RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
2404.03204
0
0
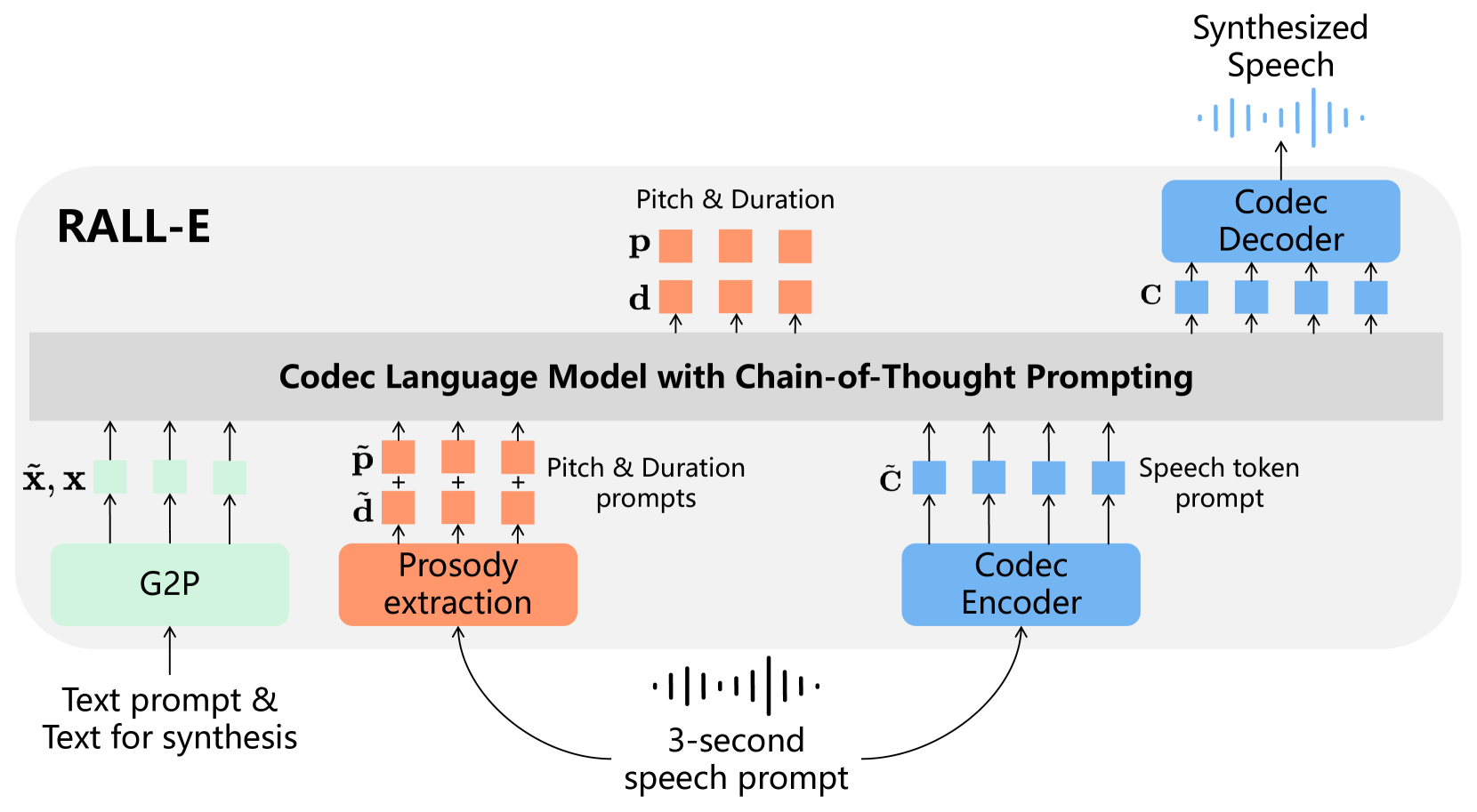
Abstract
We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models. The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style. Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens. Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from $6.3%$ (without reranking) and $2.1%$ (with reranking) to $2.8%$ and $1.0%$, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from $68%$ to $4%$.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces RALL-E, a new approach to text-to-speech (TTS) synthesis that leverages large language models (LLMs) and chain-of-thought prompting to improve the robustness and quality of TTS systems.
- The key innovations of RALL-E include a novel codec language model that can capture the complex relationships between textual inputs and speech outputs, as well as a chain-of-thought prompting technique that helps the model reason through the synthesis process step-by-step.
- The authors demonstrate that RALL-E outperforms existing TTS approaches on a range of objective and subjective metrics, highlighting its potential to enable more natural and expressive speech synthesis.
Plain English Explanation
The authors of this paper have developed a new text-to-speech system called RALL-E that aims to produce more natural and high-quality speech. Traditional text-to-speech systems often struggle with complex or ambiguous inputs, leading to robotic or unnatural-sounding speech.
To address this, the researchers leveraged the power of large language models (LLMs) - AI systems trained on vast amounts of text data that can understand and generate human-like language. They created a specialized "codec language model" within RALL-E that can better capture the intricate connections between written text and spoken speech.
Additionally, RALL-E uses a "chain-of-thought" prompting approach, where the system is guided to thoughtfully consider the steps involved in converting text to speech, rather than simply trying to generate the audio directly. This step-by-step reasoning process helps the model produce more coherent and natural-sounding speech.
Through extensive testing, the authors show that RALL-E outperforms other state-of-the-art text-to-speech systems in terms of both objective metrics (like audio quality) and subjective ratings (how natural the speech sounds to human listeners). This suggests that RALL-E could be a significant advancement in making text-to-speech technology more robust and expressive, with potential applications in areas like digital assistants, audiobooks, and media production.
Technical Explanation
The core innovation of RALL-E is the use of a specialized "codec language model" that can better capture the complex relationships between textual inputs and speech outputs. This codec model is trained on a large corpus of text-audio pairs, allowing it to learn the intricate patterns and dependencies involved in text-to-speech conversion.
In addition, RALL-E leverages chain-of-thought prompting, a technique where the system is guided to reason through the text-to-speech process step-by-step. This helps the model better understand the semantic and phonetic aspects of the input text, leading to more coherent and natural-sounding speech synthesis.
The authors evaluate RALL-E on a range of objective and subjective metrics, showing that it outperforms existing LLM-based TTS approaches as well as traditional TTS systems. They also demonstrate RALL-E's ability to handle challenging inputs, such as complex sentences or rare words, that often trip up other TTS models.
Critical Analysis
The authors acknowledge several limitations of RALL-E, including the need for a large and diverse training dataset to fully capture the complexities of text-to-speech conversion. They also note that the chain-of-thought prompting approach adds computational overhead, which could be a concern for real-time applications.
Additionally, while RALL-E shows promising results, the paper does not provide a detailed analysis of the model's errors or failure cases. It would be valuable to understand the types of inputs or scenarios where RALL-E still struggles, as this could inform future research and development.
Some readers may also be interested in further exploring the relationship between LLMs and multimodal tasks, as the success of RALL-E could suggest broader potential for applying large language models to other cross-modal challenges, such as zero-shot emotion-based speech synthesis.
Conclusion
The RALL-E system represents a significant advancement in text-to-speech synthesis, leveraging large language models and chain-of-thought prompting to produce more natural and expressive speech. By better capturing the complex relationships between text and audio, RALL-E has the potential to enable more robust and human-like TTS in a variety of applications, from digital assistants to audiobooks and media production.
While the paper highlights several promising directions, ongoing research will be needed to further improve the capabilities and address the limitations of RALL-E. As language models and multimodal AI continue to evolve, the insights and techniques introduced in this work could have far-reaching implications for the future of speech technology and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech
Jaehyeon Kim, Keon Lee, Seungjun Chung, Jaewoong Cho
0
0
With the emergence of neural audio codecs, which encode multiple streams of discrete tokens from audio, large language models have recently gained attention as a promising approach for zero-shot Text-to-Speech (TTS) synthesis. Despite the ongoing rush towards scaling paradigms, audio tokenization ironically amplifies the scalability challenge, stemming from its long sequence length and the complexity of modelling the multiple sequences. To mitigate these issues, we present CLaM-TTS that employs a probabilistic residual vector quantization to (1) achieve superior compression in the token length, and (2) allow a language model to generate multiple tokens at once, thereby eliminating the need for cascaded modeling to handle the number of token streams. Our experimental results demonstrate that CLaM-TTS is better than or comparable to state-of-the-art neural codec-based TTS models regarding naturalness, intelligibility, speaker similarity, and inference speed. In addition, we examine the impact of the pretraining extent of the language models and their text tokenization strategies on performances.
4/4/2024
💬
Pattern-Aware Chain-of-Thought Prompting in Large Language Models
Yufeng Zhang, Xuepeng Wang, Lingxiang Wu, Jinqiao Wang
0
0
Chain-of-thought (CoT) prompting can guide language models to engage in complex multi-step reasoning. The quality of provided demonstrations significantly impacts the success of downstream inference tasks. While existing automated methods prioritize accuracy and semantics in these demonstrations, we show that the underlying reasoning patterns play a more crucial role in such tasks. In this paper, we propose Pattern-Aware CoT, a prompting method that considers the diversity of demonstration patterns. By incorporating patterns such as step length and reasoning process within intermediate steps, PA-CoT effectively mitigates the issue of bias induced by demonstrations and enables better generalization to diverse scenarios. We conduct experiments on nine reasoning benchmark tasks using two open-source LLMs. The results show that our method substantially enhances reasoning performance and exhibits robustness to errors. The code will be made publicly available.
4/24/2024
❗
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Xiang Li, Zhi-Qi Cheng, Jun-Yan He, Xiaojiang Peng, Alexander G. Hauptmann
0
0
Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily relying on oversimplified emotional labels or single-modality inputs. To address these limitations, we propose the Multimodal Emotional Text-to-Speech System (MM-TTS), a unified framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. MM-TTS consists of two key components: (1) the Emotion Prompt Alignment Module (EP-Align), which employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information; and (2) the Emotion Embedding-Induced TTS (EMI-TTS), which integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations across diverse datasets demonstrate the superior performance of MM-TTS compared to traditional E-TTS models. Objective metrics, including Word Error Rate (WER) and Character Error Rate (CER), show significant improvements on ESD dataset, with MM-TTS achieving scores of 7.35% and 3.07%, respectively. Subjective assessments further validate that MM-TTS generates speech with emotional fidelity and naturalness comparable to human speech. Our code and pre-trained models are publicly available at https://anonymous.4open.science/r/MMTTS-D214
4/30/2024