Small Models Are (Still) Effective Cross-Domain Argument Extractors

0

Sign in to get full access
Overview
- This paper examines the effectiveness of small language models for extracting arguments from text across different domains.
- The researchers compare the performance of small models to larger, more complex models on argument extraction tasks.
- They find that small models can be just as effective as larger models, even when applied to domains outside of their training data.
- This has important implications for developing efficient and accessible argument extraction systems, especially in resource-constrained settings.
Plain English Explanation
In this paper, the researchers investigate whether small language models, which are simpler and more compact than large language models, can still be effective at extracting arguments from text. Argument extraction is the task of identifying the key reasons, evidence, and claims made in a piece of writing.
The researchers compared the performance of small models to larger, more complex models on several argument extraction tasks. Surprisingly, they found that the small models were just as good at identifying arguments, even when the texts were from domains that the models had not been trained on before. This suggests that these smaller, more efficient models can be used to build argument extraction systems that are accessible and practical, without sacrificing too much performance.
This is an important finding because large language models can be computationally expensive and difficult to deploy, especially in resource-constrained settings like low-power devices or developing regions. By showing that small models can be effective cross-domain argument extractors, this research opens the door for more widely accessible and sustainable argument extraction tools that can be used by a broader range of people and organizations.
Technical Explanation
The researchers in this paper explore the use of small language models for the task of cross-domain argument extraction. Argument extraction involves identifying the key reasons, evidence, and claims made in a piece of text. This is an important capability for applications like summarizing research papers, assisting with legal reasoning, and enhancing the capabilities of AI agents.
The researchers compared the performance of small language models to larger, more complex models on several argument extraction datasets. Interestingly, they found that the small models were able to achieve comparable or even better performance than the larger models, even when the test data was from domains that were outside of the models' training distribution.
This suggests that small language models can be effective cross-domain argument extractors, which has important implications for building efficient and accessible argument extraction systems. Large language models can be computationally expensive and difficult to deploy, especially in resource-constrained settings. By demonstrating the effectiveness of small models, this research opens the door for more widely available and sustainable argument extraction tools that can be used by a broader range of people and organizations.
Critical Analysis
The researchers acknowledge several limitations and future research directions in their paper. One key limitation is that their experiments were conducted on English-language datasets, so it's unclear how well the small models would perform on argument extraction tasks in other languages. Additionally, the researchers only evaluated the models' performance on a few specific datasets, so further testing on a wider range of argument extraction benchmarks would be valuable.
Another potential concern is that the small models may not generalize as well as the larger models to more complex or nuanced argumentative structures. The paper focuses on relatively straightforward argument extraction, and it's possible that the small models may struggle with more sophisticated reasoning tasks. Further research is needed to explore the limits of small models' capabilities in this domain.
Despite these caveats, the core finding that small models can be effective cross-domain argument extractors is a significant contribution. By providing evidence that efficient models can perform well on this important task, the researchers have laid the groundwork for more accessible and sustainable argument extraction systems. Readers should carefully consider the limitations discussed in the paper, but also recognize the potential of this research to enable more widespread use of argument extraction technologies.
Conclusion
This paper presents a compelling case for the use of small language models as effective cross-domain argument extractors. The researchers' findings demonstrate that compact models can achieve comparable performance to larger, more complex models on argument extraction tasks, even when dealing with data from outside their training distribution.
These results have important implications for the development of efficient and accessible argument extraction systems, which can be valuable for a wide range of applications, from summarizing research to enhancing the capabilities of AI agents. By showing that small models can be effective cross-domain argument extractors, this research opens the door for more widely available and sustainable tools that can be used by a broader range of people and organizations, especially in resource-constrained settings.
Overall, this paper makes an important contribution to the field of natural language processing by demonstrating the potential of small models to tackle complex tasks like argument extraction. As the demand for accessible and efficient AI systems continues to grow, this research highlights a promising path forward for developing practical and effective solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Small Models Are (Still) Effective Cross-Domain Argument Extractors
William Gantt, Aaron Steven White
Effective ontology transfer has been a major goal of recent work on event argument extraction (EAE). Two methods in particular -- question answering (QA) and template infilling (TI) -- have emerged as promising approaches to this problem. However, detailed explorations of these techniques' ability to actually enable this transfer are lacking. In this work, we provide such a study, exploring zero-shot transfer using both techniques on six major EAE datasets at both the sentence and document levels. Further, we challenge the growing reliance on LLMs for zero-shot extraction, showing that vastly smaller models trained on an appropriate source ontology can yield zero-shot performance superior to that of GPT-3.5 or GPT-4.
Read more4/15/2024

0
Large Language Models for Document-Level Event-Argument Data Augmentation for Challenging Role Types
Joseph Gatto, Parker Seegmiller, Omar Sharif, Sarah M. Preum
Event Argument Extraction (EAE) is an extremely difficult information extraction problem -- with significant limitations in few-shot cross-domain (FSCD) settings. A common solution to FSCD modeling is data augmentation. Unfortunately, existing augmentation methods are not well-suited to a variety of real-world EAE contexts including (i) The need to model long documents (10+ sentences) (ii) The need to model zero and few-shot roles (i.e. event roles with little to no training representation). In this work, we introduce two novel LLM-powered data augmentation frameworks for synthesizing extractive document-level EAE samples using zero in-domain training data. Our highest performing methods provide a 16-pt increase in F1 score on extraction of zero shot role types. To better facilitate analysis of cross-domain EAE, we additionally introduce a new metric, Role-Depth F1 (RDF1), which uses statistical depth to identify roles in the target domain which are semantic outliers with respect to roles observed in the source domain. Our experiments show that LLM-based augmentation can boost RDF1 performance by up to 11 F1 points compared to baseline methods.
Read more6/14/2024
🎯
0
Asking and Answering Questions to Extract Event-Argument Structures
Md Nayem Uddin, Enfa Rose George, Eduardo Blanco, Steven Corman
This paper presents a question-answering approach to extract document-level event-argument structures. We automatically ask and answer questions for each argument type an event may have. Questions are generated using manually defined templates and generative transformers. Template-based questions are generated using predefined role-specific wh-words and event triggers from the context document. Transformer-based questions are generated using large language models trained to formulate questions based on a passage and the expected answer. Additionally, we develop novel data augmentation strategies specialized in inter-sentential event-argument relations. We use a simple span-swapping technique, coreference resolution, and large language models to augment the training instances. Our approach enables transfer learning without any corpora-specific modifications and yields competitive results with the RAMS dataset. It outperforms previous work, and it is especially beneficial to extract arguments that appear in different sentences than the event trigger. We also present detailed quantitative and qualitative analyses shedding light on the most common errors made by our best model.
Read more4/26/2024
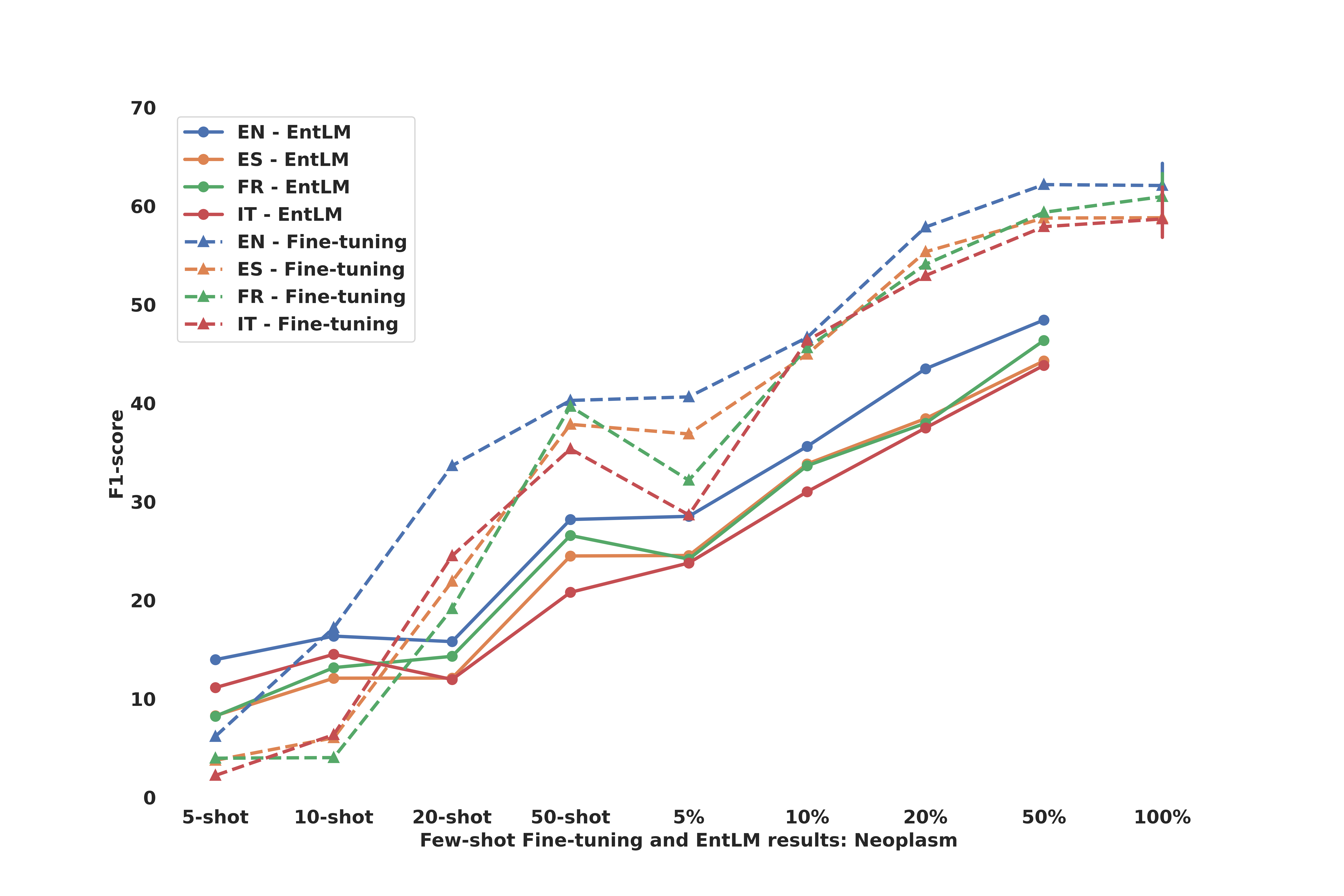
0
Argument Mining in Data Scarce Settings: Cross-lingual Transfer and Few-shot Techniques
Anar Yeginbergen, Maite Oronoz, Rodrigo Agerri
Recent research on sequence labelling has been exploring different strategies to mitigate the lack of manually annotated data for the large majority of the world languages. Among others, the most successful approaches have been based on (i) the cross-lingual transfer capabilities of multilingual pre-trained language models (model-transfer), (ii) data translation and label projection (data-transfer) and (iii), prompt-based learning by reusing the mask objective to exploit the few-shot capabilities of pre-trained language models (few-shot). Previous work seems to conclude that model-transfer outperforms data-transfer methods and that few-shot techniques based on prompting are superior to updating the model's weights via fine-tuning. In this paper, we empirically demonstrate that, for Argument Mining, a sequence labelling task which requires the detection of long and complex discourse structures, previous insights on cross-lingual transfer or few-shot learning do not apply. Contrary to previous work, we show that for Argument Mining data transfer obtains better results than model-transfer and that fine-tuning outperforms few-shot methods. Regarding the former, the domain of the dataset used for data-transfer seems to be a deciding factor, while, for few-shot, the type of task (length and complexity of the sequence spans) and sampling method prove to be crucial.
Read more7/8/2024