CIBench: Evaluating Your LLMs with a Code Interpreter Plugin

0
Sign in to get full access
Overview
• This paper introduces CIBench, a new benchmark for evaluating the code editing capabilities of large language models (LLMs).
• CIBench provides a set of tasks and metrics to assess an LLM's ability to understand, generate, and modify code.
• The authors demonstrate the use of CIBench on several popular LLMs, revealing insights into their strengths and weaknesses in code-related tasks.
• CIBench aims to complement other code-focused benchmarks like CodeEditorBench, LiveCodeBench, InfiBench, and RealHumanEval to provide a more comprehensive evaluation of LLMs in the code domain.
Plain English Explanation
CIBench is a new tool that allows researchers and developers to test how well large language models (LLMs) can work with computer code. LLMs are AI systems that have been trained on massive amounts of text data, and they can be used for a variety of tasks like generating human-like text, answering questions, and even writing code.
The CIBench tool provides a set of tasks and metrics that can be used to evaluate an LLM's ability to understand, generate, and modify code. For example, the tool might ask the LLM to fix a bug in some code, or to explain what a certain piece of code does. By testing the LLM on these types of tasks, researchers can get a better sense of its strengths and weaknesses when it comes to working with code.
CIBench is designed to complement other benchmarks that focus on code-related tasks, such as CodeEditorBench, LiveCodeBench, InfiBench, and RealHumanEval. By using a variety of benchmarks, researchers can get a more complete picture of an LLM's capabilities when it comes to working with code.
Technical Explanation
The paper introduces CIBench, a new benchmark for evaluating the code editing capabilities of large language models (LLMs). CIBench consists of a set of tasks and metrics designed to assess an LLM's ability to understand, generate, and modify code.
The tasks in CIBench cover a range of code-related activities, such as code summarization, code translation, and code error correction. For each task, the benchmark provides a set of input-output examples, which are used to evaluate the LLM's performance.
To demonstrate the use of CIBench, the authors evaluated several popular LLMs, including GPT-3, CodeT5, and InCoder. The results show that while these models perform well on some code-related tasks, they struggle with others, particularly when it comes to complex code modifications.
The authors argue that CIBench complements other code-focused benchmarks, such as CodeEditorBench, LiveCodeBench, InfiBench, and RealHumanEval, by providing a more comprehensive evaluation of LLMs in the code domain.
Critical Analysis
The authors acknowledge several limitations of CIBench, such as the relatively small number of tasks and the potential for language model biases to influence the results. They also note that the benchmark does not capture the full range of code-related activities that LLMs may be required to perform in real-world scenarios.
Additionally, the paper does not provide a detailed analysis of the specific strengths and weaknesses of the evaluated LLMs, which could have provided more insights into the capabilities and limitations of these models when it comes to code-related tasks.
While CIBench represents a valuable contribution to the field of LLM evaluation, further research is needed to fully understand the code-related capabilities of these models and to develop more comprehensive benchmarks that capture the complexity of the code domain.
Conclusion
The CIBench benchmark introduced in this paper represents an important step towards a more comprehensive evaluation of large language models' capabilities in the code domain. By providing a set of tasks and metrics focused on code understanding, generation, and modification, CIBench complements existing code-focused benchmarks and helps researchers and developers gain a better understanding of the strengths and weaknesses of LLMs when it comes to working with code.
The insights gained from using CIBench can inform the development of more capable and reliable LLMs for a variety of code-related applications, from automated code generation to code maintenance and refactoring. As the field of AI continues to advance, tools like CIBench will play a crucial role in ensuring that these powerful models are able to effectively and reliably handle the complexities of the code domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CIBench: Evaluating Your LLMs with a Code Interpreter Plugin
Songyang Zhang, Chuyu Zhang, Yingfan Hu, Haowen Shen, Kuikun Liu, Zerun Ma, Fengzhe Zhou, Wenwei Zhang, Xuming He, Dahua Lin, Kai Chen
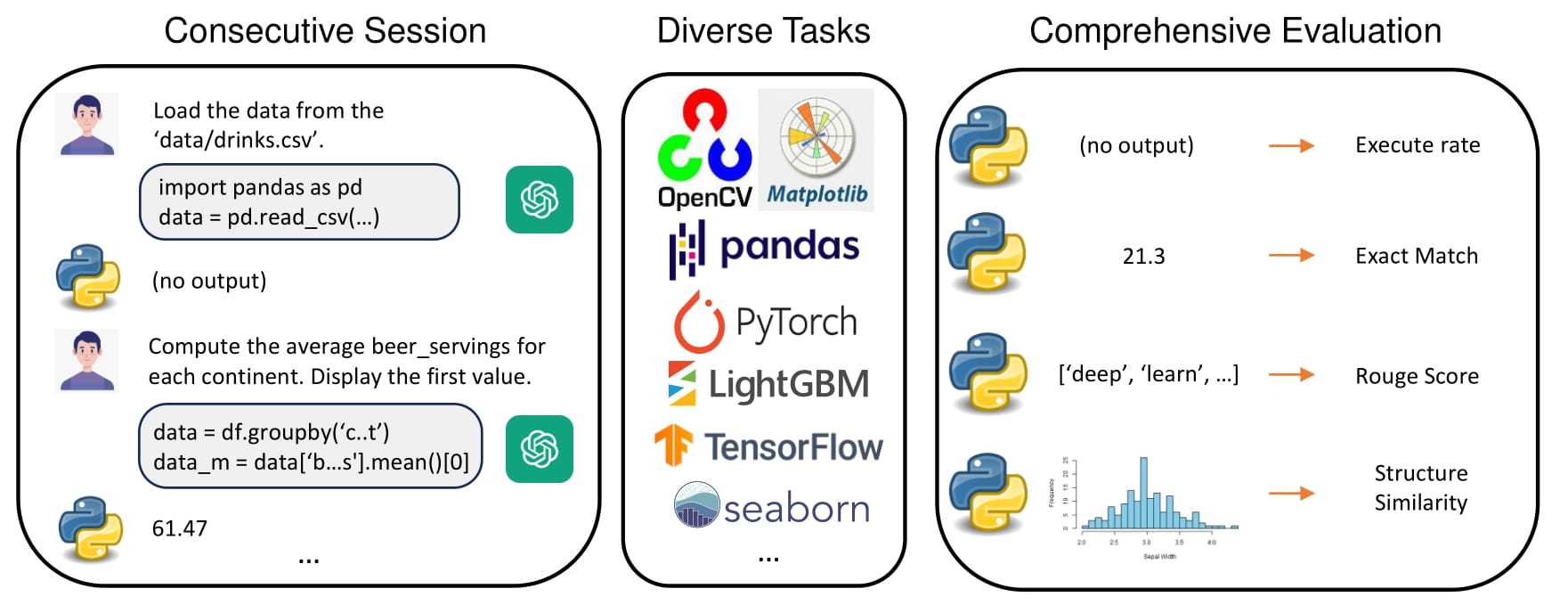
While LLM-Based agents, which use external tools to solve complex problems, have made significant progress, benchmarking their ability is challenging, thereby hindering a clear understanding of their limitations. In this paper, we propose an interactive evaluation framework, named CIBench, to comprehensively assess LLMs' ability to utilize code interpreters for data science tasks. Our evaluation framework includes an evaluation dataset and two evaluation modes. The evaluation dataset is constructed using an LLM-human cooperative approach and simulates an authentic workflow by leveraging consecutive and interactive IPython sessions. The two evaluation modes assess LLMs' ability with and without human assistance. We conduct extensive experiments to analyze the ability of 24 LLMs on CIBench and provide valuable insights for future LLMs in code interpreter utilization.
Read more7/26/2024

0
PyBench: Evaluating LLM Agent on various real-world coding tasks
Yaolun Zhang, Yinxu Pan, Yudong Wang, Jie Cai, Zhi Zheng, Guoyang Zeng, Zhiyuan Liu
The LLM Agent, equipped with a code interpreter, is capable of automatically solving real-world coding tasks, such as data analysis and image editing. However, existing benchmarks primarily focus on either simplistic tasks, such as completing a few lines of code, or on extremely complex and specific tasks at the repository level, neither of which are representative of various daily coding tasks. To address this gap, we introduce textbf{PyBench}, a benchmark encompassing five main categories of real-world tasks, covering more than 10 types of files. Given a high-level user query and related files, the LLM Agent needs to reason and execute Python code via a code interpreter for a few turns before making a formal response to fulfill the user's requirements. Successfully addressing tasks in PyBench demands a robust understanding of various Python packages, superior reasoning capabilities, and the ability to incorporate feedback from executed code. Our evaluations indicate that current open-source LLMs are struggling with these tasks. Hence, we conduct analysis and experiments on four kinds of datasets proving that comprehensive abilities are needed for PyBench. Our fine-tuned 8B size model: textbf{PyLlama3} achieves an exciting performance on PyBench which surpasses many 33B and 70B size models. Our Benchmark, Training Dataset, and Model are available at: href{https://github.com/Mercury7353/PyBench}{https://github.com/Mercury7353/PyBench}
Read more7/25/2024
0
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
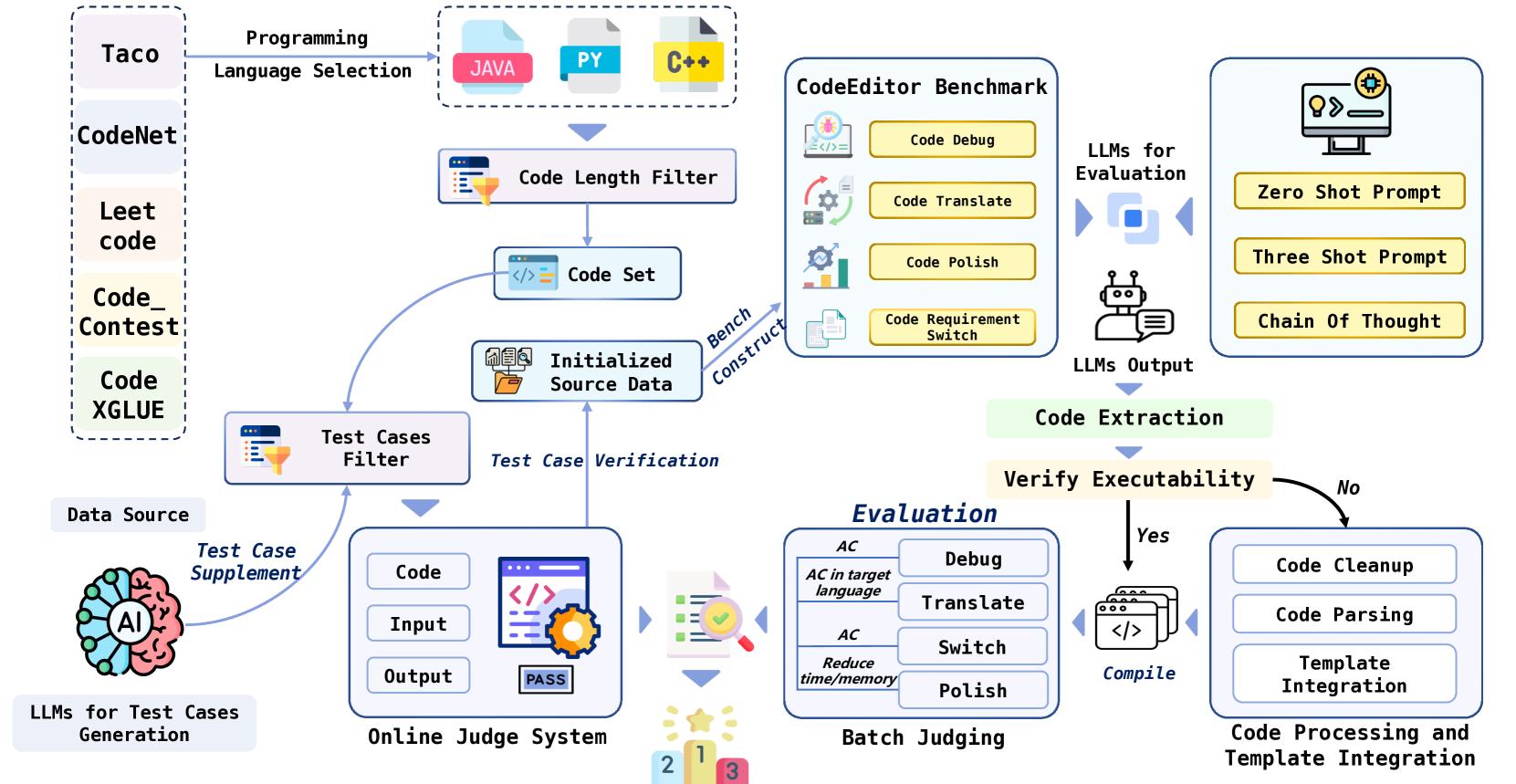
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Read more4/9/2024
1
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica
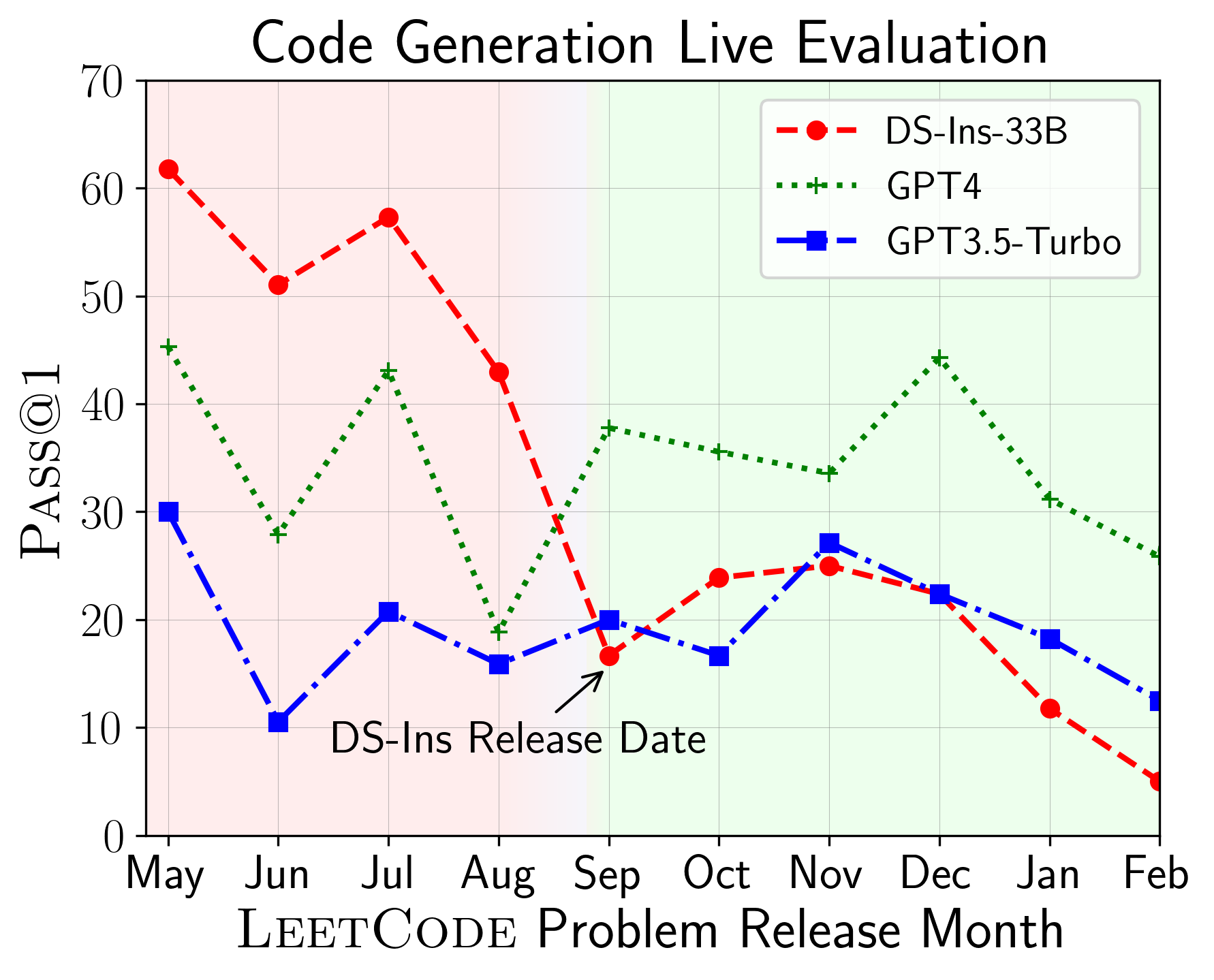
Large Language Models (LLMs) applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and May 2024. We have evaluated 18 base LLMs and 34 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model
Read more6/7/2024