Characterizing Dynamical Stability of Stochastic Gradient Descent in Overparameterized Learning

0
🤷
Sign in to get full access
Overview
- Examines the dynamical stability of Stochastic Gradient Descent (SGD) in overparameterized learning settings
- Provides a theoretical analysis of SGD's convergence and stability properties
- Highlights the role of initialization and step size in determining the convergence and stability of SGD
Plain English Explanation
This research paper explores the stability and convergence properties of Stochastic Gradient Descent (SGD), a widely used optimization algorithm, in the context of overparameterized learning. Overparameterized learning refers to a scenario where the number of model parameters exceeds the number of training examples, which is common in modern machine learning applications.
The researchers analyze the dynamics of SGD, focusing on how the algorithm's behavior is influenced by the initialization of the model parameters and the choice of step size (or learning rate). They provide a theoretical framework to understand the stability and convergence characteristics of SGD in these overparameterized settings.
The key insights from this paper are:
- Initialization and step size play a crucial role in determining the stability and convergence of SGD. Certain combinations of initialization and step size can lead to stable and convergent behavior, while others may result in unstable or divergent trajectories.
- The dynamics of SGD can be understood from a Lyapunov-based perspective, which provides insights into the conditions for stable and convergent behavior.
- The stochastic nature of SGD, captured by the gradient noise, has a significant impact on the algorithm's stability and convergence properties.
By analyzing these aspects, the researchers aim to enhance our understanding of the behavior of SGD in overparameterized learning scenarios, which can inform the design of more robust and efficient optimization algorithms.
Technical Explanation
The paper presents a theoretical analysis of the dynamical stability of Stochastic Gradient Descent (SGD) in overparameterized learning settings. The researchers develop a framework to study the convergence and stability properties of SGD, focusing on the role of initialization and step size.
The key technical contributions of the paper include:
-
Theoretical analysis of SGD's convergence and stability: The authors provide a detailed mathematical analysis of the dynamics of SGD, leveraging tools from the field of dynamical systems theory. They characterize the conditions under which SGD exhibits stable and convergent behavior.
-
Characterization of the impact of initialization and step size: The researchers investigate how the choice of initialization and step size affects the stability and convergence of SGD. They identify the parameter regimes where SGD is expected to converge and those where it may exhibit unstable or divergent behavior.
-
Incorporation of gradient noise in the analysis: The stochastic nature of SGD, captured by the gradient noise, is a crucial aspect of the analysis. The researchers study how the gradient noise influences the stability and convergence properties of the algorithm.
-
Lyapunov-based perspective on SGD dynamics: The authors adopt a Lyapunov-based approach to analyze the stability of SGD, which provides insights into the conditions for stable and convergent behavior.
Through this comprehensive theoretical framework, the paper advances our understanding of the dynamical properties of SGD in overparameterized learning scenarios. The insights gained can inform the design of more robust and efficient optimization algorithms for complex machine learning tasks.
Critical Analysis
The paper provides a rigorous theoretical analysis of the dynamical stability of Stochastic Gradient Descent (SGD) in overparameterized learning settings. The researchers' focus on the role of initialization and step size is particularly insightful, as these parameters are known to have a significant impact on the performance of SGD in practice.
One potential limitation of the study is the reliance on certain simplifying assumptions, such as the use of a quadratic loss function and Gaussian gradient noise. While these assumptions allow for a more tractable mathematical analysis, they may not fully capture the complexity of real-world machine learning problems, where the loss function and noise distributions can be more complex.
Additionally, the paper does not address the impact of other factors, such as the network architecture or the data distribution, on the stability and convergence of SGD. Extending the analysis to incorporate these aspects could provide a more comprehensive understanding of the behavior of SGD in overparameterized learning.
Furthermore, the theoretical results presented in the paper could be complemented by empirical studies to validate the predictions and explore the practical implications of the findings. Bridging the gap between the theoretical analysis and the empirical performance of SGD would further strengthen the contributions of this work.
Despite these potential limitations, the paper represents a significant contribution to the understanding of optimization algorithms in the context of overparameterized learning. The insights provided can inform the development of more robust and efficient optimization techniques for a wide range of machine learning applications.
Conclusion
This research paper presents a theoretical analysis of the dynamical stability of Stochastic Gradient Descent (SGD) in overparameterized learning settings. The key findings highlight the crucial role of initialization and step size in determining the convergence and stability properties of SGD.
The researchers provide a comprehensive framework to study the dynamics of SGD, incorporating the impact of gradient noise and adopting a Lyapunov-based perspective. These insights can inform the design of more robust and efficient optimization algorithms for complex machine learning tasks, where overparameterization is a common challenge.
While the paper relies on certain simplifying assumptions, the theoretical analysis offers valuable contributions to the understanding of optimization algorithms in overparameterized learning scenarios. Future work could explore the practical implications of these findings and expand the analysis to incorporate additional factors influencing the behavior of SGD.
Overall, this research represents an important step in characterizing the dynamical stability of Stochastic Gradient Descent, a widely used optimization technique in the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Characterizing Dynamical Stability of Stochastic Gradient Descent in Overparameterized Learning
Dennis Chemnitz, Maximilian Engel
For overparameterized optimization tasks, such as the ones found in modern machine learning, global minima are generally not unique. In order to understand generalization in these settings, it is vital to study to which minimum an optimization algorithm converges. The possibility of having minima that are unstable under the dynamics imposed by the optimization algorithm limits the potential minima that the algorithm can find. In this paper, we characterize the global minima that are dynamically stable/unstable for both deterministic and stochastic gradient descent (SGD). In particular, we introduce a characteristic Lyapunov exponent which depends on the local dynamics around a global minimum and rigorously prove that the sign of this Lyapunov exponent determines whether SGD can accumulate at the respective global minimum.
Read more7/30/2024

0
Exact Mean Square Linear Stability Analysis for SGD
Rotem Mulayoff, Tomer Michaeli
The dynamical stability of optimization methods at the vicinity of minima of the loss has recently attracted significant attention. For gradient descent (GD), stable convergence is possible only to minima that are sufficiently flat w.r.t. the step size, and those have been linked with favorable properties of the trained model. However, while the stability threshold of GD is well-known, to date, no explicit expression has been derived for the exact threshold of stochastic GD (SGD). In this paper, we derive such a closed-form expression. Specifically, we provide an explicit condition on the step size that is both necessary and sufficient for the linear stability of SGD in the mean square sense. Our analysis sheds light on the precise role of the batch size $B$. In particular, we show that the stability threshold is monotonically non-decreasing in the batch size, which means that reducing the batch size can only decrease stability. Furthermore, we show that SGD's stability threshold is equivalent to that of a mixture process which takes in each iteration a full batch gradient step w.p. $1-p$, and a single sample gradient step w.p. $p$, where $p approx 1/B $. This indicates that even with moderate batch sizes, SGD's stability threshold is very close to that of GD's. We also prove simple necessary conditions for linear stability, which depend on the batch size, and are easier to compute than the precise threshold. Finally, we derive the asymptotic covariance of the dynamics around the minimum, and discuss its dependence on the learning rate. We validate our theoretical findings through experiments on the MNIST dataset.
Read more6/18/2024
🛠️
0
Langevin Dynamics: A Unified Perspective on Optimization via Lyapunov Potentials
August Y. Chen, Ayush Sekhari, Karthik Sridharan
We study the problem of non-convex optimization using Stochastic Gradient Langevin Dynamics (SGLD). SGLD is a natural and popular variation of stochastic gradient descent where at each step, appropriately scaled Gaussian noise is added. To our knowledge, the only strategy for showing global convergence of SGLD on the loss function is to show that SGLD can sample from a stationary distribution which assigns larger mass when the function is small (the Gibbs measure), and then to convert these guarantees to optimization results. We employ a new strategy to analyze the convergence of SGLD to global minima, based on Lyapunov potentials and optimization. We convert the same mild conditions from previous works on SGLD into geometric properties based on Lyapunov potentials. This adapts well to the case with a stochastic gradient oracle, which is natural for machine learning applications where one wants to minimize population loss but only has access to stochastic gradients via minibatch training samples. Here we provide 1) improved rates in the setting of previous works studying SGLD for optimization, 2) the first finite gradient complexity guarantee for SGLD where the function is Lipschitz and the Gibbs measure defined by the function satisfies a Poincar'e Inequality, and 3) prove if continuous-time Langevin Dynamics succeeds for optimization, then discrete-time SGLD succeeds under mild regularity assumptions.
Read more7/8/2024
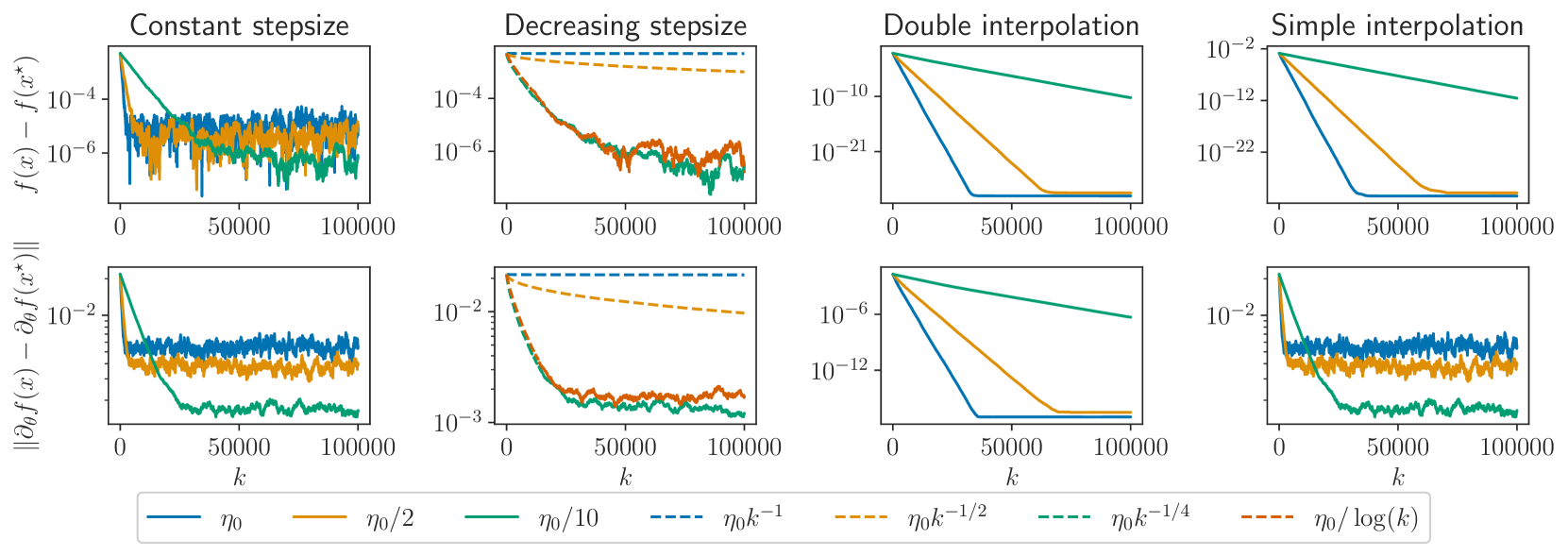
0
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
Read more5/28/2024