Optimizing TD3 for 7-DOF Robotic Arm Grasping: Overcoming Suboptimality with Exploration-Enhanced Contrastive Learning

0
🛸
Sign in to get full access
Overview
- Reinforcement learning algorithms like Twin Delayed Deep Deterministic policy gradient (TD3) can struggle with effectively exploring the spatial space when controlling 7-DOF robotic arms.
- This can lead to suboptimal policies being learned.
- The paper proposes a novel Exploration-Enhanced Contrastive Learning (EECL) module to address this issue.
Plain English Explanation
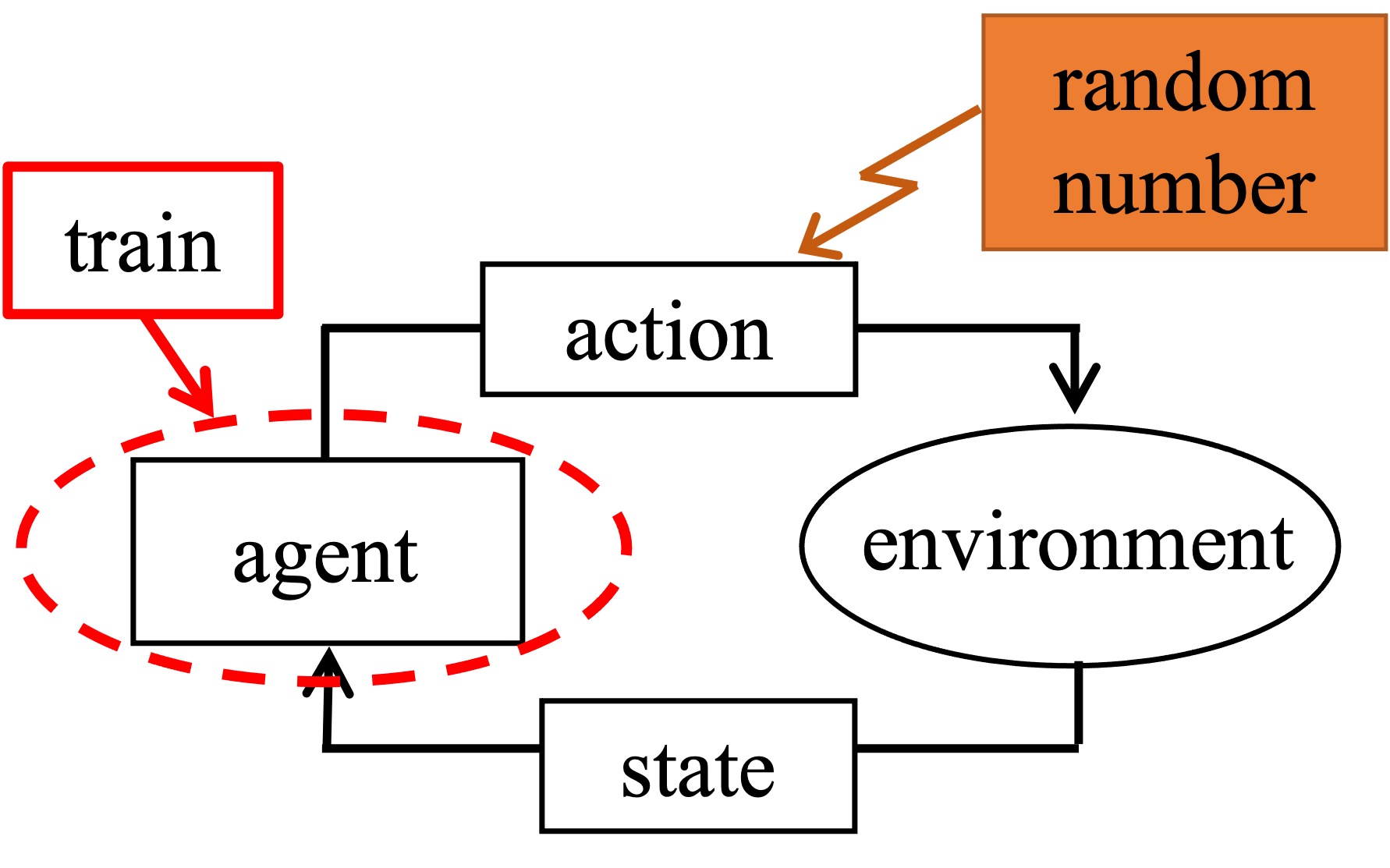
The paper discusses a problem that can arise when using actor-critic-based reinforcement learning algorithms like TD3 to control robotic arms with 7 degrees of freedom (7-DOF). These algorithms can struggle to effectively explore the full range of possible actions and states, which can result in the agent learning a suboptimal policy.
To solve this, the researchers developed a new module called Exploration-Enhanced Contrastive Learning (EECL). This module provides additional rewards to the agent when it encounters novel states that it hasn't seen before. It does this by keeping track of all the states the agent has explored in a buffer, and then using a K-dimensional tree (KDTree) to quickly identify when the agent is in a new, unexplored state. When the agent finds a new state, it gets a reward, which helps encourage the agent to keep exploring and finding better solutions.
This exploration-boosting approach is then integrated into the TD3 algorithm, so that the agent's Q-learning process takes these exploration rewards into account and learns a more effective strategy as a result.
The researchers evaluated this method on a robotic panda lift task and found that it significantly outperformed the standard TD3 algorithm in terms of both efficiency and speed of convergence.
Technical Explanation
The key technical components of the proposed Exploration-Enhanced Contrastive Learning (EECL) module are:
-
State Buffer: The module maintains a buffer of previously encountered states to track the agent's exploration history.
-
KDTree: A K-dimensional tree (KDTree) data structure is used to efficiently store and query the state buffer. This allows for quick identification of novel states.
-
Exploration Rewards: When the agent encounters a state that is sufficiently distant (in Euclidean space) from the states in the buffer, it is considered a novel state and is rewarded accordingly. These exploration rewards are then integrated into the TD3 algorithm's Q-learning process.
The key insight is that by providing additional rewards for exploring new states, the agent is incentivized to more thoroughly investigate the state space, leading to the discovery of more optimal policies, especially when controlling complex 7-DOF robotic arms.
Critical Analysis
The paper presents a well-designed and thoughtful approach to address the exploration challenges faced by actor-critic-based reinforcement learning algorithms when controlling high-dimensional robotic systems. However, a few potential areas for further investigation are:
-
Generalizability: The evaluation is limited to a single robotic task (panda lift). It would be valuable to assess the EECL module's performance on a wider range of robotic manipulation tasks to better understand its general applicability.
-
Computational Overhead: Maintaining the state buffer and querying the KDTree structure may introduce additional computational overhead compared to the baseline TD3 algorithm. The impact of this overhead on real-time performance should be carefully evaluated.
-
Hyper-parameter Sensitivity: The effectiveness of the EECL module likely depends on the careful tuning of several hyper-parameters, such as the exploration reward magnitude and the KDTree distance threshold. The paper could have provided more insights into the sensitivity of the approach to these parameters.
Conclusion
The Exploration-Enhanced Contrastive Learning (EECL) module proposed in this paper presents a promising approach to enhance the exploration capabilities of actor-critic-based reinforcement learning algorithms, particularly when controlling complex 7-DOF robotic arms. By providing additional rewards for encountering novel states, the EECL module helps the agent learn more effective control policies, as demonstrated by the significant performance improvements over the baseline TD3 algorithm. Further research to evaluate the broader applicability and optimize the computational efficiency of this approach could lead to valuable advancements in the field of robotic manipulation and control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Optimizing TD3 for 7-DOF Robotic Arm Grasping: Overcoming Suboptimality with Exploration-Enhanced Contrastive Learning
Wen-Han Hsieh, Jen-Yuan Chang
In actor-critic-based reinforcement learning algorithms such as Twin Delayed Deep Deterministic policy gradient (TD3), insufficient exploration of the spatial space can result in suboptimal policies when controlling 7-DOF robotic arms. To address this issue, we propose a novel Exploration-Enhanced Contrastive Learning (EECL) module that improves exploration by providing additional rewards for encountering novel states. Our module stores previously explored states in a buffer and identifies new states by comparing them with historical data using Euclidean distance within a K-dimensional tree (KDTree) framework. When the agent explores new states, exploration rewards are assigned. These rewards are then integrated into the TD3 algorithm, ensuring that the Q-learning process incorporates these signals, promoting more effective strategy optimization. We evaluate our method on the robosuite panda lift task, demonstrating that it significantly outperforms the baseline TD3 in terms of both efficiency and convergence speed in the tested environment.
Read more8/27/2024
0
Chaos-based reinforcement learning with TD3
Toshitaka Matsuki, Yusuke Sakemi, Kazuyuki Aihara
Chaos-based reinforcement learning (CBRL) is a method in which the agent's internal chaotic dynamics drives exploration. This approach offers a model for considering how the biological brain can create variability in its behavior and learn in an exploratory manner. At the same time, it is a learning model that has the ability to automatically switch between exploration and exploitation modes and the potential to realize higher explorations that reflect what it has learned so far. However, the learning algorithms in CBRL have not been well-established in previous studies and have yet to incorporate recent advances in reinforcement learning. This study introduced Twin Delayed Deep Deterministic Policy Gradients (TD3), which is one of the state-of-the-art deep reinforcement learning algorithms that can treat deterministic and continuous action spaces, to CBRL. The validation results provide several insights. First, TD3 works as a learning algorithm for CBRL in a simple goal-reaching task. Second, CBRL agents with TD3 can autonomously suppress their exploratory behavior as learning progresses and resume exploration when the environment changes. Finally, examining the effect of the agent's chaoticity on learning shows that extremely strong chaos negatively impacts the flexible switching between exploration and exploitation.
Read more5/16/2024

0
Robotic Arm Manipulation with Inverse Reinforcement Learning & TD-MPC
Md Shoyib Hassan (North South University), Sabir Md Sanaullah (North South University)
One unresolved issue is how to scale model-based inverse reinforcement learning (IRL) to actual robotic manipulation tasks with unpredictable dynamics. The ability to learn from both visual and proprioceptive examples, creating algorithms that scale to high-dimensional state-spaces, and mastering strong dynamics models are the main obstacles. In this work, we provide a gradient-based inverse reinforcement learning framework that learns cost functions purely from visual human demonstrations. The shown behavior and the trajectory is then optimized using TD visual model predictive control(MPC) and the learned cost functions. We test our system using fundamental object manipulation tasks on hardware.
Read more8/9/2024
📉
0
TD3 Based Collision Free Motion Planning for Robot Navigation
Hao Liu, Yi Shen, Chang Zhou, Yuelin Zou, Zijun Gao, Qi Wang
This paper addresses the challenge of collision-free motion planning in automated navigation within complex environments. Utilizing advancements in Deep Reinforcement Learning (DRL) and sensor technologies like LiDAR, we propose the TD3-DWA algorithm, an innovative fusion of the traditional Dynamic Window Approach (DWA) with the Twin Delayed Deep Deterministic Policy Gradient (TD3). This hybrid algorithm enhances the efficiency of robotic path planning by optimizing the sampling interval parameters of DWA to effectively navigate around both static and dynamic obstacles. The performance of the TD3-DWA algorithm is validated through various simulation experiments, demonstrating its potential to significantly improve the reliability and safety of autonomous navigation systems.
Read more5/27/2024