Choosing Wisely and Learning Deeply: Selective Cross-Modality Distillation via CLIP for Domain Generalization

0

Sign in to get full access
Overview
- This paper introduces a novel approach called "Selective Cross-Modality Distillation via CLIP for Domain Generalization" to address the challenge of domain generalization in computer vision.
- The method selectively distills knowledge from a pre-trained CLIP (Contrastive Language-Image Pre-training) model to improve the performance of a target vision model on unseen domains.
- The key idea is to leverage the rich cross-modal representations learned by CLIP to guide the training of the vision model, while being selective about which CLIP knowledge to transfer.
Plain English Explanation
The paper describes a way to train computer vision models that can perform well on a variety of different datasets, even ones the model hasn't seen before. This is called "domain generalization," and it's an important problem in AI because real-world applications often require models to work in many different settings.
The researchers' approach is to use a pre-trained model called CLIP, which has been trained on a huge amount of online data to learn how to connect images and text. The key insight is that the knowledge CLIP has learned about the relationships between visual concepts and language can be very useful for training vision models to work across different domains.
However, the researchers don't just dump all of CLIP's knowledge into the vision model. Instead, they are selective about which parts of CLIP's knowledge are most relevant and transfer only that information. This "selective distillation" helps the vision model learn the essential visual patterns and concepts it needs to generalize well, without getting bogged down in irrelevant details.
By combining the power of CLIP's cross-modal representations with a selective transfer of knowledge, the researchers were able to train vision models that significantly outperformed previous approaches on a range of domain generalization benchmarks. This work highlights the value of leveraging pre-trained models and being strategic about how you transfer their knowledge to new tasks.
Technical Explanation
The paper proposes a "Selective Cross-Modality Distillation" (SCMD) method to address the domain generalization problem in computer vision. The key idea is to selectively distill the knowledge from a pre-trained CLIP model into a target vision model, in order to improve its performance on unseen domains.
CLIP is a large, pre-trained model that has learned rich cross-modal representations by being trained on a huge amount of image-text pairs. The researchers hypothesize that these representations can provide valuable guidance for training vision models to be more robust and generalizable.
However, instead of simply transferring all of CLIP's knowledge to the vision model, SCMD takes a more selective approach. It identifies the most relevant subset of CLIP's representations and distills only that information into the target model. This selective distillation helps the vision model learn the essential visual concepts and patterns it needs to generalize, without being overwhelmed by irrelevant details.
The SCMD framework consists of several key components:
-
CLIP Representation Selection: The researchers devise a novel method to identify the most relevant CLIP representations for the target task and domain. This involves analyzing the alignment between CLIP's representations and the target vision model's features.
-
Selective Distillation: The selected CLIP representations are then used to guide the training of the target vision model through a distillation-based learning process. This helps the vision model learn the most salient visual information from CLIP's cross-modal knowledge.
-
Hybrid Training: In addition to the selective distillation, the researchers also employ a hybrid training approach that combines supervised learning on the target domain data with the distillation from CLIP.
The experiments conducted in the paper demonstrate that SCMD significantly outperforms previous state-of-the-art domain generalization methods on a range of benchmarks. This highlights the value of leveraging pre-trained models like CLIP in a strategic and selective manner to improve the generalization capabilities of computer vision systems.
Critical Analysis
The paper presents a well-designed and thoughtful approach to addressing the important problem of domain generalization in computer vision. The selective distillation of CLIP's knowledge is a clever and effective way to harness the power of pre-trained cross-modal representations while avoiding the potential pitfalls of naively transferring all of that knowledge.
One limitation mentioned in the paper is that the SCMD framework assumes the availability of a pre-trained CLIP model, which may not always be the case. It would be interesting to see if similar selective distillation techniques could be applied to other types of pre-trained models, such as self-supervised vision transformers like ViT or domain-specific models like PracticalDG.
Additionally, the paper focuses on static image classification tasks, but it would be valuable to explore how the SCMD approach could be extended to other computer vision problems, such as remote sensing change detection or self-supervised cross-modal distillation.
Overall, this work represents a significant contribution to the field of domain generalization and demonstrates the potential of leveraging pre-trained cross-modal models in a strategic manner to improve the performance and robustness of computer vision systems.
Conclusion
The paper introduces a novel "Selective Cross-Modality Distillation via CLIP" (SCMD) approach to address the challenge of domain generalization in computer vision. By selectively distilling the relevant knowledge from a pre-trained CLIP model, the researchers were able to train vision models that significantly outperformed previous state-of-the-art methods on a range of domain generalization benchmarks.
This work highlights the value of leveraging the rich cross-modal representations learned by pre-trained models like CLIP, while being strategic about how that knowledge is transferred. The selective distillation technique helps the target vision model learn the essential visual concepts and patterns it needs to generalize, without being overwhelmed by irrelevant details.
The SCMD framework represents an important step forward in the field of domain generalization, and its principles could potentially be extended to other types of pre-trained models and computer vision problems. As AI systems become more widely deployed in real-world applications, the ability to build robust and generalizable models will be increasingly crucial. This research contributes valuable insights and techniques to address this critical challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Choosing Wisely and Learning Deeply: Selective Cross-Modality Distillation via CLIP for Domain Generalization
Jixuan Leng, Yijiang Li, Haohan Wang
Domain Generalization (DG), a crucial research area, seeks to train models across multiple domains and test them on unseen ones. In this paper, we introduce a novel approach, namely, Selective Cross-Modality Distillation for Domain Generalization (SCMD). SCMD leverages the capabilities of large vision-language models, specifically CLIP, to train a more efficient model, ensuring it acquires robust generalization capabilities across unseen domains. Our primary contribution is a unique selection framework strategically designed to identify hard-to-learn samples for distillation. In parallel, we introduce a novel cross-modality module that seamlessly combines the projected features of the student model with the text embeddings from CLIP, ensuring the alignment of similarity distributions. We assess SCMD's performance on various benchmarks, where it empowers a ResNet50 to deliver state-of-the-art performance, surpassing existing domain generalization methods. Furthermore, we provide a theoretical analysis of our selection strategy, offering deeper insight into its effectiveness and potential in the field of DG.
Read more4/24/2024
0
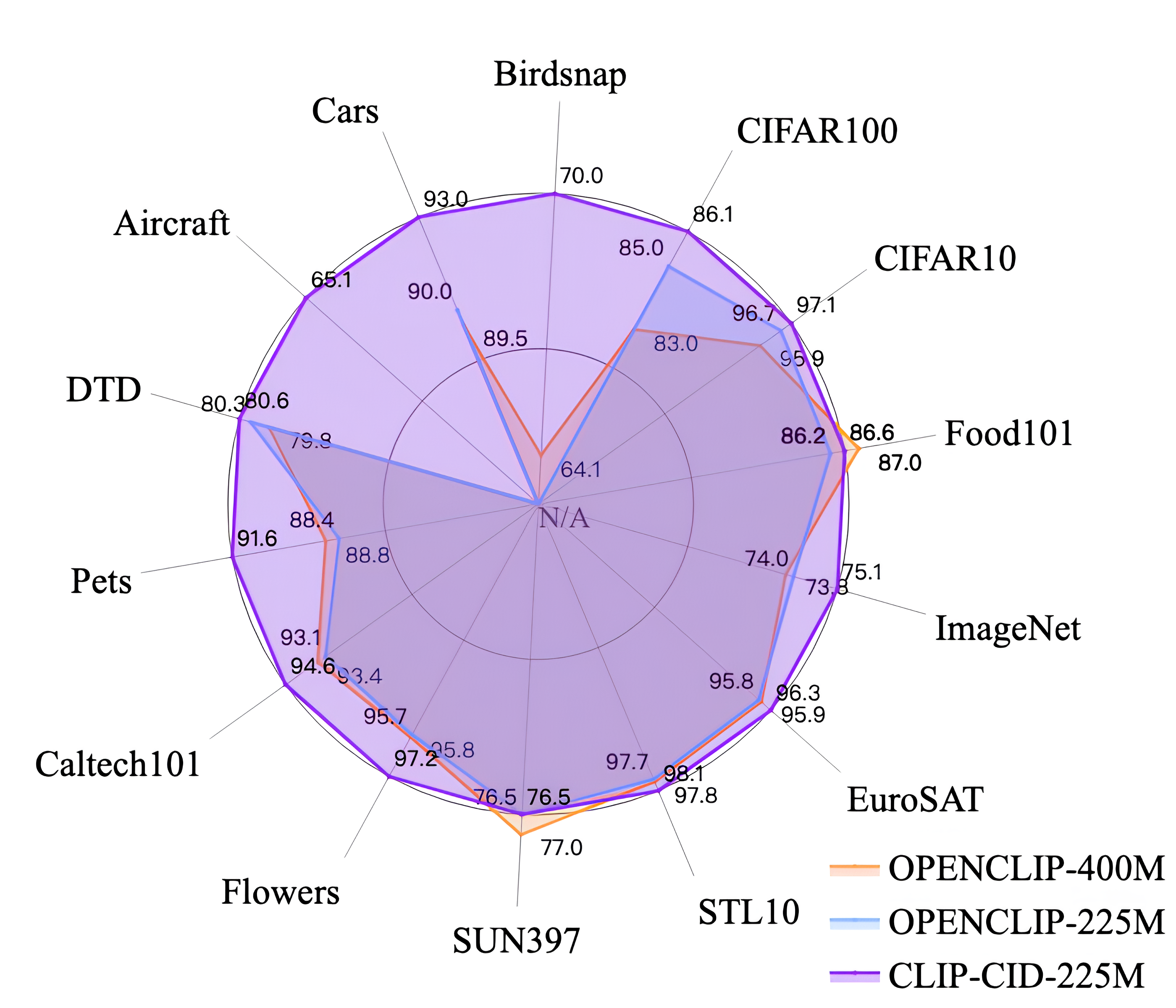
CLIP-CID: Efficient CLIP Distillation via Cluster-Instance Discrimination
Kaicheng Yang, Tiancheng Gu, Xiang An, Haiqiang Jiang, Xiangzi Dai, Ziyong Feng, Weidong Cai, Jiankang Deng
Contrastive Language-Image Pre-training (CLIP) has achieved excellent performance over a wide range of tasks. However, the effectiveness of CLIP heavily relies on a substantial corpus of pre-training data, resulting in notable consumption of computational resources. Although knowledge distillation has been widely applied in single modality models, how to efficiently expand knowledge distillation to vision-language foundation models with extensive data remains relatively unexplored. In this paper, we introduce CLIP-CID, a novel distillation mechanism that effectively transfers knowledge from a large vision-language foundation model to a smaller model. We initially propose a simple but efficient image semantic balance method to reduce transfer learning bias and improve distillation efficiency. This method filters out 43.7% of image-text pairs from the LAION400M while maintaining superior performance. After that, we leverage cluster-instance discrimination to facilitate knowledge transfer from the teacher model to the student model, thereby empowering the student model to acquire a holistic semantic comprehension of the pre-training data. Experimental results demonstrate that CLIP-CID achieves state-of-the-art performance on various downstream tasks including linear probe and zero-shot classification.
Read more8/20/2024
✨
0
Distilling Knowledge from Text-to-Image Generative Models Improves Visio-Linguistic Reasoning in CLIP
Samyadeep Basu, Shell Xu Hu, Maziar Sanjabi, Daniela Massiceti, Soheil Feizi
Image-text contrastive models like CLIP have wide applications in zero-shot classification, image-text retrieval, and transfer learning. However, they often struggle on compositional visio-linguistic tasks (e.g., attribute-binding or object-relationships) where their performance is no better than random chance. To address this, we introduce SDS-CLIP, a lightweight and sample-efficient distillation method to enhance CLIP's compositional visio-linguistic reasoning. Our approach fine-tunes CLIP using a distillation objective borrowed from large text-to-image generative models like Stable-Diffusion, which are known for their strong visio-linguistic reasoning abilities. On the challenging Winoground benchmark, SDS-CLIP improves the visio-linguistic performance of various CLIP models by up to 7%, while on the ARO dataset, it boosts performance by up to 3%. This work underscores the potential of well-designed distillation objectives from generative models to enhance contrastive image-text models with improved visio-linguistic reasoning capabilities.
Read more7/2/2024

0
Rethinking Domain Adaptation and Generalization in the Era of CLIP
Ruoyu Feng, Tao Yu, Xin Jin, Xiaoyuan Yu, Lei Xiao, Zhibo Chen
In recent studies on domain adaptation, significant emphasis has been placed on the advancement of learning shared knowledge from a source domain to a target domain. Recently, the large vision-language pre-trained model, i.e., CLIP has shown strong ability on zero-shot recognition, and parameter efficient tuning can further improve its performance on specific tasks. This work demonstrates that a simple domain prior boosts CLIP's zero-shot recognition in a specific domain. Besides, CLIP's adaptation relies less on source domain data due to its diverse pre-training dataset. Furthermore, we create a benchmark for zero-shot adaptation and pseudo-labeling based self-training with CLIP. Last but not least, we propose to improve the task generalization ability of CLIP from multiple unlabeled domains, which is a more practical and unique scenario. We believe our findings motivate a rethinking of domain adaptation benchmarks and the associated role of related algorithms in the era of CLIP.
Read more7/23/2024