sign in to get full access
Overview
- This paper proposes a novel approach to reinforcement learning (RL) called "Chaos-based reinforcement learning with TD3".
- The method combines the concept of chaos theory with the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm, a popular RL technique.
- The authors claim this approach can improve the performance and stability of RL agents in continuous control tasks.
Plain English Explanation
The paper describes a new way of training artificial intelligence (AI) systems to perform tasks in complex, real-world environments. The key idea is to introduce "chaos" - unpredictable changes and fluctuations - into the training process, which the authors believe can help the AI become more adaptable and robust.
Traditionally, RL algorithms like TD3 have been used to train AI agents to master tasks like controlling robots or playing video games. These methods rely on the agent gradually learning from trial and error to optimize its behavior.
The researchers in this paper propose adding an element of chaos to the training process. By introducing random disturbances and unpredictable changes, they hope to force the AI to develop more flexible and creative problem-solving strategies, similar to how living organisms adapt to cope with the chaos of the natural world.
This chaos-based approach could have applications in areas like robotic control, where AI agents need to handle unexpected situations and disturbances. It may also be useful for continuous control tasks where the environment is constantly changing.
Technical Explanation
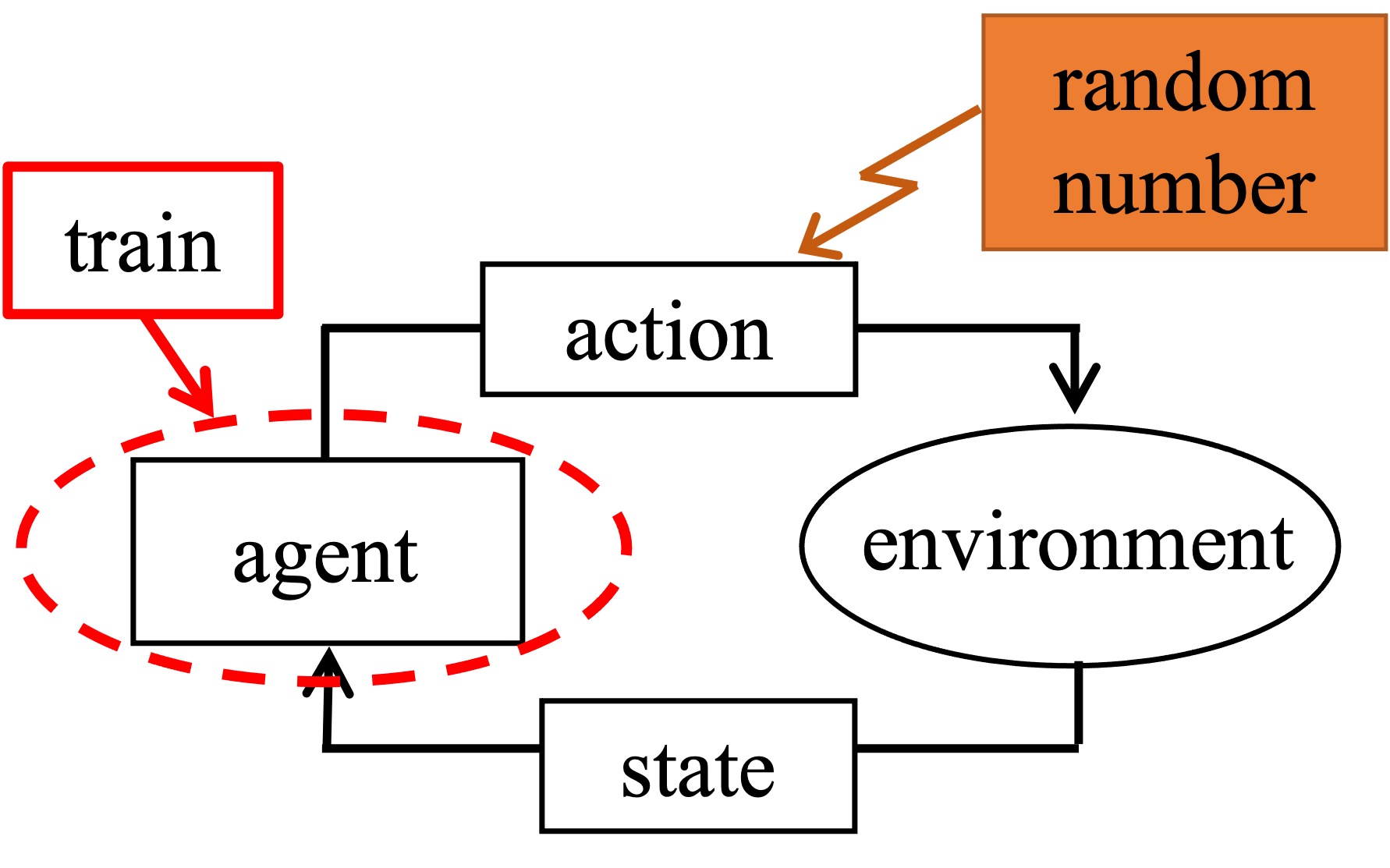
The core of the proposed method is the integration of chaos theory principles into the TD3 RL algorithm. Specifically, the authors introduce a "chaotic exploration" mechanism that generates non-stationary, unpredictable perturbations to the agent's actions during training.
This is achieved by modeling the agent's exploration noise using a chaotic dynamical system, such as the logistic map or the Lorenz attractor. The chaotic noise is then added to the agent's actions, causing it to explore the environment in a more unpredictable and adaptive manner.
The authors hypothesize that this chaos-based exploration can help the agent learn more robust and generalizable policies, as it is forced to cope with a wider range of environmental conditions and disturbances during training.
To evaluate their approach, the researchers conduct experiments on several continuous control benchmark tasks, such as the MuJoCo suite. They compare the performance of their chaos-based TD3 agent to the standard TD3 algorithm and other state-of-the-art RL methods.
The results suggest that the chaos-based approach can indeed improve the learning efficiency and final performance of the RL agent, particularly in tasks with complex dynamics or frequent disturbances. The authors also provide insights into the potential mechanisms behind this improved performance, such as the agent's ability to act upon imagination and better explore the state-action space.
Critical Analysis
While the proposed chaos-based RL approach shows promising results, there are some potential limitations and areas for further research:
-
The paper lacks a comprehensive analysis of the specific characteristics of the chaotic dynamics that lead to the observed performance improvements. A deeper understanding of the underlying mechanisms could help guide the design of more effective chaos-based exploration strategies.
-
The experiments are conducted on relatively simple continuous control tasks, and it's unclear how well the chaos-based method would scale to more complex real-world problems with high-dimensional state and action spaces.
-
The paper does not discuss the computational and sample efficiency of the chaos-based TD3 algorithm compared to the standard TD3 or other RL methods. This information would be crucial for evaluating the practical applicability of the proposed approach.
-
The authors do not address potential issues with the stability and convergence of the chaos-based RL algorithm, which could be a concern when deploying such systems in safety-critical applications.
Overall, the chaos-based RL approach presented in this paper is an intriguing idea that merits further investigation and refinement. Addressing the identified limitations and exploring the method's performance on a wider range of tasks could help strengthen the case for its practical usefulness in the field of reinforcement learning.
Conclusion
This paper introduces a novel chaos-based reinforcement learning method that combines the principles of chaos theory with the popular TD3 RL algorithm. The key idea is to introduce unpredictable, chaotic perturbations during the agent's exploration of the environment, which the authors claim can lead to improved learning performance and robustness.
The experimental results suggest that this chaos-based approach can outperform standard RL methods on several continuous control tasks, particularly those with complex dynamics or frequent disturbances. This has potential applications in areas like robotic control, where AI agents need to adapt to unpredictable real-world conditions.
While the paper presents a promising new direction for reinforcement learning research, there are still some open questions and limitations that warrant further investigation. Addressing these issues could help solidify the practical value of chaos-based RL and pave the way for its broader adoption in real-world AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Chaos-based reinforcement learning with TD3
Toshitaka Matsuki, Yusuke Sakemi, Kazuyuki Aihara
Chaos-based reinforcement learning (CBRL) is a method in which the agent's internal chaotic dynamics drives exploration. This approach offers a model for considering how the biological brain can create variability in its behavior and learn in an exploratory manner. At the same time, it is a learning model that has the ability to automatically switch between exploration and exploitation modes and the potential to realize higher explorations that reflect what it has learned so far. However, the learning algorithms in CBRL have not been well-established in previous studies and have yet to incorporate recent advances in reinforcement learning. This study introduced Twin Delayed Deep Deterministic Policy Gradients (TD3), which is one of the state-of-the-art deep reinforcement learning algorithms that can treat deterministic and continuous action spaces, to CBRL. The validation results provide several insights. First, TD3 works as a learning algorithm for CBRL in a simple goal-reaching task. Second, CBRL agents with TD3 can autonomously suppress their exploratory behavior as learning progresses and resume exploration when the environment changes. Finally, examining the effect of the agent's chaoticity on learning shows that extremely strong chaos negatively impacts the flexible switching between exploration and exploitation.
Read more5/16/2024
🛸
0
Optimizing TD3 for 7-DOF Robotic Arm Grasping: Overcoming Suboptimality with Exploration-Enhanced Contrastive Learning
Wen-Han Hsieh, Jen-Yuan Chang
In actor-critic-based reinforcement learning algorithms such as Twin Delayed Deep Deterministic policy gradient (TD3), insufficient exploration of the spatial space can result in suboptimal policies when controlling 7-DOF robotic arms. To address this issue, we propose a novel Exploration-Enhanced Contrastive Learning (EECL) module that improves exploration by providing additional rewards for encountering novel states. Our module stores previously explored states in a buffer and identifies new states by comparing them with historical data using Euclidean distance within a K-dimensional tree (KDTree) framework. When the agent explores new states, exploration rewards are assigned. These rewards are then integrated into the TD3 algorithm, ensuring that the Q-learning process incorporates these signals, promoting more effective strategy optimization. We evaluate our method on the robosuite panda lift task, demonstrating that it significantly outperforms the baseline TD3 in terms of both efficiency and convergence speed in the tested environment.
Read more8/27/2024

0
CTD4 - A Deep Continuous Distributional Actor-Critic Agent with a Kalman Fusion of Multiple Critics
David Valencia, Henry Williams, Trevor Gee, Bruce A MacDonald, Minas Liarokapis
Categorical Distributional Reinforcement Learning (CDRL) has demonstrated superior sample efficiency in learning complex tasks compared to conventional Reinforcement Learning (RL) approaches. However, the practical application of CDRL is encumbered by challenging projection steps, detailed parameter tuning, and domain knowledge. This paper addresses these challenges by introducing a pioneering Continuous Distributional Model-Free RL algorithm tailored for continuous action spaces. The proposed algorithm simplifies the implementation of distributional RL, adopting an actor-critic architecture wherein the critic outputs a continuous probability distribution. Additionally, we propose an ensemble of multiple critics fused through a Kalman fusion mechanism to mitigate overestimation bias. Through a series of experiments, we validate that our proposed method is easy to train and serves as a sample-efficient solution for executing complex continuous-control tasks.
Read more5/21/2024

0
Efficient Exploration in Deep Reinforcement Learning: A Novel Bayesian Actor-Critic Algorithm
Nikolai Rozanov
Reinforcement learning (RL) and Deep Reinforcement Learning (DRL), in particular, have the potential to disrupt and are already changing the way we interact with the world. One of the key indicators of their applicability is their ability to scale and work in real-world scenarios, that is in large-scale problems. This scale can be achieved via a combination of factors, the algorithm's ability to make use of large amounts of data and computational resources and the efficient exploration of the environment for viable solutions (i.e. policies). In this work, we investigate and motivate some theoretical foundations for deep reinforcement learning. We start with exact dynamic programming and work our way up to stochastic approximations and stochastic approximations for a model-free scenario, which forms the theoretical basis of modern reinforcement learning. We present an overview of this highly varied and rapidly changing field from the perspective of Approximate Dynamic Programming. We then focus our study on the short-comings with respect to exploration of the cornerstone approaches (i.e. DQN, DDQN, A2C) in deep reinforcement learning. On the theory side, our main contribution is the proposal of a novel Bayesian actor-critic algorithm. On the empirical side, we evaluate Bayesian exploration as well as actor-critic algorithms on standard benchmarks as well as state-of-the-art evaluation suites and show the benefits of both of these approaches over current state-of-the-art deep RL methods. We release all the implementations and provide a full python library that is easy to install and hopefully will serve the reinforcement learning community in a meaningful way, and provide a strong foundation for future work.
Read more8/20/2024