CHOSEN: Compilation to Hardware Optimization Stack for Efficient Vision Transformer Inference

0

Sign in to get full access
Overview
- This paper presents CHOSEN, a compilation and hardware optimization stack for efficient inference of Vision Transformers (ViTs) on edge devices.
- The researchers developed techniques to improve the efficiency of ViT inference, including model quantization, custom hardware accelerator design, and compiler-based optimizations.
- The CHOSEN system is designed to enable high-performance and energy-efficient ViT inference on resource-constrained hardware like FPGAs and mobile SoCs.
Plain English Explanation
The paper focuses on a system called CHOSEN that is designed to run Vision Transformer (ViT) models efficiently on edge devices like phones and embedded systems. ViTs are a type of machine learning model that have shown good performance on image recognition tasks, but they can be computationally intensive, making them challenging to run on hardware with limited resources.
To address this, the researchers developed various techniques to optimize ViT inference. This includes model quantization, where the model's precision is reduced to require less memory and computation. They also designed a custom hardware accelerator and used a compiler to further optimize the model for the target hardware.
The goal of CHOSEN is to enable high-performance and energy-efficient ViT inference on edge devices, which could unlock new applications for ViT models in areas like mobile, IoT, and embedded systems. By tailoring the models and hardware to work well together, the researchers were able to achieve significant improvements in latency and power consumption compared to running ViTs on general-purpose hardware.
Technical Explanation
The key elements of the CHOSEN system include:
-
Model Quantization: The researchers applied model quantization techniques to reduce the precision of ViT weights and activations, which reduces memory usage and computation requirements.
-
Custom Hardware Accelerator: CHOSEN includes a custom hardware accelerator design that is optimized for efficient ViT inference. This includes specialized compute units and memory architectures to take advantage of the unique structure of ViTs.
-
Compiler-based Optimizations: The researchers developed a compiler-based optimization stack that can further optimize the ViT model for the target hardware platform, leveraging techniques like channel pruning and approximation of non-linearities.
-
Hardware-software Co-design: By co-designing the model, hardware accelerator, and compiler, the CHOSEN system is able to achieve significant improvements in latency and power consumption compared to running ViTs on general-purpose hardware, as demonstrated in the FPGA-based accelerator work.
Critical Analysis
The paper provides a comprehensive approach to optimizing ViT inference for edge devices, but there are a few potential areas for further research and consideration:
-
Generalization to Other Model Architectures: While the focus is on ViTs, it would be interesting to see how the CHOSEN techniques could be applied to other types of transformer-based models, such as TrioViT, to broaden the applicability of the system.
-
Real-world Deployment Challenges: The paper evaluates CHOSEN on benchmark datasets and hardware platforms, but real-world deployment on edge devices may introduce additional challenges around system integration, power management, and thermal constraints that are not fully addressed.
-
Scalability and Flexibility: As ViT models continue to grow in size and complexity, it will be important to ensure the CHOSEN system can scale effectively and adapt to future model developments without requiring significant engineering effort.
Overall, the CHOSEN system represents an important step towards enabling efficient ViT inference on resource-constrained edge devices, and the techniques developed could have broader applicability in the field of efficient deep learning inference.
Conclusion
The CHOSEN system provides a comprehensive approach to optimizing Vision Transformer (ViT) inference for edge devices, combining model quantization, custom hardware acceleration, and compiler-based optimizations. By co-designing the models, hardware, and software, the researchers were able to achieve significant improvements in latency and power consumption compared to running ViTs on general-purpose hardware.
This work unlocks new opportunities for deploying ViT models in mobile, IoT, and embedded applications, where efficient inference is critical. The techniques developed in CHOSEN could also be applied to other types of transformer-based models, further expanding the impact of this research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CHOSEN: Compilation to Hardware Optimization Stack for Efficient Vision Transformer Inference
Mohammad Erfan Sadeghi, Arash Fayyazi, Suhas Somashekar, Massoud Pedram
Vision Transformers (ViTs) represent a groundbreaking shift in machine learning approaches to computer vision. Unlike traditional approaches, ViTs employ the self-attention mechanism, which has been widely used in natural language processing, to analyze image patches. Despite their advantages in modeling visual tasks, deploying ViTs on hardware platforms, notably Field-Programmable Gate Arrays (FPGAs), introduces considerable challenges. These challenges stem primarily from the non-linear calculations and high computational and memory demands of ViTs. This paper introduces CHOSEN, a software-hardware co-design framework to address these challenges and offer an automated framework for ViT deployment on the FPGAs in order to maximize performance. Our framework is built upon three fundamental contributions: multi-kernel design to maximize the bandwidth, mainly targeting benefits of multi DDR memory banks, approximate non-linear functions that exhibit minimal accuracy degradation, and efficient use of available logic blocks on the FPGA, and efficient compiler to maximize the performance and memory-efficiency of the computing kernels by presenting a novel algorithm for design space exploration to find optimal hardware configuration that achieves optimal throughput and latency. Compared to the state-of-the-art ViT accelerators, CHOSEN achieves a 1.5x and 1.42x improvement in the throughput on the DeiT-S and DeiT-B models.
Read more7/26/2024
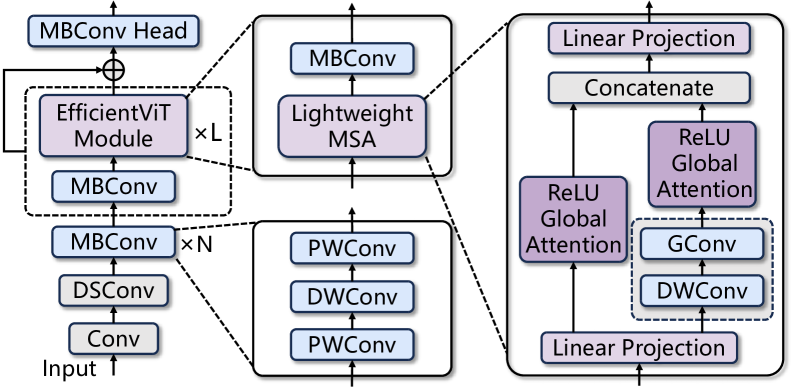
0
An FPGA-Based Reconfigurable Accelerator for Convolution-Transformer Hybrid EfficientViT
Haikuo Shao, Huihong Shi, Wendong Mao, Zhongfeng Wang
Vision Transformers (ViTs) have achieved significant success in computer vision. However, their intensive computations and massive memory footprint challenge ViTs' deployment on embedded devices, calling for efficient ViTs. Among them, EfficientViT, the state-of-the-art one, features a Convolution-Transformer hybrid architecture, enhancing both accuracy and hardware efficiency. Unfortunately, existing accelerators cannot fully exploit the hardware benefits of EfficientViT due to its unique architecture. In this paper, we propose an FPGA-based accelerator for EfficientViT to advance the hardware efficiency frontier of ViTs. Specifically, we design a reconfigurable architecture to efficiently support various operation types, including lightweight convolutions and attention, boosting hardware utilization. Additionally, we present a time-multiplexed and pipelined dataflow to facilitate both intra- and inter-layer fusions, reducing off-chip data access costs. Experimental results show that our accelerator achieves up to 780.2 GOPS in throughput and 105.1 GOPS/W in energy efficiency at 200MHz on the Xilinx ZCU102 FPGA, which significantly outperforms prior works.
Read more4/1/2024
📈
0
Model Quantization and Hardware Acceleration for Vision Transformers: A Comprehensive Survey
Dayou Du, Gu Gong, Xiaowen Chu
Vision Transformers (ViTs) have recently garnered considerable attention, emerging as a promising alternative to convolutional neural networks (CNNs) in several vision-related applications. However, their large model sizes and high computational and memory demands hinder deployment, especially on resource-constrained devices. This underscores the necessity of algorithm-hardware co-design specific to ViTs, aiming to optimize their performance by tailoring both the algorithmic structure and the underlying hardware accelerator to each other's strengths. Model quantization, by converting high-precision numbers to lower-precision, reduces the computational demands and memory needs of ViTs, allowing the creation of hardware specifically optimized for these quantized algorithms, boosting efficiency. This article provides a comprehensive survey of ViTs quantization and its hardware acceleration. We first delve into the unique architectural attributes of ViTs and their runtime characteristics. Subsequently, we examine the fundamental principles of model quantization, followed by a comparative analysis of the state-of-the-art quantization techniques for ViTs. Additionally, we explore the hardware acceleration of quantized ViTs, highlighting the importance of hardware-friendly algorithm design. In conclusion, this article will discuss ongoing challenges and future research paths. We consistently maintain the related open-source materials at https://github.com/DD-DuDa/awesome-vit-quantization-acceleration.
Read more5/2/2024

0
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Zhengang Li, Alec Lu, Yanyue Xie, Zhenglun Kong, Mengshu Sun, Hao Tang, Zhong Jia Xue, Peiyan Dong, Caiwen Ding, Yanzhi Wang, Xue Lin, Zhenman Fang
Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.
Read more7/26/2024