Check-Eval: A Checklist-based Approach for Evaluating Text Quality

0

Sign in to get full access
Overview
- A new checklist-based approach for evaluating text quality, called Check-Eval
- Aims to provide a comprehensive and systematic way to assess various aspects of text quality
- Designed to be used with large language models and other text generation systems
Plain English Explanation
The paper introduces a new method called Check-Eval for evaluating the quality of text produced by large language models and other text generation systems. The key idea is to use a checklist that covers different aspects of text quality, such as coherence, factual accuracy, and grammar. This provides a comprehensive and systematic way to assess the quality of generated text, which is important as these models become more widely used.
Technical Explanation
The Check-Eval approach involves defining a set of checklist items that cover different aspects of text quality, such as coherence, factual accuracy, grammar, and readability. These checklist items are then used to systematically evaluate the quality of text generated by large language models or other text generation systems. The authors demonstrate the usefulness of their approach through experiments on various text generation tasks.
Critical Analysis
The Check-Eval approach provides a comprehensive and systematic way to assess text quality, which is an important area for further research as large language models become more widely used. However, the authors acknowledge that the checklist items may not be exhaustive and that there could be additional aspects of text quality that are not covered. Additionally, the evaluation process may require human judgment, which could introduce some subjectivity.
Conclusion
The Check-Eval approach provides a new and promising way to evaluate the quality of text generated by large language models and other text generation systems. By using a comprehensive checklist, the approach offers a systematic and objective way to assess different aspects of text quality, which is crucial as these models become more widely used. While the approach has some limitations, the authors' work represents an important step forward in the evaluation of text quality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Check-Eval: A Checklist-based Approach for Evaluating Text Quality
Jayr Pereira, Andre Assumpcao, Roberto Lotufo
Evaluating the quality of text generated by large language models (LLMs) remains a significant challenge. Traditional metrics often fail to align well with human judgments, particularly in tasks requiring creativity and nuance. In this paper, we propose textsc{Check-Eval}, a novel evaluation framework leveraging LLMs to assess the quality of generated text through a checklist-based approach. textsc{Check-Eval} can be employed as both a reference-free and reference-dependent evaluation method, providing a structured and interpretable assessment of text quality. The framework consists of two main stages: checklist generation and checklist evaluation. We validate textsc{Check-Eval} on two benchmark datasets: Portuguese Legal Semantic Textual Similarity and textsc{SummEval}. Our results demonstrate that textsc{Check-Eval} achieves higher correlations with human judgments compared to existing metrics, such as textsc{G-Eval} and textsc{GPTScore}, underscoring its potential as a more reliable and effective evaluation framework for natural language generation tasks. The code for our experiments is available at url{https://anonymous.4open.science/r/check-eval-0DB4}
Read more9/11/2024
🧪
0
SYNTHEVAL: Hybrid Behavioral Testing of NLP Models with Synthetic CheckLists
Raoyuan Zhao, Abdullatif Koksal, Yihong Liu, Leonie Weissweiler, Anna Korhonen, Hinrich Schutze
Traditional benchmarking in NLP typically involves using static held-out test sets. However, this approach often results in an overestimation of performance and lacks the ability to offer comprehensive, interpretable, and dynamic assessments of NLP models. Recently, works like DynaBench (Kiela et al., 2021) and CheckList (Ribeiro et al., 2020) have addressed these limitations through behavioral testing of NLP models with test types generated by a multistep human-annotated pipeline. Unfortunately, manually creating a variety of test types requires much human labor, often at prohibitive cost. In this work, we propose SYNTHEVAL, a hybrid behavioral testing framework that leverages large language models (LLMs) to generate a wide range of test types for a comprehensive evaluation of NLP models. SYNTHEVAL first generates sentences via LLMs using controlled generation, and then identifies challenging examples by comparing the predictions made by LLMs with task-specific NLP models. In the last stage, human experts investigate the challenging examples, manually design templates, and identify the types of failures the taskspecific models consistently exhibit. We apply SYNTHEVAL to two classification tasks, sentiment analysis and toxic language detection, and show that our framework is effective in identifying weaknesses of strong models on these tasks. We share our code in https://github.com/Loreley99/SynthEval_CheckList.
Read more9/2/2024

0
A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
Read more7/2/2024
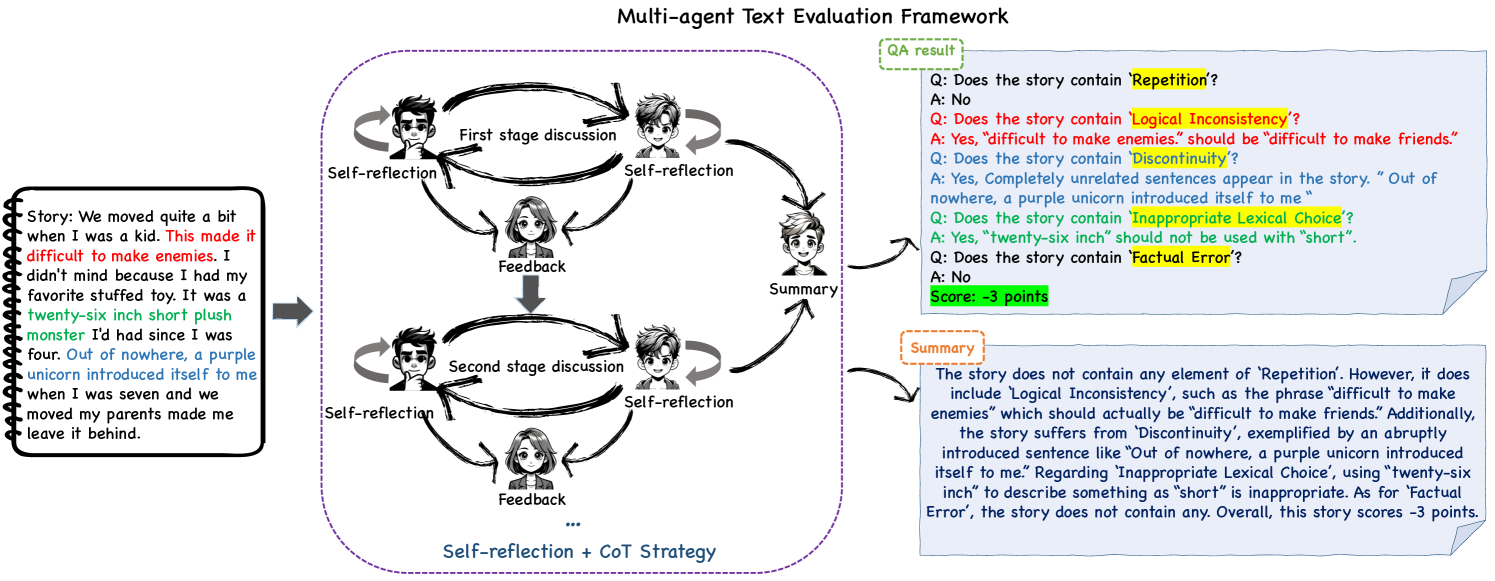
0
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Yu Li, Shenyu Zhang, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, Guilin Qi, Dehai Min
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A Multi-Agent Text Evaluation framework where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.
Read more4/16/2024