ChatIE: Zero-Shot Information Extraction via Chatting with ChatGPT

0
⛏️
Sign in to get full access
Overview
- The paper explores zero-shot information extraction (IE) using large language models (LLMs) like GPT-3 and ChatGPT.
- Zero-shot IE aims to build IE systems without human-annotated data, which can reduce the time and effort needed for data labeling.
- The authors propose a two-stage framework called ChatIE that transforms zero-shot IE into a multi-turn question-answering problem.
- ChatIE is evaluated on three IE tasks: entity-relation extraction, named entity recognition, and event extraction.
- The results show ChatIE achieves impressive performance, even surpassing some full-shot models on certain datasets.
Plain English Explanation
Information extraction (IE) is the process of automatically extracting structured data (like entities, relationships, and events) from unstructured text. Traditionally, building IE systems requires a lot of human effort to label training data. This can be time-consuming and costly.
The concept of "zero-shot" IE aims to address this by developing IE models that can work without any labeled data. The idea is to use the capabilities of large language models (LLMs) like GPT-3 and ChatGPT to extract information directly from plain text.
In this paper, the authors propose a two-stage framework called ChatIE that turns zero-shot IE into a multi-step question-answering task. First, they prompt the LLM to identify relevant entities, relations, and events in the text. Then, they ask follow-up questions to extract the specific details about those elements.
The researchers evaluate ChatIE on three different IE tasks across six datasets in two languages. The results show that their approach can achieve impressive performance, often matching or even exceeding the accuracy of traditional IE models that are trained on labeled data.
This work suggests that zero-shot IE using powerful language models like ChatGPT could be a promising way to build information extraction systems with much less manual effort. It could make IE technology more accessible, especially in domains where labeled data is scarce.
Technical Explanation
The key idea behind the authors' approach is to transform the zero-shot IE task into a multi-turn question-answering problem that can be solved by prompting a large language model like ChatGPT.
Their two-stage ChatIE framework works as follows:
- Prompt Generation: Given an input text, the authors generate a series of prompts that ask the LLM to identify relevant entities, relations, and events.
- Information Extraction: Based on the LLM's responses, ChatIE then asks follow-up questions to extract the specific details about the identified elements.
The authors evaluate ChatIE on three common IE tasks: entity-relation triple extraction, named entity recognition, and event extraction. They test it on six datasets across two languages (English and Chinese).
The results show that ChatIE can achieve strong performance, often beating fully-supervised IE models on several datasets. For example, on the NYT11-HRL dataset, ChatIE surpassed a full-shot model in entity-relation extraction.
These findings suggest that zero-shot IE approaches leveraging powerful language models could be a viable alternative to traditional IE systems, especially in data-scarce scenarios. The authors believe this work could inspire further research on building IE models with limited resources.
Critical Analysis
One key limitation of the ChatIE framework is that it relies heavily on the language model's ability to accurately interpret the prompts and generate relevant responses. If the prompts are not designed well or the LLM makes mistakes, the overall extraction performance could suffer.
The authors acknowledge this issue and mention the need for further research on prompt engineering to improve the robustness of zero-shot IE systems. Techniques like Retrieval-Enhanced Zero-Shot Video Captioning could potentially be applied here to make the prompts more effective.
Another potential concern is the lack of a comprehensive error analysis in the paper. While the overall results are promising, it would be helpful to understand the specific types of errors the ChatIE framework makes and where it struggles compared to fully-supervised models.
Additionally, the authors only evaluate ChatIE on a limited set of IE tasks and datasets. Further research is needed to assess the broader applicability of their approach, especially on more diverse and challenging information extraction problems.
Overall, this work provides an interesting and valuable contribution to the field of zero-shot IE. However, there are still several areas that warrant further investigation to fully realize the potential of language model-based approaches in this domain.
Conclusion
This paper explores the use of large language models, specifically ChatGPT, for zero-shot information extraction. The authors propose a two-stage framework called ChatIE that transforms IE into a multi-turn question-answering task, allowing them to leverage the capabilities of powerful language models.
The empirical results show that ChatIE can achieve impressive performance on various IE tasks, even outperforming some fully-supervised models in certain cases. This suggests that zero-shot IE using LLMs could be a promising approach, especially in data-scarce scenarios where manual labeling is difficult or costly.
While the work has some limitations, it opens up new avenues for research on building information extraction systems with minimal human intervention. By further improving prompt engineering and exploring the robustness of these language model-based approaches, the authors believe this line of work could have significant implications for making IE technology more accessible and widely applicable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
ChatIE: Zero-Shot Information Extraction via Chatting with ChatGPT
Xiang Wei, Xingyu Cui, Ning Cheng, Xiaobin Wang, Xin Zhang, Shen Huang, Pengjun Xie, Jinan Xu, Yufeng Chen, Meishan Zhang, Yong Jiang, Wenjuan Han
Zero-shot information extraction (IE) aims to build IE systems from the unannotated text. It is challenging due to involving little human intervention. Challenging but worthwhile, zero-shot IE reduces the time and effort that data labeling takes. Recent efforts on large language models (LLMs, e.g., GPT-3, ChatGPT) show promising performance on zero-shot settings, thus inspiring us to explore prompt-based methods. In this work, we ask whether strong IE models can be constructed by directly prompting LLMs. Specifically, we transform the zero-shot IE task into a multi-turn question-answering problem with a two-stage framework (ChatIE). With the power of ChatGPT, we extensively evaluate our framework on three IE tasks: entity-relation triple extract, named entity recognition, and event extraction. Empirical results on six datasets across two languages show that ChatIE achieves impressive performance and even surpasses some full-shot models on several datasets (e.g., NYT11-HRL). We believe that our work could shed light on building IE models with limited resources.
Read more5/28/2024

0
How much reliable is ChatGPT's prediction on Information Extraction under Input Perturbations?
Ishani Mondal, Abhilasha Sancheti
In this paper, we assess the robustness (reliability) of ChatGPT under input perturbations for one of the most fundamental tasks of Information Extraction (IE) i.e. Named Entity Recognition (NER). Despite the hype, the majority of the researchers have vouched for its language understanding and generation capabilities; a little attention has been paid to understand its robustness: How the input-perturbations affect 1) the predictions, 2) the confidence of predictions and 3) the quality of rationale behind its prediction. We perform a systematic analysis of ChatGPT's robustness (under both zero-shot and few-shot setup) on two NER datasets using both automatic and human evaluation. Based on automatic evaluation metrics, we find that 1) ChatGPT is more brittle on Drug or Disease replacements (rare entities) compared to the perturbations on widely known Person or Location entities, 2) the quality of explanations for the same entity considerably differ under different types of Entity-Specific and Context-Specific perturbations and the quality can be significantly improved using in-context learning, and 3) it is overconfident for majority of the incorrect predictions, and hence it could lead to misguidance of the end-users.
Read more4/9/2024
🚀
0
Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks
Yida Cai, Hao Sun, Hsiu-Yuan Huang, Yunfang Wu
Information Extraction (IE) plays a crucial role in Natural Language Processing (NLP) by extracting structured information from unstructured text, thereby facilitating seamless integration with various real-world applications that rely on structured data. Despite its significance, recent experiments focusing on English IE tasks have shed light on the challenges faced by Large Language Models (LLMs) in achieving optimal performance, particularly in sub-tasks like Named Entity Recognition (NER). In this paper, we delve into a comprehensive investigation of the performance of mainstream Chinese open-source LLMs in tackling IE tasks, specifically under zero-shot conditions where the models are not fine-tuned for specific tasks. Additionally, we present the outcomes of several few-shot experiments to further gauge the capability of these models. Moreover, our study includes a comparative analysis between these open-source LLMs and ChatGPT, a widely recognized language model, on IE performance. Through meticulous experimentation and analysis, we aim to provide insights into the strengths, limitations, and potential enhancements of existing Chinese open-source LLMs in the domain of Information Extraction within the context of NLP.
Read more6/5/2024
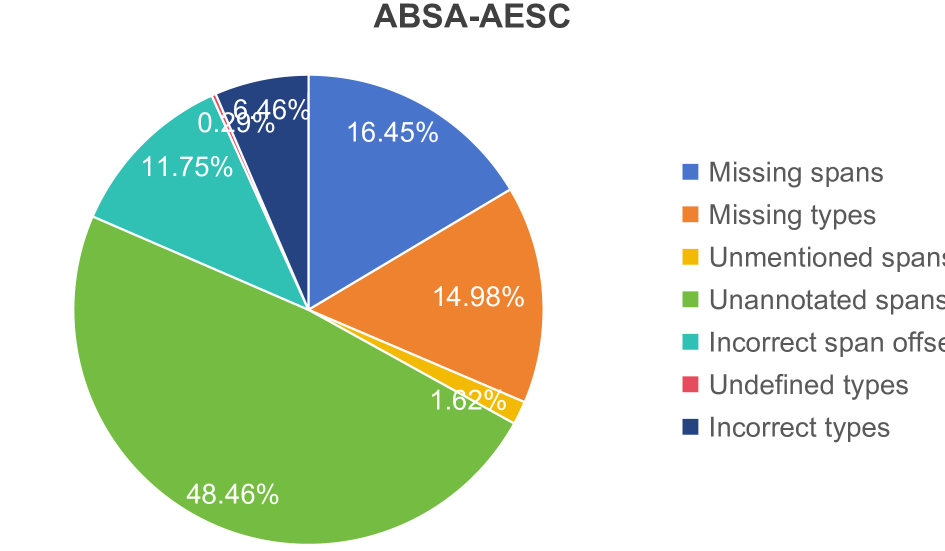
0
An Empirical Study on Information Extraction using Large Language Models
Ridong Han, Chaohao Yang, Tao Peng, Prayag Tiwari, Xiang Wan, Lu Liu, Benyou Wang
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI's GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs' information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs' human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods' effectiveness and some of their remaining issues in improving GPT-4's information extraction ability.
Read more9/10/2024