A User-Centric Benchmark for Evaluating Large Language Models
2404.13940
0
0

Abstract
Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
Create account to get full access
Overview
- This paper proposes a user-centric benchmark for evaluating the capabilities of large language models (LLMs).
- The benchmark aims to assess how well LLMs can assist users in completing real-world tasks, moving beyond traditional evaluation metrics.
- The authors develop a set of user-centric tasks and evaluation criteria to better understand the practical utility of LLMs.
Plain English Explanation
The paper introduces a new way to evaluate large language models (LLMs) - the AI systems that can understand and generate human-like text. Traditionally, LLMs have been assessed using metrics like their ability to predict the next word in a sentence or summarize a passage of text. However, the authors argue that these metrics don't fully capture how well LLMs can actually assist people with real-world tasks.
To address this, the researchers developed a "user-centric benchmark" that looks at how well LLMs can help humans complete practical tasks, like writing an email or analyzing data. They created a set of tasks that reflect the types of things people might want an AI assistant to help with, and then evaluated how well different LLMs performed on those tasks.
The key insight is that evaluating LLMs based on how useful they are to actual users is more meaningful than just looking at their language skills in isolation. This user-centric approach provides a more realistic assessment of an LLM's capabilities and practical utility.
Technical Explanation
The paper proposes a user-centric benchmark for evaluating large language models (LLMs). Traditional LLM evaluation metrics, such as perplexity and BLEU, focus on language modeling performance but do not capture an LLM's ability to assist users in real-world tasks.
To address this, the authors developed a set of user-centric tasks and evaluation criteria. The tasks span areas like writing, analysis, and research assistance, and are designed to reflect the types of activities users might want an LLM to help with. The evaluation criteria assess factors like task completion, usefulness, and user satisfaction.
By focusing on user-centric metrics, the authors aim to provide a more realistic and comprehensive assessment of LLM capabilities that goes beyond traditional language modeling performance.
Critical Analysis
The paper presents a thoughtful approach to evaluating LLMs from a user-centric perspective. The authors acknowledge the limitations of existing evaluation metrics and make a compelling case for the importance of assessing LLMs' practical utility.
One potential concern is the subjectivity inherent in user-centric evaluations. The authors acknowledge this challenge and outline strategies for ensuring consistency and reliability, but further research may be needed to refine the evaluation methodology.
Additionally, the paper focuses on a relatively narrow set of tasks, which may not fully capture the diverse ways users might want to leverage LLMs. Expanding the task set and evaluating LLMs across a wider range of applications could provide a more comprehensive understanding of their capabilities.
Overall, the user-centric benchmark introduced in this paper represents a valuable contribution to the ongoing efforts to measure and improve the performance of large language models.
Conclusion
This paper proposes a user-centric benchmark for evaluating large language models (LLMs), moving beyond traditional evaluation metrics focused on language modeling performance. By assessing how well LLMs can assist users in completing real-world tasks, the authors aim to provide a more realistic and comprehensive understanding of LLM capabilities and practical utility.
The user-centric benchmark and evaluation criteria introduced in this work represent an important step forward in the ongoing efforts to develop and improve large language models that can effectively support human users in a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
Shijue Huang, Wanjun Zhong, Jianqiao Lu, Qi Zhu, Jiahui Gao, Weiwen Liu, Yutai Hou, Xingshan Zeng, Yasheng Wang, Lifeng Shang, Xin Jiang, Ruifeng Xu, Qun Liu
0
0
The recent trend of using Large Language Models (LLMs) as tool agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools. However, existing benchmarks typically focus on simple synthesized queries that do not reflect real-world complexity, thereby offering limited perspectives in evaluating tool utilization. To address this issue, we present UltraTool, a novel benchmark designed to improve and evaluate LLMs' ability in tool utilization within real-world scenarios. UltraTool focuses on the entire process of using tools - from planning and creating to applying them in complex tasks. It emphasizes real-world complexities, demanding accurate, multi-step planning for effective problem-solving. A key feature of UltraTool is its independent evaluation of planning with natural language, which happens before tool usage and simplifies the task solving by mapping out the intermediate steps. Thus, unlike previous work, it eliminates the restriction of pre-defined toolset. Through extensive experiments on various LLMs, we offer novel insights into the evaluation of capabilities of LLMs in tool utilization, thereby contributing a fresh perspective to this rapidly evolving field. The benchmark is publicly available at https://github.com/JoeYing1019/UltraTool.
6/4/2024

CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jie Feng, Jun Zhang, Junbo Yan, Xin Zhang, Tianjian Ouyang, Tianhui Liu, Yuwei Du, Siqi Guo, Yong Li
0
0
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
6/21/2024
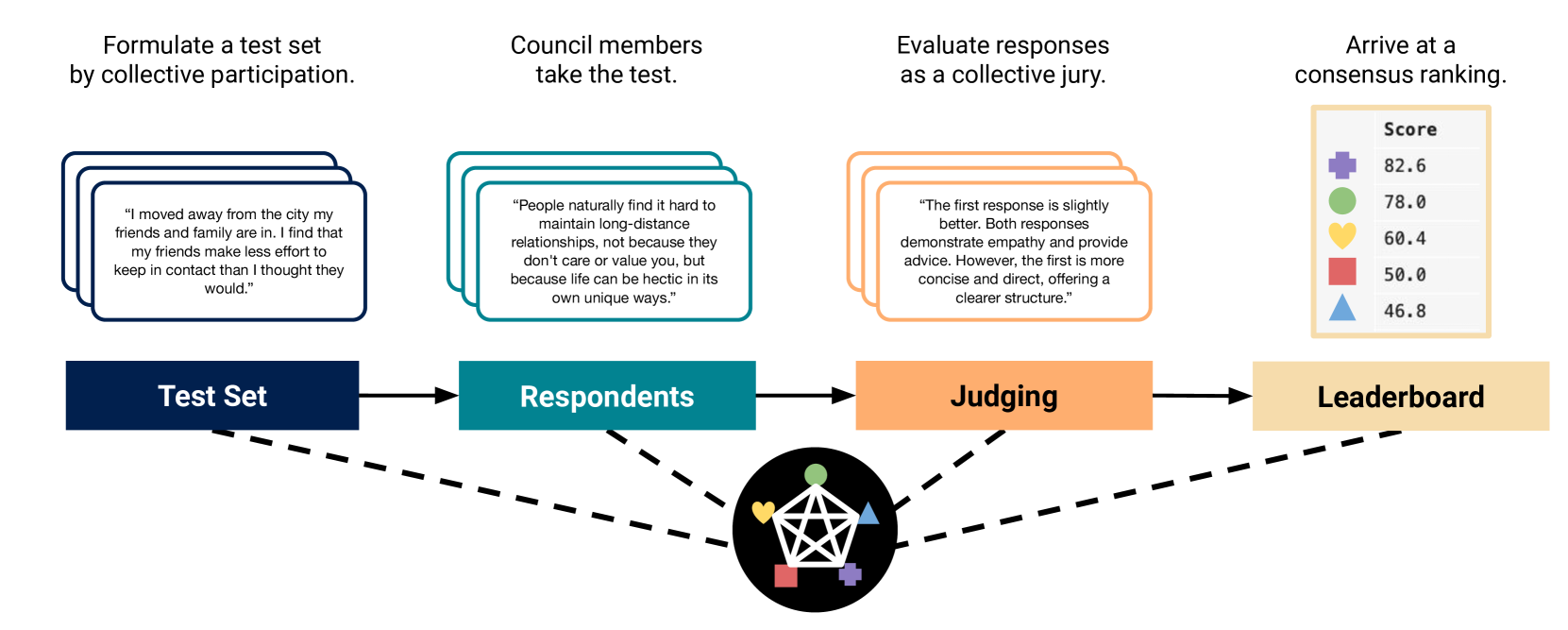
Language Model Council: Benchmarking Foundation Models on Highly Subjective Tasks by Consensus
Justin Zhao, Flor Miriam Plaza-del-Arco, Amanda Cercas Curry
0
0
The rapid advancement of Large Language Models (LLMs) necessitates robust and challenging benchmarks. Leaderboards like Chatbot Arena rank LLMs based on how well their responses align with human preferences. However, many tasks such as those related to emotional intelligence, creative writing, or persuasiveness, are highly subjective and often lack majoritarian human agreement. Judges may have irreconcilable disagreements about what constitutes a better response. To address the challenge of ranking LLMs on highly subjective tasks, we propose a novel benchmarking framework, the Language Model Council (LMC). The LMC operates through a democratic process to: 1) formulate a test set through equal participation, 2) administer the test among council members, and 3) evaluate responses as a collective jury. We deploy a council of 20 newest LLMs on an open-ended emotional intelligence task: responding to interpersonal dilemmas. Our results show that the LMC produces rankings that are more separable, robust, and less biased than those from any individual LLM judge, and is more consistent with a human-established leaderboard compared to other benchmarks.
6/14/2024
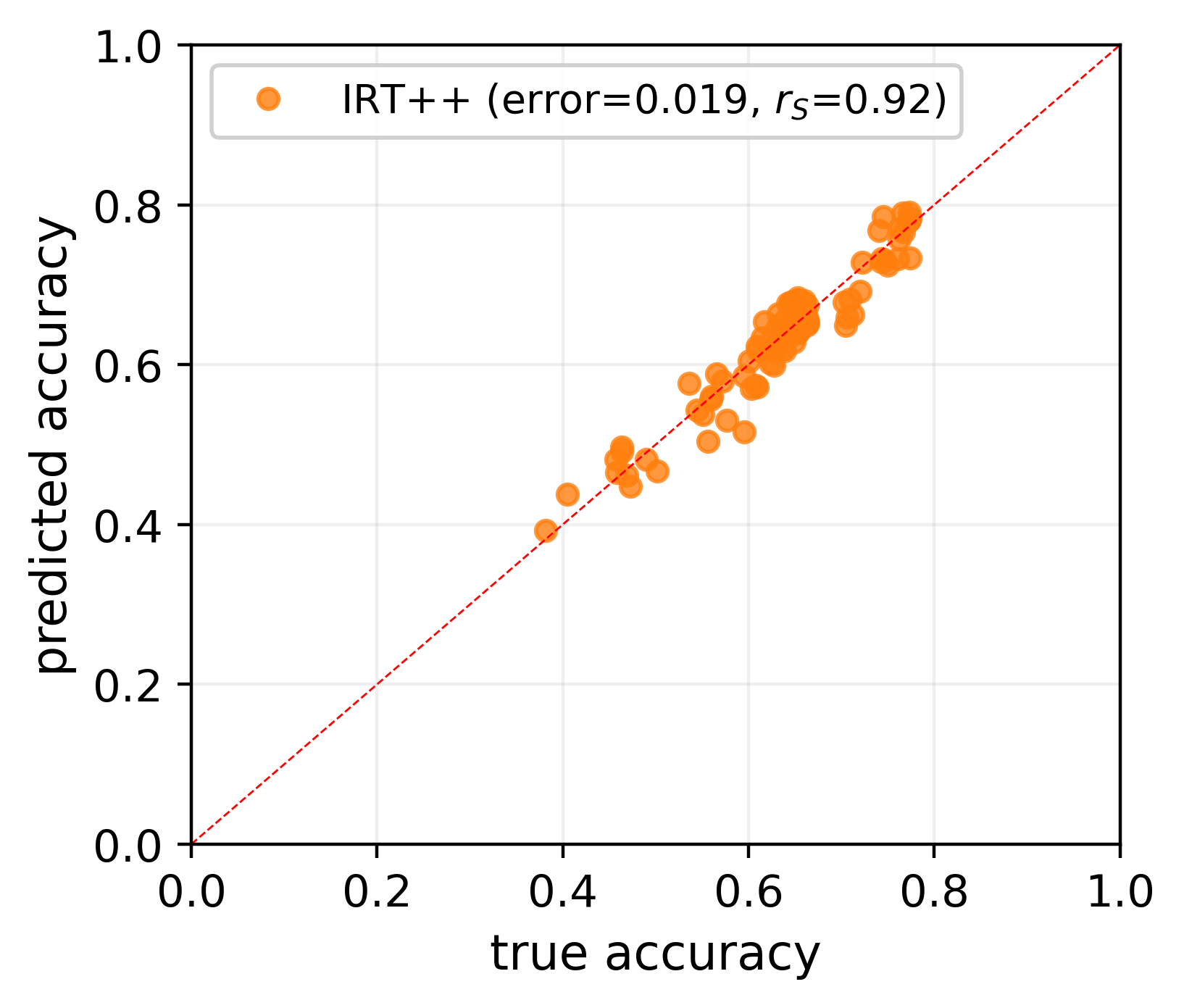
tinyBenchmarks: evaluating LLMs with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, Mikhail Yurochkin
0
0
The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
5/28/2024