Exact Mean Square Linear Stability Analysis for SGD

0

Sign in to get full access
Overview
- This paper presents a theoretical analysis of the stability of Stochastic Gradient Descent (SGD), a widely used optimization algorithm in machine learning.
- The authors provide an exact mean square linear stability analysis of SGD, which offers insights into how the algorithm behaves near the minima of the loss function.
- The analysis considers the impact of various factors, such as the choice of step size, the noise in the gradients, and the geometry of the optimization landscape.
Plain English Explanation
Stochastic Gradient Descent (SGD) is a powerful optimization algorithm used extensively in machine learning to train models. It works by gradually adjusting the model's parameters, or "knobs," to minimize a loss function that quantifies how well the model is performing.
The authors of this paper wanted to understand how stable SGD is when it's operating near the minimum of the loss function, where the model has been optimized to perform well. They provided a detailed mathematical analysis to precisely describe the algorithm's behavior in this critical region.
Their analysis looked at factors like the step size (how much the algorithm updates the parameters at each iteration), the noise in the gradients (the estimates of the slope of the loss function that guide the updates), and the shape of the loss function itself. By understanding how these elements influence the stability of SGD, the researchers can offer guidance on how to configure the algorithm for optimal performance.
For example, the step size needs to be small enough to ensure that the algorithm doesn't overshoot the minimum, but not so small that it takes too long to converge. The noise in the gradients can also impact stability, so the researchers explored how different sources of noise affect the algorithm's behavior.
Overall, this detailed theoretical analysis provides valuable insights into the inner workings of SGD and how it behaves near the optimum of the loss function. This knowledge can help machine learning practitioners better understand the strengths and limitations of this widely used optimization technique.
Technical Explanation
The authors provide an exact mean square linear stability analysis of Stochastic Gradient Descent (SGD), building on previous work that has explored the dynamics of mini-batch gradient descent and the behavior of stochastic gradients.
Their analysis considers the stability of SGD near the minimum of the loss function, where the algorithm has converged to an optimal set of model parameters. The authors examine how various factors, such as the step size, the noise in the gradients, and the geometry of the optimization landscape, impact the stability of SGD in this critical region.
The key technical elements of the paper include:
-
Mean Square Linear Stability Analysis: The authors derive an exact expression for the mean square error dynamics of SGD near the minimum of the loss function. This allows them to precisely characterize the stability of the algorithm in this region.
-
Noise Decomposition: The authors decompose the noise in the stochastic gradients into different components, such as the variance of the gradients and the bias in the gradients. This enables them to understand how each source of noise affects the stability of SGD.
-
Optimization Landscape Geometry: The authors consider how the curvature and sharpness of the loss function, as described by the Hessian matrix, impact the stability of SGD. This builds on related research on sharpness-aware minimization and conservative sharpening.
-
Step Size Selection: The authors provide guidance on how to choose the step size for SGD to ensure stable convergence near the minimum of the loss function, taking into account the various factors they have analyzed.
By offering a detailed theoretical analysis of SGD's stability near the minimum, the authors contribute to the growing body of research on the convergence properties of stochastic optimization algorithms.
Critical Analysis
The authors provide a comprehensive theoretical analysis of the stability of Stochastic Gradient Descent (SGD) near the minimum of the loss function. Their work builds on and extends previous research in this area, offering a deeper understanding of how various factors, such as noise and optimization landscape geometry, impact the behavior of the algorithm.
One potential limitation of the study is that it focuses solely on the stability of SGD near the minimum and does not consider the algorithm's behavior during the earlier stages of optimization, when it is still converging towards the minimum. It would be valuable to understand how the insights from this analysis apply to the broader trajectory of the optimization process.
Additionally, the authors' analysis is based on a linear approximation of the loss function near the minimum. While this approach provides tractable mathematical results, it may not fully capture the nonlinear dynamics that can arise in more complex optimization landscapes. Extending the analysis to account for nonlinear effects could yield additional insights.
Furthermore, the paper does not provide empirical validation of the theoretical findings. Experimental studies that compare the predicted stability behavior with the actual performance of SGD in real-world settings would help to substantiate the authors' claims and provide a more holistic understanding of the algorithm's capabilities and limitations.
Overall, this paper represents a significant contribution to the understanding of Stochastic Gradient Descent and its stability properties. The authors' rigorous theoretical analysis lays the groundwork for further research and practical applications in the field of machine learning and optimization.
Conclusion
This paper presents a detailed theoretical analysis of the stability of Stochastic Gradient Descent (SGD) near the minimum of the loss function. The authors derive an exact expression for the mean square error dynamics of SGD and explore how various factors, such as noise, step size, and optimization landscape geometry, impact the algorithm's stability in this critical region.
The insights from this analysis can help machine learning practitioners better understand the behavior of SGD and make more informed decisions when configuring the algorithm for their specific applications. By shedding light on the interplay between the different elements that influence SGD's stability, the authors contribute to the ongoing research on the convergence properties of stochastic optimization algorithms.
While the paper focuses on the stability near the minimum, future work could explore the algorithm's behavior during the broader optimization process. Additionally, empirical validation of the theoretical findings would strengthen the practical relevance of this research. Nevertheless, this study represents an important step forward in the understanding of one of the most widely used optimization techniques in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exact Mean Square Linear Stability Analysis for SGD
Rotem Mulayoff, Tomer Michaeli
The dynamical stability of optimization methods at the vicinity of minima of the loss has recently attracted significant attention. For gradient descent (GD), stable convergence is possible only to minima that are sufficiently flat w.r.t. the step size, and those have been linked with favorable properties of the trained model. However, while the stability threshold of GD is well-known, to date, no explicit expression has been derived for the exact threshold of stochastic GD (SGD). In this paper, we derive such a closed-form expression. Specifically, we provide an explicit condition on the step size that is both necessary and sufficient for the linear stability of SGD in the mean square sense. Our analysis sheds light on the precise role of the batch size $B$. In particular, we show that the stability threshold is monotonically non-decreasing in the batch size, which means that reducing the batch size can only decrease stability. Furthermore, we show that SGD's stability threshold is equivalent to that of a mixture process which takes in each iteration a full batch gradient step w.p. $1-p$, and a single sample gradient step w.p. $p$, where $p approx 1/B $. This indicates that even with moderate batch sizes, SGD's stability threshold is very close to that of GD's. We also prove simple necessary conditions for linear stability, which depend on the batch size, and are easier to compute than the precise threshold. Finally, we derive the asymptotic covariance of the dynamics around the minimum, and discuss its dependence on the learning rate. We validate our theoretical findings through experiments on the MNIST dataset.
Read more6/18/2024
🤷
0
Characterizing Dynamical Stability of Stochastic Gradient Descent in Overparameterized Learning
Dennis Chemnitz, Maximilian Engel
For overparameterized optimization tasks, such as the ones found in modern machine learning, global minima are generally not unique. In order to understand generalization in these settings, it is vital to study to which minimum an optimization algorithm converges. The possibility of having minima that are unstable under the dynamics imposed by the optimization algorithm limits the potential minima that the algorithm can find. In this paper, we characterize the global minima that are dynamically stable/unstable for both deterministic and stochastic gradient descent (SGD). In particular, we introduce a characteristic Lyapunov exponent which depends on the local dynamics around a global minimum and rigorously prove that the sign of this Lyapunov exponent determines whether SGD can accumulate at the respective global minimum.
Read more7/30/2024
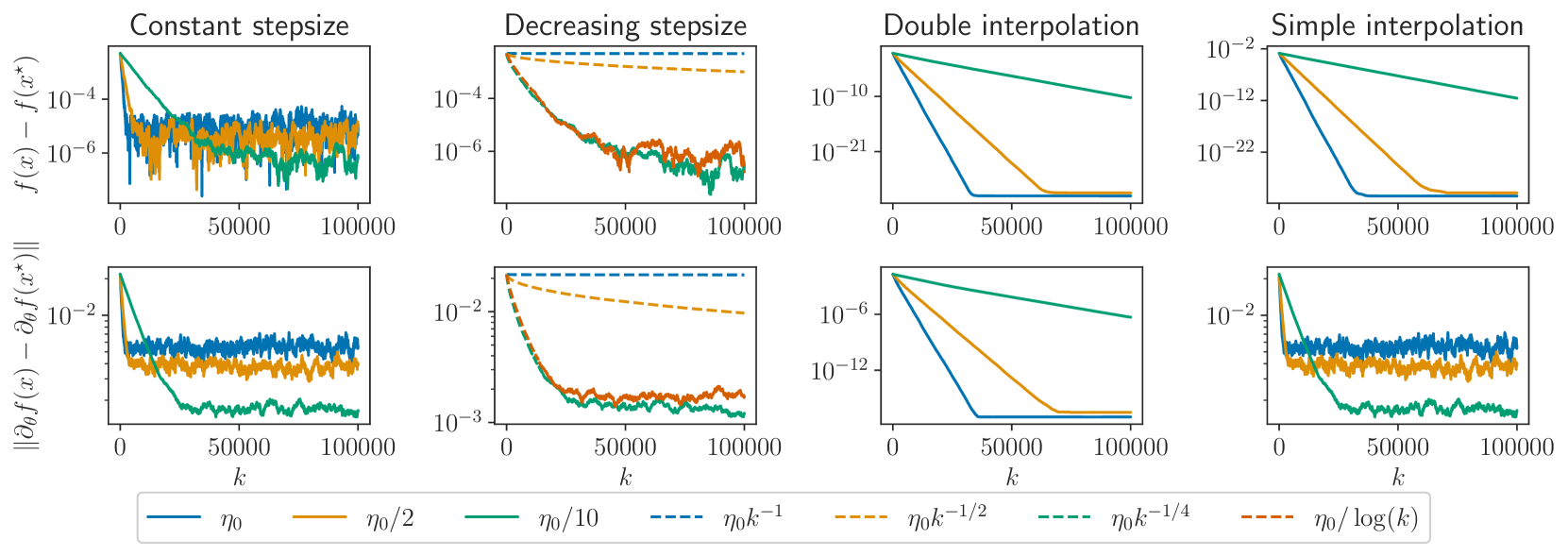
0
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
Read more5/28/2024

0
Bootstrap SGD: Algorithmic Stability and Robustness
Andreas Christmann, Yunwen Lei
In this paper some methods to use the empirical bootstrap approach for stochastic gradient descent (SGD) to minimize the empirical risk over a separable Hilbert space are investigated from the view point of algorithmic stability and statistical robustness. The first two types of approaches are based on averages and are investigated from a theoretical point of view. A generalization analysis for bootstrap SGD of Type 1 and Type 2 based on algorithmic stability is done. Another type of bootstrap SGD is proposed to demonstrate that it is possible to construct purely distribution-free pointwise confidence intervals of the median curve using bootstrap SGD.
Read more9/4/2024