Choose What You Need: Disentangled Representation Learning for Scene Text Recognition, Removal and Editing

0
❗
Sign in to get full access
Overview
- Scene text images contain both style information (font, background) and content information (characters, textures)
- Different scene text tasks require different types of information, but previous methods used tightly coupled features for all tasks, resulting in suboptimal performance
- The proposed DARLING framework aims to disentangle these two types of features to improve adaptability and performance on various downstream tasks
Plain English Explanation
Scene text images, such as street signs or product labels, have two main types of information: style and content. The style refers to the visual appearance, like the font or background, while the content is the actual text or characters. Different applications that work with scene text, like text recognition or text editing, may need to focus on one type of information more than the other.
However, previous methods for processing scene text images typically used a single, tightly coupled set of features to represent both the style and content information. This made the systems less flexible and limited their performance on specific tasks.
The DARLING framework tackles this by learning to separate the style and content features. It does this by creating a dataset of image pairs that have the same style but different content. Using this dataset, the model is trained to extract style features that are independent of the text content, and content features that are independent of the visual style.
This disentangled representation allows the model to focus on the most relevant information for a given task, like recognizing the text content for a text recognition application, or editing the visual style of the text for a text editing application. By isolating the style and content, the model can perform these tasks more effectively.
Technical Explanation
The key technical innovations of the DARLING framework are:
-
Dataset Synthesis: The researchers synthesize a dataset of image pairs that have identical style but different content. This provides the supervision signal to disentangle the style and content features.
-
Feature Disentanglement: The visual representation is directly split into style and content features. The content features are supervised by a text recognition loss, while an alignment loss aligns the style features between the image pairs.
-
Style-based Image Reconstruction: The style features are used to reconstruct the counterpart image in the pair via an image decoder, with the content determined by a prompt. This operation effectively decouples the style and content features.
The paper demonstrates that this disentangled representation learning approach achieves state-of-the-art performance on several scene text tasks, including text recognition, removal, and editing. This is the first time the inherent properties of scene text images have been disentangled in this way.
Critical Analysis
The DARLING framework represents an important step forward in scene text processing by explicitly separating style and content features. This allows the model to be more flexible and adaptable to different downstream tasks.
However, the paper does not explore the generalization of this approach to other domains beyond scene text, such as general image-text or text-to-image tasks. Further research is needed to understand the broader applicability of disentangled representation learning in these areas.
Additionally, the paper does not provide a detailed analysis of the quality of the disentangled features, such as how well they capture the underlying style and content properties. Metrics for evaluating disentanglement could be useful to provide a more rigorous assessment of the framework's effectiveness.
Conclusion
The DARLING framework represents an innovative approach to scene text processing by learning to separate the style and content features of text images. This disentangled representation allows the model to adapt more effectively to different downstream tasks, leading to state-of-the-art performance on text recognition, removal, and editing.
While the paper focuses on scene text, the general principles of disentangled representation learning could have broader applications in other image-text domains, such as joint quality assessment or text-to-image personalization. Further research is needed to explore the generalizability of this approach and develop more robust methods for evaluating the quality of the disentangled features.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Choose What You Need: Disentangled Representation Learning for Scene Text Recognition, Removal and Editing
Boqiang Zhang, Hongtao Xie, Zuan Gao, Yuxin Wang
Scene text images contain not only style information (font, background) but also content information (character, texture). Different scene text tasks need different information, but previous representation learning methods use tightly coupled features for all tasks, resulting in sub-optimal performance. We propose a Disentangled Representation Learning framework (DARLING) aimed at disentangling these two types of features for improved adaptability in better addressing various downstream tasks (choose what you really need). Specifically, we synthesize a dataset of image pairs with identical style but different content. Based on the dataset, we decouple the two types of features by the supervision design. Clearly, we directly split the visual representation into style and content features, the content features are supervised by a text recognition loss, while an alignment loss aligns the style features in the image pairs. Then, style features are employed in reconstructing the counterpart image via an image decoder with a prompt that indicates the counterpart's content. Such an operation effectively decouples the features based on their distinctive properties. To the best of our knowledge, this is the first time in the field of scene text that disentangles the inherent properties of the text images. Our method achieves state-of-the-art performance in Scene Text Recognition, Removal, and Editing.
Read more5/8/2024

0
Training-free Color-Style Disentanglement for Constrained Text-to-Image Synthesis
Aishwarya Agarwal, Srikrishna Karanam, Balaji Vasan Srinivasan
We consider the problem of independently, in a disentangled fashion, controlling the outputs of text-to-image diffusion models with color and style attributes of a user-supplied reference image. We present the first training-free, test-time-only method to disentangle and condition text-to-image models on color and style attributes from reference image. To realize this, we propose two key innovations. Our first contribution is to transform the latent codes at inference time using feature transformations that make the covariance matrix of current generation follow that of the reference image, helping meaningfully transfer color. Next, we observe that there exists a natural disentanglement between color and style in the LAB image space, which we exploit to transform the self-attention feature maps of the image being generated with respect to those of the reference computed from its L channel. Both these operations happen purely at test time and can be done independently or merged. This results in a flexible method where color and style information can come from the same reference image or two different sources, and a new generation can seamlessly fuse them in either scenario.
Read more9/5/2024
0
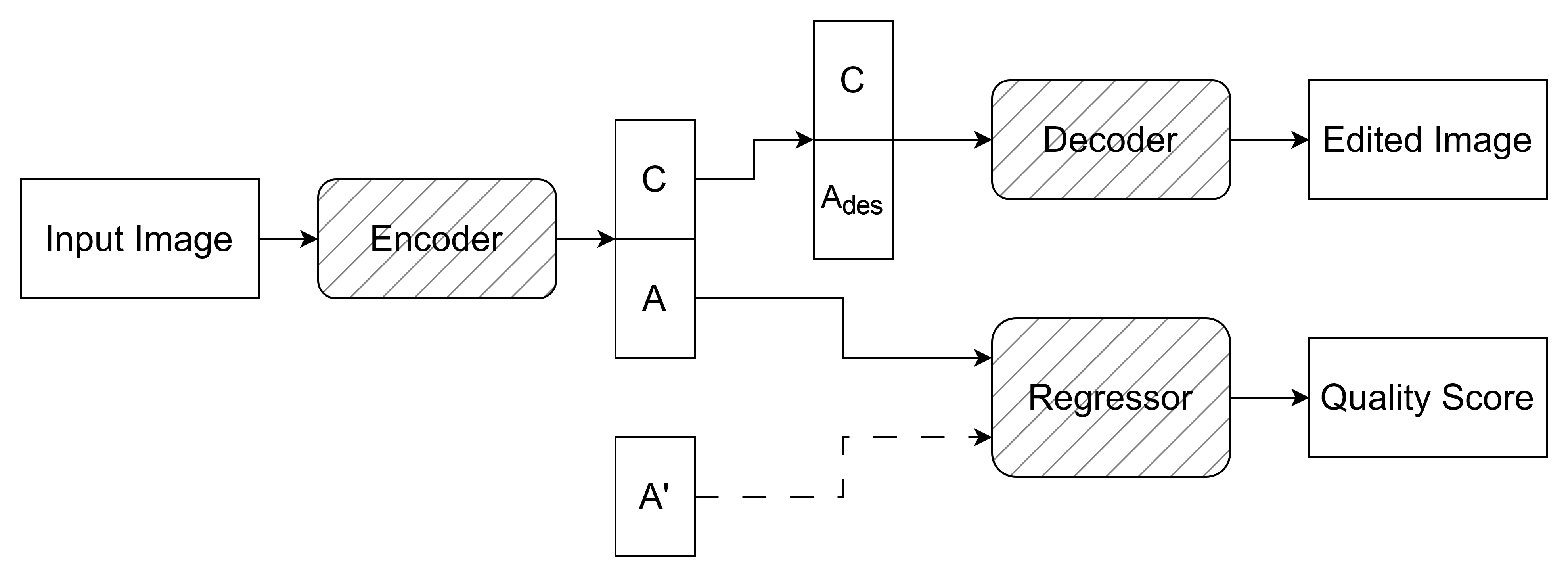
Joint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content
Abhinau K. Venkataramanan, Cosmin Stejerean, Ioannis Katsavounidis, Hassene Tmar, Alan C. Bovik
The deep learning revolution has strongly impacted low-level image processing tasks such as style/domain transfer, enhancement/restoration, and visual quality assessments. Despite often being treated separately, the aforementioned tasks share a common theme of understanding, editing, or enhancing the appearance of input images without modifying the underlying content. We leverage this observation to develop a novel disentangled representation learning method that decomposes inputs into content and appearance features. The model is trained in a self-supervised manner and we use the learned features to develop a new quality prediction model named DisQUE. We demonstrate through extensive evaluations that DisQUE achieves state-of-the-art accuracy across quality prediction tasks and distortion types. Moreover, we demonstrate that the same features may also be used for image processing tasks such as HDR tone mapping, where the desired output characteristics may be tuned using example input-output pairs.
Read more4/23/2024

0
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Zhaoxi Mu, Xinyu Yang, Sining Sun, Qing Yang
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
Read more8/27/2024