Character-Level Chinese Dependency Parsing via Modeling Latent Intra-Word Structure

0
🤿
Sign in to get full access
Overview
- This paper addresses the challenge of parsing Chinese sentences, which lack clear word boundaries, by modeling the latent internal structures within words.
- The proposed approach interprets each word-level dependency tree as a forest of character-level trees, enabling a transition from word-level to character-level Chinese dependency parsing.
- The constrained Eisner algorithm is used to ensure the compatibility of character-level trees, guaranteeing a single root for intra-word structures and establishing inter-word dependencies between these roots.
- Experiments on Chinese treebanks demonstrate the superiority of this method over both the pipeline framework and previous joint models.
- The paper also reveals that a coarse-to-fine parsing strategy empowers the model to predict more linguistically plausible intra-word structures.
Plain English Explanation
Chinese is a language where it can be challenging to identify the boundaries between words, making it difficult for word-level parsing models to accurately understand the structure of sentences. To address this, the researchers in this paper propose a new approach that looks at the internal structure within each word, rather than just treating words as single units.
Their method interprets each word-level dependency tree (a diagram showing how the words in a sentence are related to each other) as a collection of smaller trees representing the structure within each individual word. This allows the model to capture more nuanced relationships between the characters that make up each word.
To ensure these character-level trees are compatible and form a coherent overall structure, the researchers implement a specialized algorithm called the constrained Eisner algorithm. This algorithm guarantees that each word has a single root character and that the connections between the words are properly established.
When tested on Chinese language datasets, this approach outperformed both the traditional pipeline framework (where word segmentation and parsing are done separately) and previous models that tried to jointly model word and character-level information. The analysis also showed that the model's ability to predict the internal structure of words became more linguistically plausible when using a coarse-to-fine parsing strategy (starting with a high-level view and then refining the details).
Technical Explanation
The paper proposes a novel approach to modeling latent internal structures within words for character-level Chinese dependency parsing. This addresses the significant challenges posed by the absence of clear word boundaries in Chinese for word-level parsers.
The key idea is to interpret each word-level dependency tree as a forest of character-level trees, enabling a transition from word-level to character-level parsing. To ensure the compatibility of these character-level trees, a constrained Eisner algorithm is implemented. This algorithm guarantees a single root for intra-word structures and establishes inter-word dependencies between these roots.
Experiments on Chinese treebanks demonstrate the superiority of this method over both the pipeline framework (where word segmentation and parsing are performed separately) and previous joint models. A detailed analysis reveals that a coarse-to-fine parsing strategy empowers the model to predict more linguistically plausible intra-word structures.
Critical Analysis
The paper presents a compelling approach to addressing the challenges of Chinese dependency parsing, but it would be valuable to further explore the limitations and potential issues with the proposed method.
While the experiments demonstrate the method's superiority over existing approaches, it would be helpful to understand the specific types of sentences or linguistic phenomena where the character-level parsing excels or falls short compared to word-level parsing. Examining the error patterns and qualitative examples could provide valuable insights.
Additionally, the paper does not discuss the computational complexity or runtime performance of the constrained Eisner algorithm. As parsing large-scale corpora is an important practical consideration, understanding the scalability and efficiency of the proposed approach would be valuable.
It would also be interesting to see how the method performs on other languages with complex morphology or ambiguous word boundaries, such as Arabic or Vietnamese. Exploring the generalizability of the approach could further demonstrate its broader applicability.
Conclusion
This paper presents a novel approach to Chinese dependency parsing that models the latent internal structures within words, addressing the challenges posed by the absence of clear word boundaries in the Chinese language. By interpreting each word-level dependency tree as a forest of character-level trees and using a constrained Eisner algorithm to ensure compatibility, the proposed method outperforms both the pipeline framework and previous joint models.
The key innovation of this work is its ability to capture more nuanced linguistic relationships at the character level, which is particularly valuable for languages like Chinese. The findings suggest that a coarse-to-fine parsing strategy can lead to more plausible predictions of intra-word structures, opening up opportunities for further refinement and application of this technique.
Overall, this research represents an important step forward in the field of character-level parsing and has the potential to inspire similar approaches for other languages with complex morphological structures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Character-Level Chinese Dependency Parsing via Modeling Latent Intra-Word Structure
Yang Hou, Zhenghua Li
Revealing the syntactic structure of sentences in Chinese poses significant challenges for word-level parsers due to the absence of clear word boundaries. To facilitate a transition from word-level to character-level Chinese dependency parsing, this paper proposes modeling latent internal structures within words. In this way, each word-level dependency tree is interpreted as a forest of character-level trees. A constrained Eisner algorithm is implemented to ensure the compatibility of character-level trees, guaranteeing a single root for intra-word structures and establishing inter-word dependencies between these roots. Experiments on Chinese treebanks demonstrate the superiority of our method over both the pipeline framework and previous joint models. A detailed analysis reveals that a coarse-to-fine parsing strategy empowers the model to predict more linguistically plausible intra-word structures.
Read more6/7/2024
🌿
0
Revisiting Structured Sentiment Analysis as Latent Dependency Graph Parsing
Chengjie Zhou, Bobo Li, Hao Fei, Fei Li, Chong Teng, Donghong Ji
Structured Sentiment Analysis (SSA) was cast as a problem of bi-lexical dependency graph parsing by prior studies. Multiple formulations have been proposed to construct the graph, which share several intrinsic drawbacks: (1) The internal structures of spans are neglected, thus only the boundary tokens of spans are used for relation prediction and span recognition, thus hindering the model's expressiveness; (2) Long spans occupy a significant proportion in the SSA datasets, which further exacerbates the problem of internal structure neglect. In this paper, we treat the SSA task as a dependency parsing task on partially-observed dependency trees, regarding flat spans without determined tree annotations as latent subtrees to consider internal structures of spans. We propose a two-stage parsing method and leverage TreeCRFs with a novel constrained inside algorithm to model latent structures explicitly, which also takes advantages of joint scoring graph arcs and headed spans for global optimization and inference. Results of extensive experiments on five benchmark datasets reveal that our method performs significantly better than all previous bi-lexical methods, achieving new state-of-the-art.
Read more7/9/2024
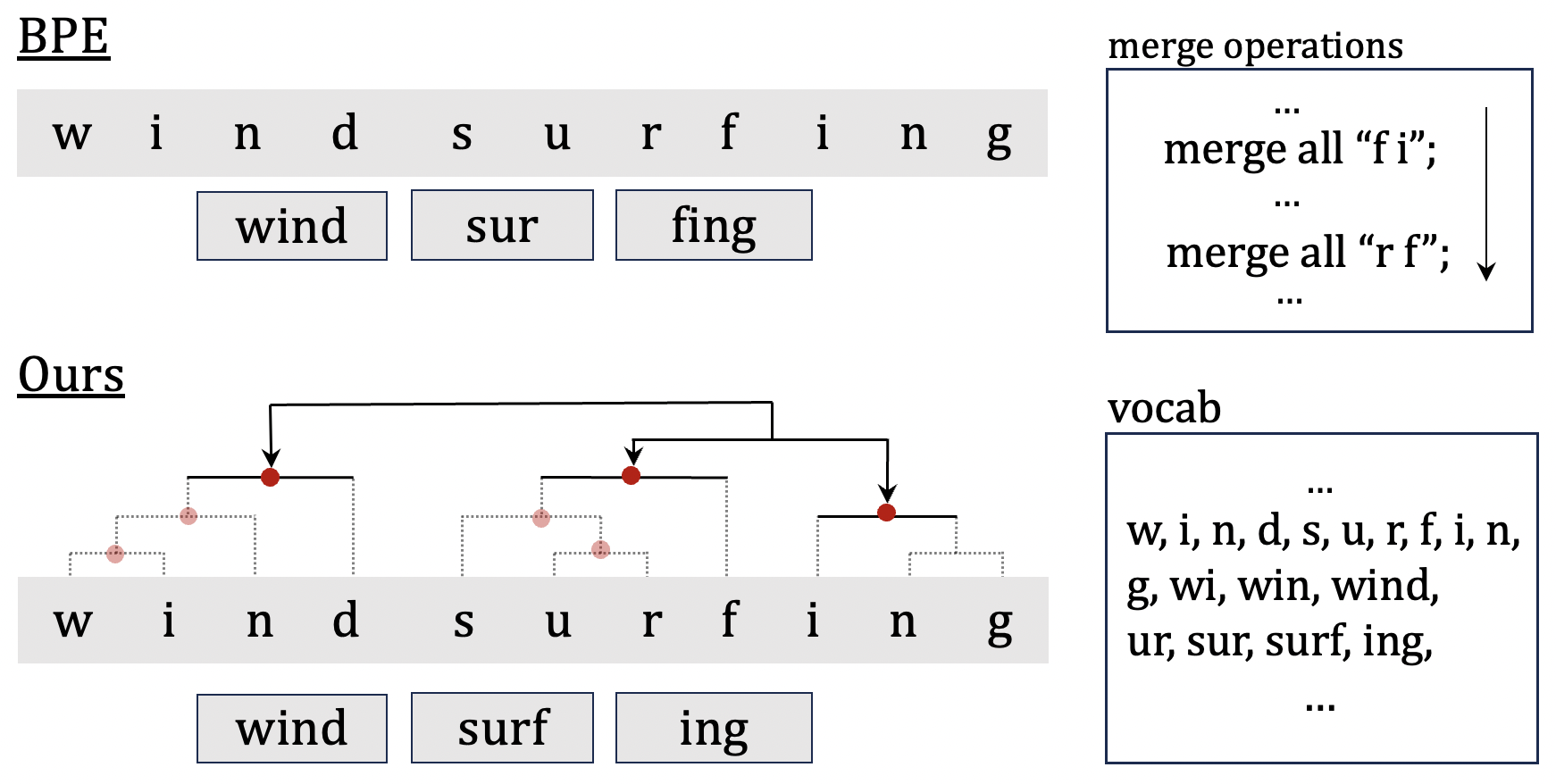
0
Unsupervised Morphological Tree Tokenizer
Qingyang Zhu, Xiang Hu, Pengyu Ji, Wei Wu, Kewei Tu
As a cornerstone in language modeling, tokenization involves segmenting text inputs into pre-defined atomic units. Conventional statistical tokenizers often disrupt constituent boundaries within words, thereby corrupting semantic information. To address this drawback, we introduce morphological structure guidance to tokenization and propose a deep model to induce character-level structures of words. Specifically, the deep model jointly encodes internal structures and representations of words with a mechanism named $textit{MorphOverriding}$ to ensure the indecomposability of morphemes. By training the model with self-supervised objectives, our method is capable of inducing character-level structures that align with morphological rules without annotated training data. Based on the induced structures, our algorithm tokenizes words through vocabulary matching in a top-down manner. Empirical results indicate that the proposed method effectively retains complete morphemes and outperforms widely adopted methods such as BPE and WordPiece on both morphological segmentation tasks and language modeling tasks. The code will be released later.
Read more6/24/2024
💬
0
Active Use of Latent Constituency Representation in both Humans and Large Language Models
Wei Liu, Ming Xiang, Nai Ding
Understanding how sentences are internally represented in the human brain, as well as in large language models (LLMs) such as ChatGPT, is a major challenge for cognitive science. Classic linguistic theories propose that the brain represents a sentence by parsing it into hierarchically organized constituents. In contrast, LLMs do not explicitly parse linguistic constituents and their latent representations remains poorly explained. Here, we demonstrate that humans and LLMs construct similar latent representations of hierarchical linguistic constituents by analyzing their behaviors during a novel one-shot learning task, in which they infer which words should be deleted from a sentence. Both humans and LLMs tend to delete a constituent, instead of a nonconstituent word string. In contrast, a naive sequence processing model that has access to word properties and ordinal positions does not show this property. Based on the word deletion behaviors, we can reconstruct the latent constituency tree representation of a sentence for both humans and LLMs. These results demonstrate that a latent tree-structured constituency representation can emerge in both the human brain and LLMs.
Read more5/29/2024