InfiCoder-Eval: Systematically Evaluating the Question-Answering Capabilities of Code Large Language Models
2404.07940
0
0

Abstract
Large Language Models for code (code LLMs) have witnessed tremendous progress in recent years. With the rapid development of code LLMs, many popular evaluation benchmarks, such as HumanEval, DS-1000, and MBPP, have emerged to measure the performance of code LLMs with a particular focus on code generation tasks. However, they are insufficient to cover the full range of expected capabilities of code LLMs, which span beyond code generation to answering diverse coding-related questions. To fill this gap, we propose InfiBench, the first large-scale freeform question-answering (QA) benchmark for code to our knowledge, comprising 234 carefully selected high-quality Stack Overflow questions that span across 15 programming languages. InfiBench uses four types of model-free automatic metrics to evaluate response correctness where domain experts carefully concretize the criterion for each question. We conduct a systematic evaluation for over 100 latest code LLMs on InfiBench, leading to a series of novel and insightful findings. Our detailed analyses showcase potential directions for further advancement of code LLMs. InfiBench is fully open source and continuously expanding to foster more scientific and systematic practices for code LLM evaluation.
Create account to get full access
Overview
- This paper introduces InfiCoder-Eval, a benchmark for systematically evaluating the question-answering capabilities of code-centric large language models (LLMs).
- The benchmark covers a diverse range of coding-related questions, including understanding code, algorithm design, and software engineering principles.
- The authors evaluate several state-of-the-art LLMs on InfiCoder-Eval and provide insights into their performance and limitations.
Plain English Explanation
The researchers have developed a new benchmark called InfiCoder-Eval to test the ability of large language models (LLMs) to answer questions about computer programming. LLMs are AI systems that can generate human-like text, and the researchers wanted to see how well these models can understand and answer questions related to coding, algorithms, and software engineering.
The benchmark covers a wide range of programming-related topics, such as understanding the meaning of code snippets, designing algorithms to solve specific problems, and applying software engineering principles. The researchers tested several state-of-the-art LLMs on this benchmark and analyzed their performance. This helps to identify the strengths and weaknesses of these models when it comes to reasoning about code and programming concepts.
Technical Explanation
The paper introduces the InfiCoder-Eval benchmark, which is designed to systematically evaluate the question-answering capabilities of code-centric large language models (LLMs). The benchmark covers a diverse range of coding-related questions, including understanding code, algorithm design, and software engineering principles.
To create the benchmark, the authors curated a dataset of programming-related questions from various sources, such as coding interview questions and online programming forums. They then used crowdsourcing to filter and refine the questions to ensure they are well-defined, unambiguous, and cover a broad range of topics.
The authors evaluated several state-of-the-art LLMs, including GPT-3, Codex, and InstructGPT, on the InfiCoder-Eval benchmark. They analyzed the models' performance across different question categories and provided insights into their strengths and weaknesses in reasoning about code and programming concepts.
Critical Analysis
The InfiCoder-Eval benchmark represents a valuable contribution to the field of code-centric AI research. By systematically evaluating LLMs on a diverse range of programming-related questions, the authors have provided a comprehensive assessment of the current capabilities and limitations of these models.
One potential limitation of the benchmark is the reliance on crowdsourcing for question curation and refinement. While this approach can help ensure the quality and relevance of the questions, it may also introduce some subjectivity or bias. The authors acknowledge this and suggest further refinement and validation of the benchmark in future work.
Additionally, the evaluation focused on a limited set of state-of-the-art LLMs, and it would be interesting to see how other models, including those specialized for code-related tasks, perform on the benchmark. Expanding the evaluation to a broader range of models could provide a more comprehensive understanding of the field.
Conclusion
The InfiCoder-Eval benchmark represents a significant step forward in the systematic evaluation of code-centric question-answering capabilities of large language models. By assessing the performance of several state-of-the-art LLMs on a diverse set of programming-related questions, the authors have provided valuable insights into the current strengths and limitations of these models in reasoning about code and programming concepts.
The insights gained from this research could inform the development of more capable and robust code-centric AI systems, which could have important implications for various applications, such as automated programming assistance, code generation, and software engineering. The InfiCoder-Eval benchmark serves as a valuable tool for the research community to drive the progress of code-centric AI and better understand the evolving capabilities of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
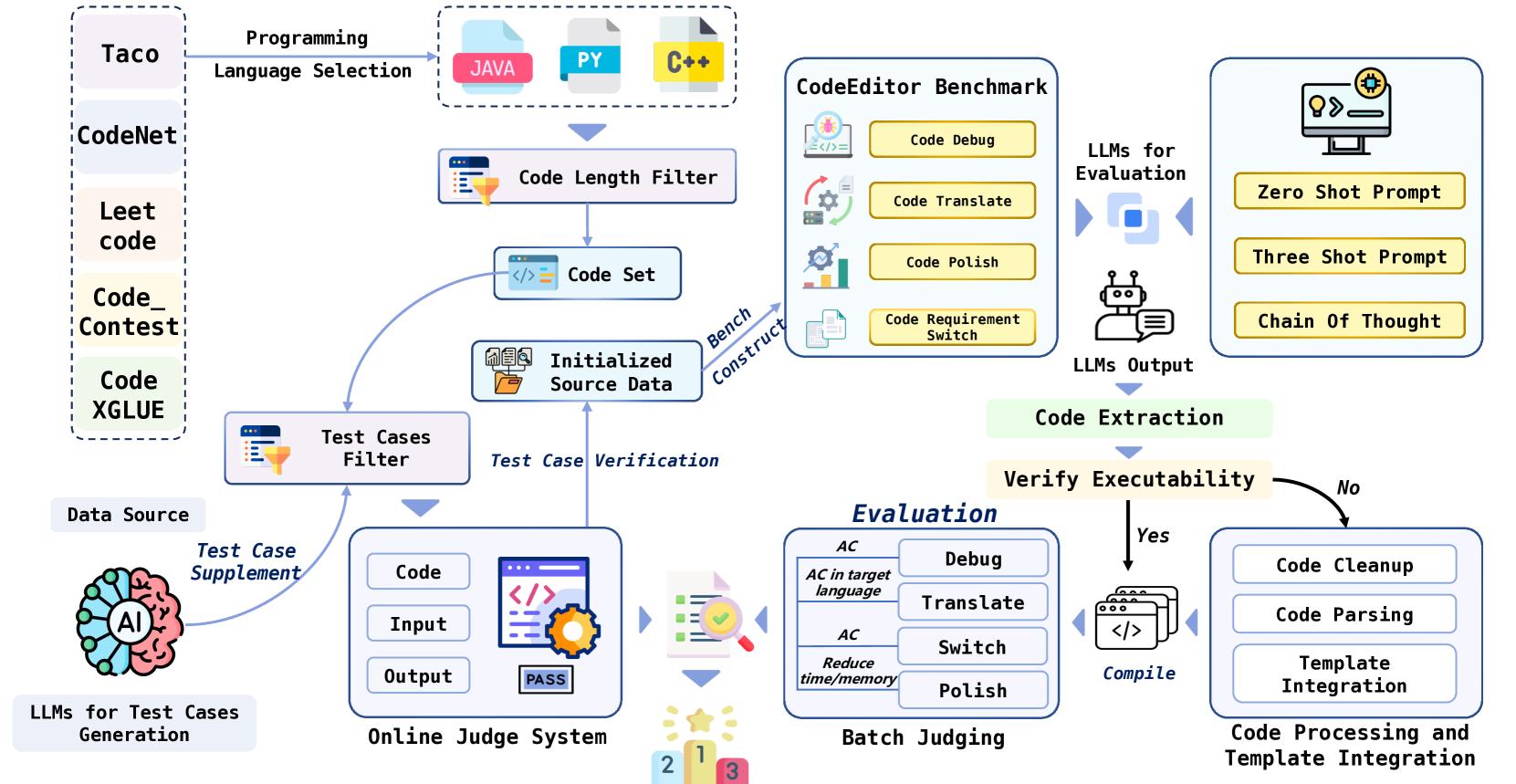
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
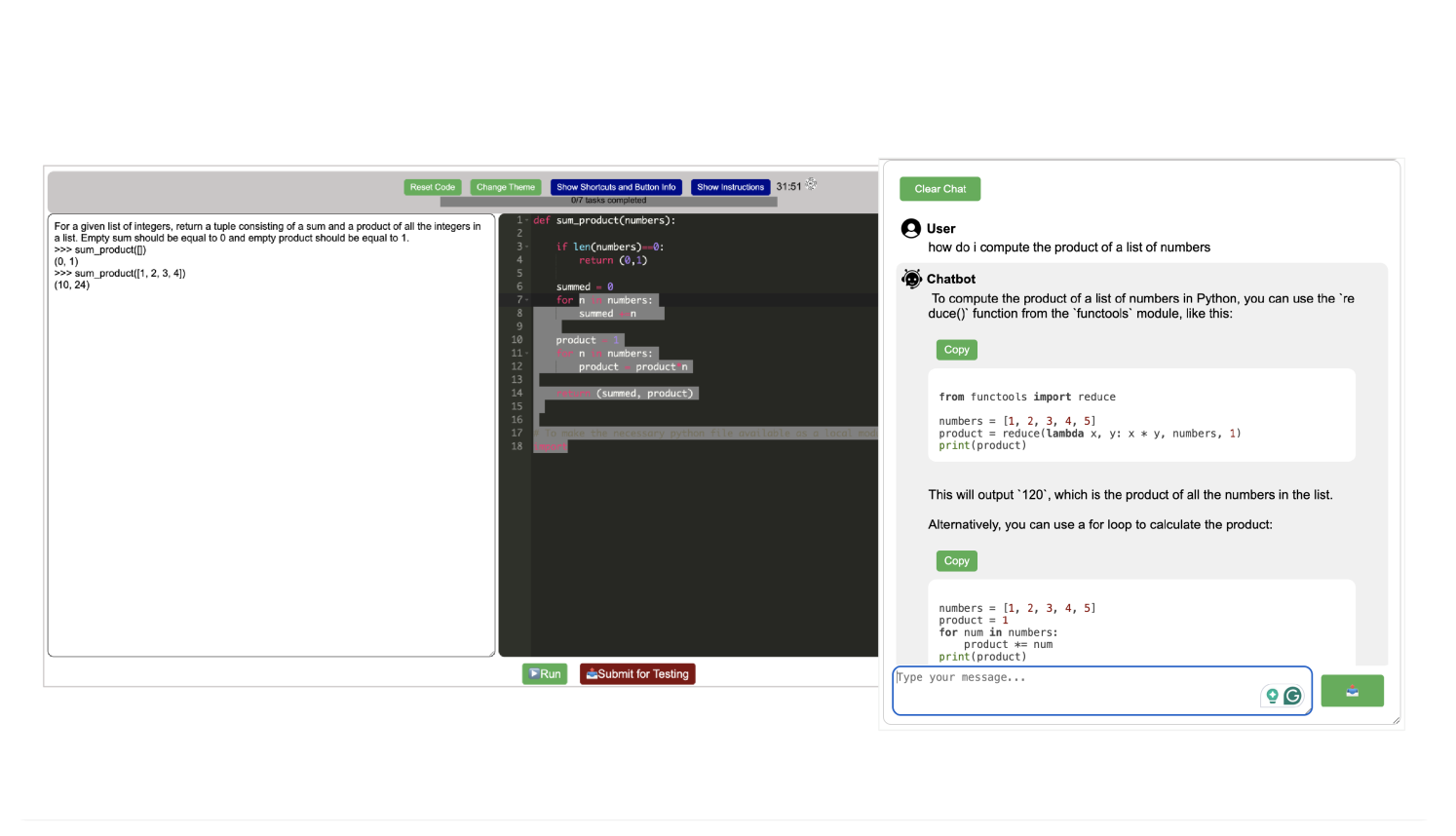
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024
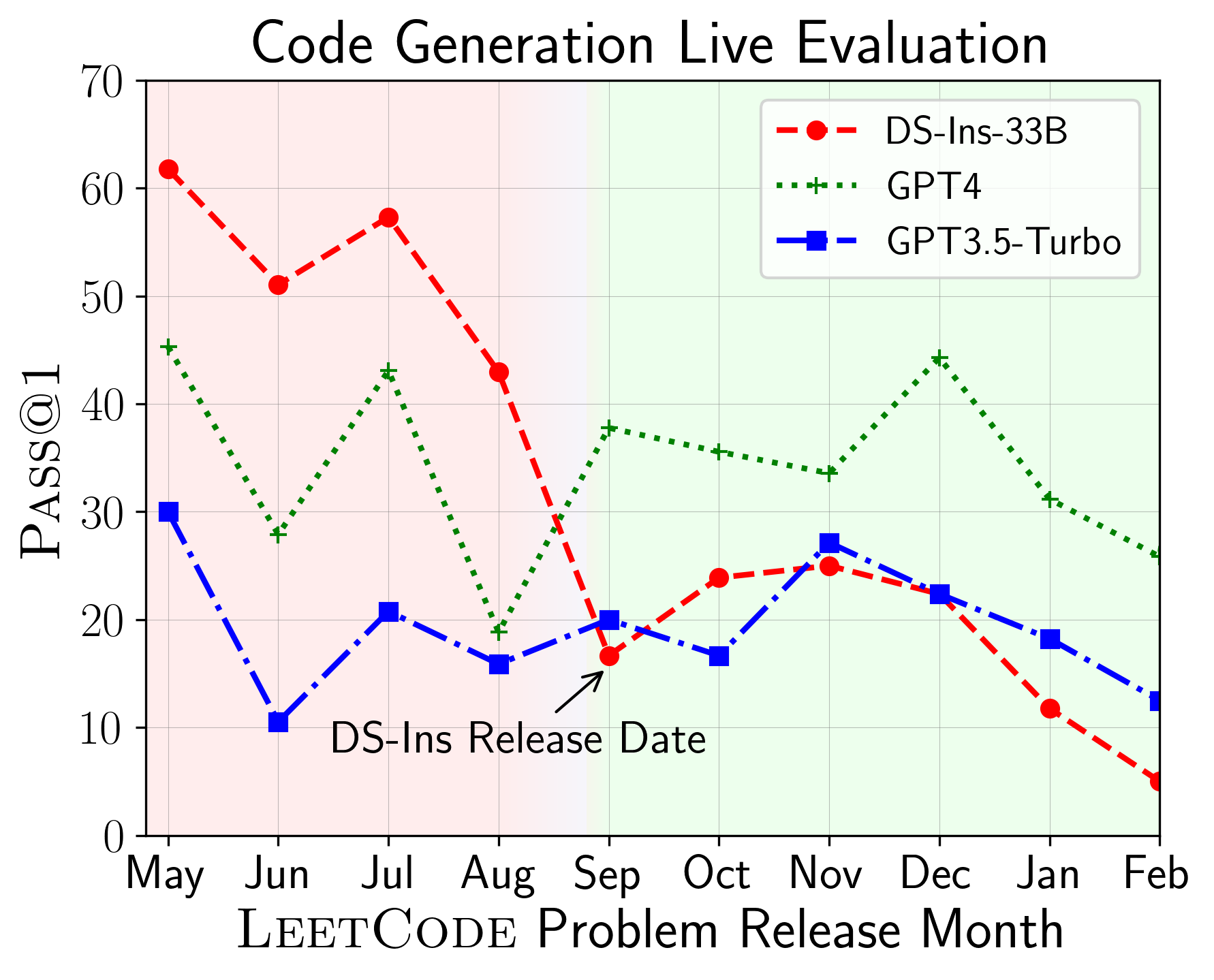
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica
0
0
Large Language Models (LLMs) applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and May 2024. We have evaluated 18 base LLMs and 34 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model
6/7/2024
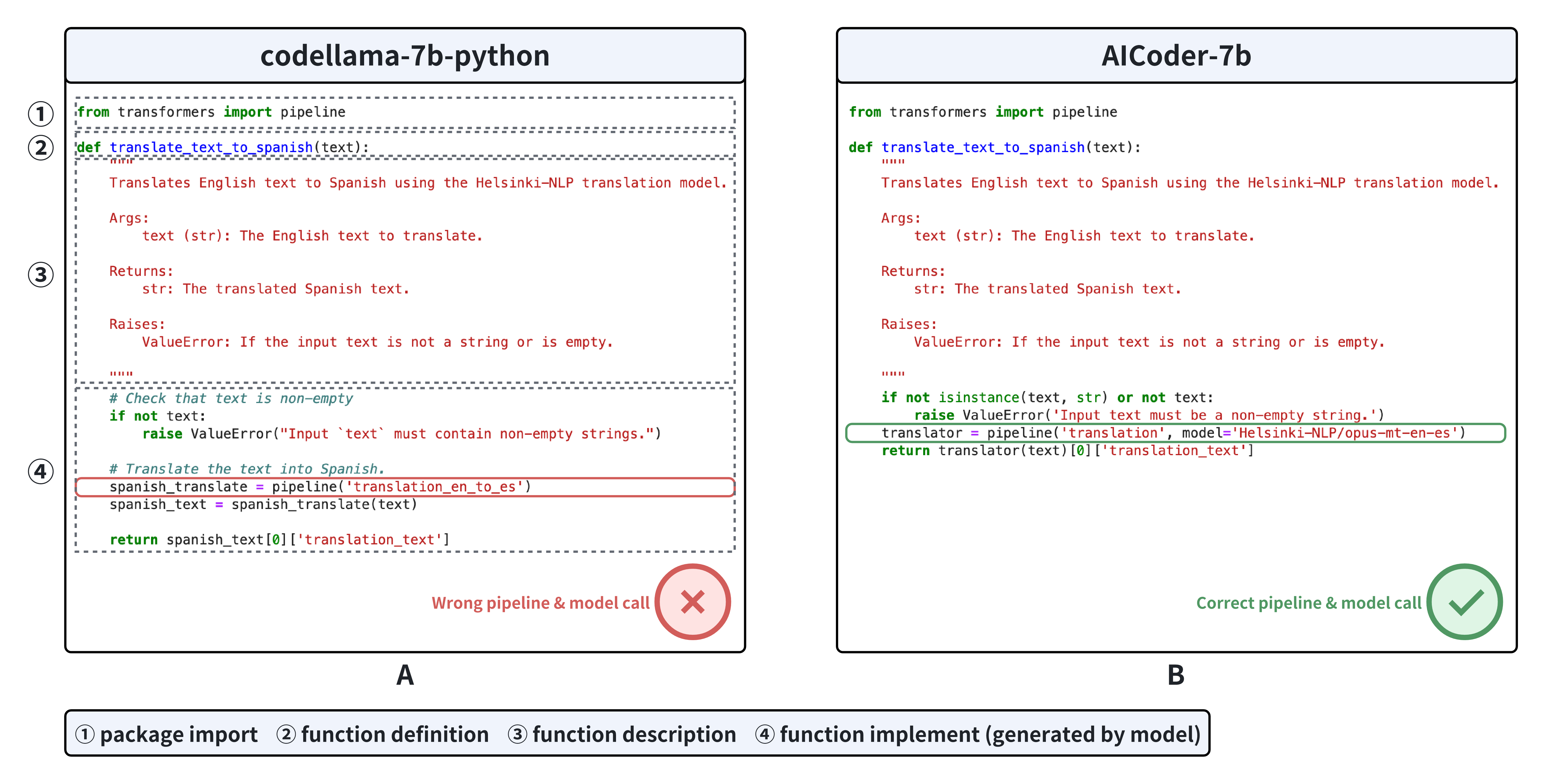
AICoderEval: Improving AI Domain Code Generation of Large Language Models
Yinghui Xia, Yuyan Chen, Tianyu Shi, Jun Wang, Jinsong Yang
0
0
Automated code generation is a pivotal capability of large language models (LLMs). However, assessing this capability in real-world scenarios remains challenging. Previous methods focus more on low-level code generation, such as model loading, instead of generating high-level codes catering for real-world tasks, such as image-to-text, text classification, in various domains. Therefore, we construct AICoderEval, a dataset focused on real-world tasks in various domains based on HuggingFace, PyTorch, and TensorFlow, along with comprehensive metrics for evaluation and enhancing LLMs' task-specific code generation capability. AICoderEval contains test cases and complete programs for automated evaluation of these tasks, covering domains such as natural language processing, computer vision, and multimodal learning. To facilitate research in this area, we open-source the AICoderEval dataset at url{https://huggingface.co/datasets/vixuowis/AICoderEval}. After that, we propose CoderGen, an agent-based framework, to help LLMs generate codes related to real-world tasks on the constructed AICoderEval. Moreover, we train a more powerful task-specific code generation model, named AICoder, which is refined on llama-3 based on AICoderEval. Our experiments demonstrate the effectiveness of CoderGen in improving LLMs' task-specific code generation capability (by 12.00% on pass@1 for original model and 9.50% on pass@1 for ReAct Agent). AICoder also outperforms current code generation LLMs, indicating the great quality of the AICoderEval benchmark.
6/10/2024