More Compute Is What You Need
2404.19484
0
0
✅
Abstract
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers propose a new scaling law that suggests model performance depends mostly on the amount of compute spent, rather than the specific allocation to model size and dataset size.
- This scaling law suggests that for inference efficiency, training should prioritize smaller model sizes and larger training datasets.
- Assuming the exhaustion of available web datasets, the researchers predict that scaling the model size might be the only way to further improve model performance.
Plain English Explanation
Training large language models has become increasingly expensive for most practitioners. To manage these costs, they commonly use scaling laws to decide how to allocate computing resources between model size and the amount of training data.
The researchers in this paper propose a new scaling law that suggests a different approach. They found that model performance depends mostly on the total amount of computing power used, rather than the specific balance between model size and dataset size.
This means that, for the most efficient performance during real-world use (inference efficiency), the best strategy is to train smaller models but use larger datasets. The researchers also predict that, once we've used up all the available web data, the only way to further improve model performance will be to increase the size of the models themselves.
Technical Explanation
The researchers hypothesized a new scaling law that suggests the performance of transformer-based language models depends primarily on the total amount of compute used during training, rather than the specific allocation between model size and dataset size.
To test this, they trained a series of models with varying combinations of model size and dataset size, while keeping the total compute constant. They found that model performance scaled similarly regardless of the specific allocation, supporting their proposed scaling law.
Based on this finding, the researchers make two key predictions:
- For the most efficient model performance during real-world use (inference efficiency), training should prioritize using smaller model sizes and larger training datasets.
- Assuming the exhaustion of available web datasets, scaling up the model size might be the only way to further improve model performance, since increasing dataset size would no longer be an option.
The researchers' proposed scaling law builds on previous work on scaling laws for language models and data filtering/curation.
Critical Analysis
The researchers acknowledge that their proposed scaling law may not hold for all types of transformer-based models or tasks. The experiments were focused on a particular class of language models, and the conclusions may not generalize to other domains like speech recognition or multimodal applications.
Additionally, the researchers note that their findings assume the availability of high-quality web-scraped datasets. If the remaining available web data is of lower quality or relevance, then scaling the model size may not be as effective as they predict.
Further research is needed to validate the researchers' scaling law across a wider range of model architectures, tasks, and data regimes. It will also be important to understand the underlying mechanisms that lead to their proposed scaling behavior.
Conclusion
This paper presents a novel scaling law that suggests the performance of transformer-based language models depends primarily on the total compute used during training, rather than the specific allocation between model size and dataset size.
The researchers' findings have important implications for the efficient training of large language models, as they indicate that prioritizing larger datasets over larger model sizes can lead to better real-world performance. However, the proposed scaling law may have limitations, and additional research is needed to fully understand its applicability and implications for the field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
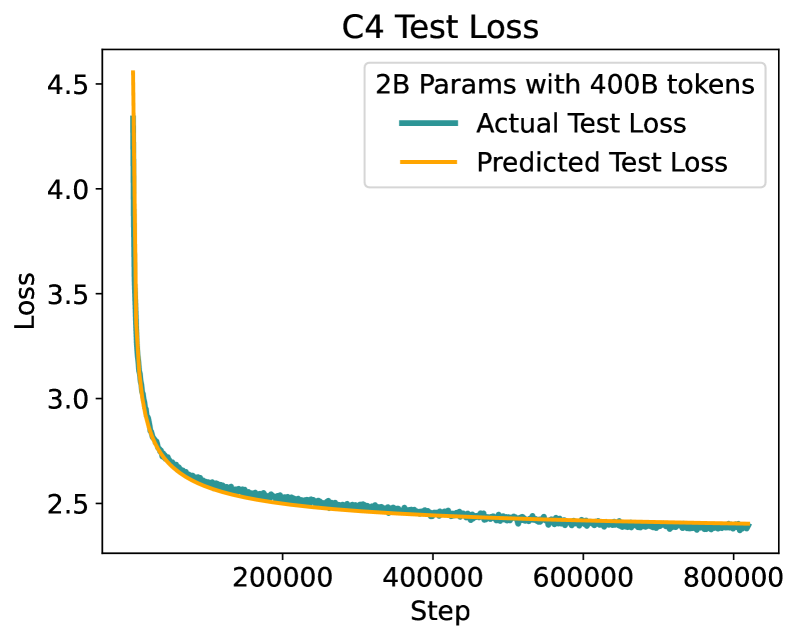
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024
Inverse Scaling: When Bigger Isn't Better
Ian R. McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, Andrew Gritsevskiy, Daniel Wurgaft, Derik Kauffman, Gabriel Recchia, Jiacheng Liu, Joe Cavanagh, Max Weiss, Sicong Huang, The Floating Droid, Tom Tseng, Tomasz Korbak, Xudong Shen, Yuhui Zhang, Zhengping Zhou, Najoung Kim, Samuel R. Bowman, Ethan Perez
0
0
Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
5/14/2024
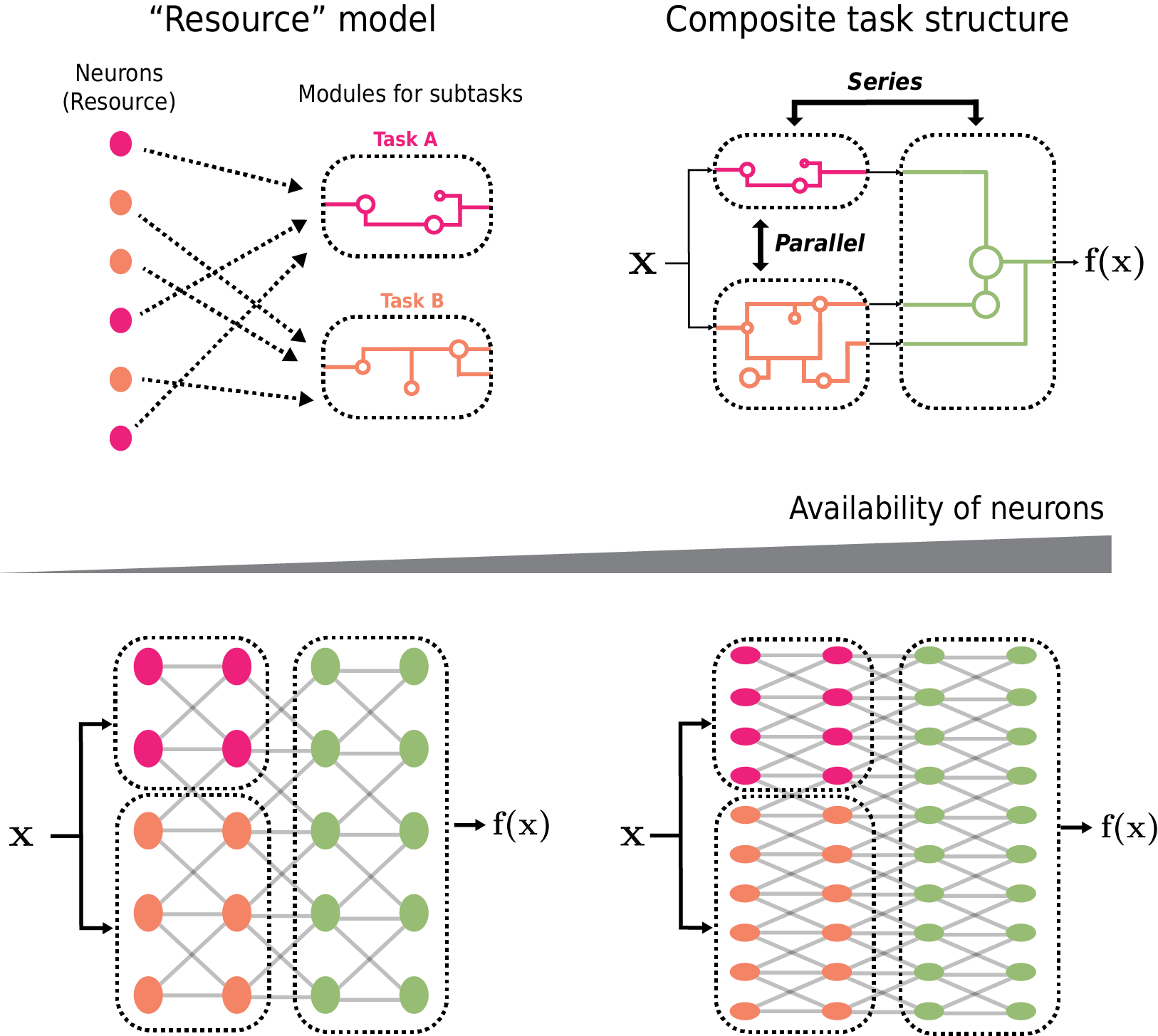
New!A Resource Model For Neural Scaling Law
Jinyeop Song, Ziming Liu, Max Tegmark, Jeff Gore
0
0
Neural scaling laws characterize how model performance improves as the model size scales up. Inspired by empirical observations, we introduce a resource model of neural scaling. A task is usually composite hence can be decomposed into many subtasks, which compete for resources (measured by the number of neurons allocated to subtasks). On toy problems, we empirically find that: (1) The loss of a subtask is inversely proportional to its allocated neurons. (2) When multiple subtasks are present in a composite task, the resources acquired by each subtask uniformly grow as models get larger, keeping the ratios of acquired resources constants. We hypothesize these findings to be generally true and build a model to predict neural scaling laws for general composite tasks, which successfully replicates the neural scaling law of Chinchilla models reported in arXiv:2203.15556. We believe that the notion of resource used in this paper will be a useful tool for characterizing and diagnosing neural networks.
5/16/2024