Chinchilla Scaling: A replication attempt
2404.10102
124
0
Abstract
Hoffmann et al. (2022) propose three methods for estimating a compute-optimal scaling law. We attempt to replicate their third estimation procedure, which involves fitting a parametric loss function to a reconstruction of data from their plots. We find that the reported estimates are inconsistent with their first two estimation methods, fail at fitting the extracted data, and report implausibly narrow confidence intervals--intervals this narrow would require over 600,000 experiments, while they likely only ran fewer than 500. In contrast, our rederivation of the scaling law using the third approach yields results that are compatible with the findings from the first two estimation procedures described by Hoffmann et al.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper is a replication attempt of the "Chinchilla Scaling" research presented in the paper "Unraveling the mystery of neural scaling laws" by Hoffmann et al.
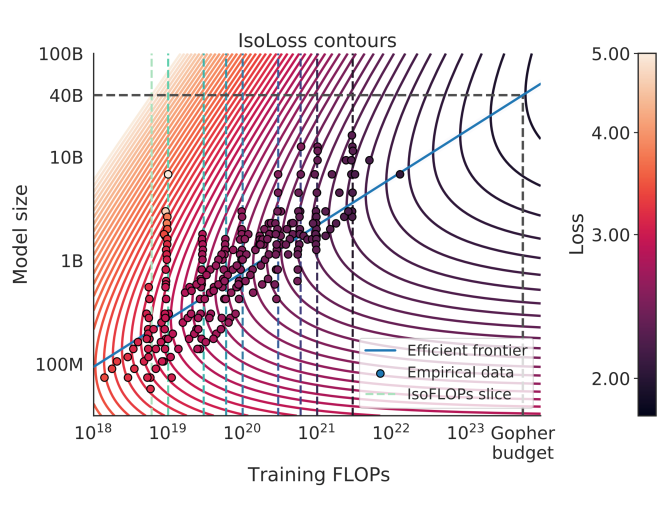
- The authors aim to validate the findings of the original paper by extracting data from their Figure 4 and attempting to replicate their "Approach 3" scaling analysis.
- The results provide insights into the reliability and generalizability of the Chinchilla Scaling phenomenon observed in large language models.
Plain English Explanation
The paper focuses on replicating a previous study that explored the "Chinchilla Scaling" relationship, which describes how the performance of large language models improves as they are trained on more data and have more parameters. The researchers in this paper wanted to see if they could reproduce the findings from the earlier study by extracting data from one of its figures and then performing a similar analysis.
Replicating previous research is important in science to verify the reliability and consistency of the results. If the authors of this paper are able to closely match the findings from the original study, it would lend more credibility to the Chinchilla Scaling phenomenon and suggest that it is a robust relationship that holds true across different experiments and datasets. On the other hand, if they struggle to replicate the results, it could indicate issues with the original study or limitations in the generalizability of the Chinchilla Scaling observations.
Technical Explanation
The paper begins by extracting data points from Figure 4 in the Unraveling the mystery of neural scaling laws paper by Hoffmann et al. This figure shows the relationship between model performance, parameter count, and training data size for large language models.
The authors then attempt to replicate "Approach 3" from the Hoffmann et al. paper, which involves fitting a power law curve to the extracted data points. This power law relationship is the essence of the Chinchilla Scaling phenomenon, where model performance scales as a function of parameter count and training data size.
The results of the replication attempt are presented and compared to the original findings. The authors discuss the similarities and differences observed, as well as the implications for the reliability and generalizability of the Chinchilla Scaling principles.
Critical Analysis
The paper acknowledges several limitations and caveats in its replication attempt. For example, the authors note that they were not able to perfectly reproduce the data points from the original figure, which may have introduced some error into their analysis. Additionally, the replication was limited to a single "Approach" from the Hoffmann et al. paper, and the authors suggest that further replication efforts across the different approaches would be valuable.
Another potential issue is that the replication was conducted on the same general dataset and models as the original study, rather than an entirely independent dataset. This raises questions about the extent to which the Chinchilla Scaling observations can be generalized beyond the specific context of this research.
The authors maintain an objective and respectful tone throughout the critical analysis, acknowledging the importance of the original work and the challenges inherent in replication efforts. They encourage readers to thoughtfully consider the findings and limitations, and to continue exploring the reliability and generalizability of the Chinchilla Scaling phenomenon.
Conclusion
This paper provides a replication attempt of the Chinchilla Scaling research presented in the Unraveling the mystery of neural scaling laws paper. The results suggest that the authors were largely able to reproduce the key findings, lending credibility to the Chinchilla Scaling relationship observed in large language models.
However, the authors also identify several limitations and areas for further research, highlighting the importance of rigorously validating and generalizing important findings in the field of AI and machine learning. Continued efforts to replicate and extend this work will help to solidify our understanding of the fundamental scaling principles that govern the performance of large-scale models.
Related Papers
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
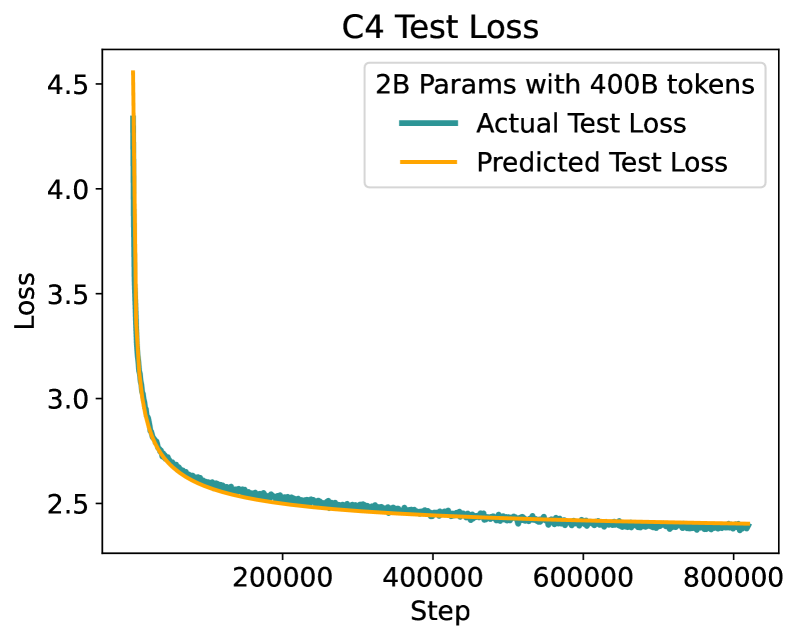
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024
Scaling and renormalization in high-dimensional regression
Alexander B. Atanasov, Jacob A. Zavatone-Veth, Cengiz Pehlevan
0
0
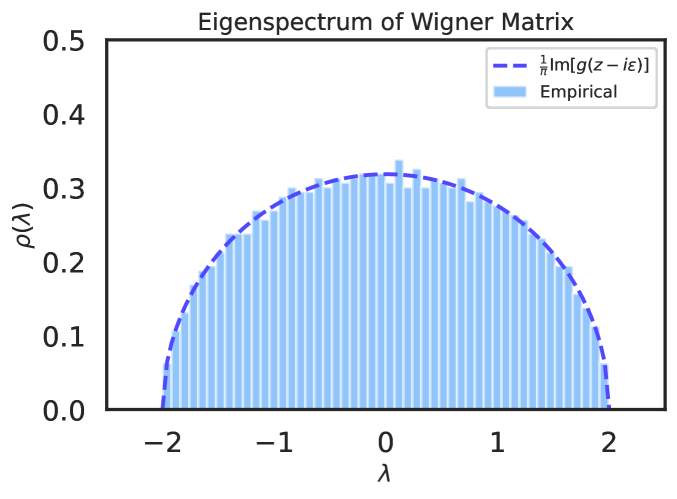
This paper presents a succinct derivation of the training and generalization performance of a variety of high-dimensional ridge regression models using the basic tools of random matrix theory and free probability. We provide an introduction and review of recent results on these topics, aimed at readers with backgrounds in physics and deep learning. Analytic formulas for the training and generalization errors are obtained in a few lines of algebra directly from the properties of the $S$-transform of free probability. This allows for a straightforward identification of the sources of power-law scaling in model performance. We compute the generalization error of a broad class of random feature models. We find that in all models, the $S$-transform corresponds to the train-test generalization gap, and yields an analogue of the generalized-cross-validation estimator. Using these techniques, we derive fine-grained bias-variance decompositions for a very general class of random feature models with structured covariates. These novel results allow us to discover a scaling regime for random feature models where the variance due to the features limits performance in the overparameterized setting. We also demonstrate how anisotropic weight structure in random feature models can limit performance and lead to nontrivial exponents for finite-width corrections in the overparameterized setting. Our results extend and provide a unifying perspective on earlier models of neural scaling laws.
5/2/2024
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
0
0
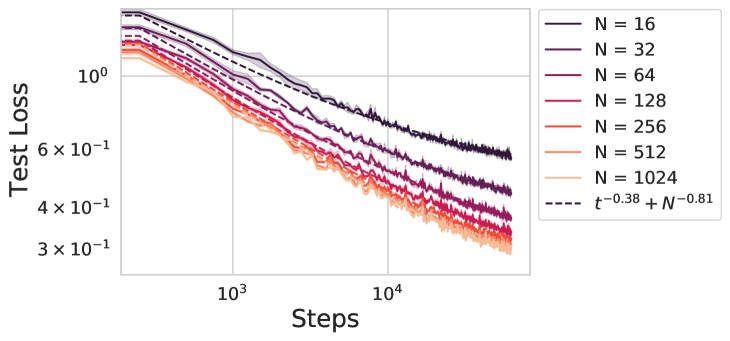
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
4/15/2024
✅
More Compute Is What You Need
Zhen Guo
0
0
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
5/3/2024