Class-aware and Augmentation-free Contrastive Learning from Label Proportion

0

Sign in to get full access
Overview
- Learning from label proportion is a form of weakly supervised learning where the true class labels are not available, only the overall proportion of each class in the dataset.
- This paper proposes a new contrastive learning method that can effectively learn from label proportion without requiring data augmentation.
- The method is class-aware, meaning it explicitly takes the class proportions into account during training.
- Experiments show the proposed approach achieves state-of-the-art performance on several benchmark datasets.
Plain English Explanation
In many real-world machine learning problems, it can be difficult or expensive to obtain detailed labels for each data sample. Instead, we may only have access to the overall proportion of each class in the dataset. This is known as learning from label proportion, a type of weakly supervised learning.
The paper introduces a new contrastive learning method that can effectively learn from this kind of partial label information, without needing to rely on data augmentation techniques. Contrastive learning is a powerful approach that trains models to identify similarities and differences between data samples.
The key innovation is that the method is class-aware, meaning it explicitly takes the known class proportions into account during the training process. This allows the model to better leverage the available label information to learn useful representations.
The researchers evaluate their approach on several benchmark datasets and show that it achieves state-of-the-art performance, outperforming other methods for learning from label proportion. This suggests the proposed technique could be valuable in real-world applications where detailed labels are scarce.
Technical Explanation
The paper introduces a new Class-aware and Augmentation-free Contrastive Learning from Label Proportion (CACL) method. CACL is designed to effectively learn from label proportion data, where the true class labels for each sample are unknown, but the overall proportion of each class in the dataset is provided.
The core idea of CACL is to leverage contrastive learning to learn useful representations from the data, while explicitly incorporating the available class proportion information. This is achieved through a novel contrastive loss function that encourages the model to separate samples belonging to different classes, while also aligning the class-conditional representations with the provided class proportions.
Importantly, CACL does not require data augmentation, which is often used in contrastive learning to generate additional training samples. Instead, the class-aware nature of the method allows it to effectively learn without the need for data augmentation.
The authors evaluate CACL on several benchmark datasets for learning from label proportion, including CIFAR-10, CIFAR-100, and ImageNet-LT. They show that CACL outperforms other state-of-the-art methods for learning from label proportion, demonstrating the effectiveness of the proposed approach.
Critical Analysis
The paper presents a novel and promising approach for learning from label proportion, a challenging problem in machine learning. The class-aware contrastive learning method introduced in CACL is an interesting and well-designed solution that effectively leverages the available label proportion information without requiring data augmentation.
One potential limitation is that the method assumes the class proportions are known a priori. In some real-world scenarios, even the class proportions may not be known with certainty. It would be valuable to explore extensions of CACL that can handle uncertain or noisy class proportion information.
Additionally, the paper focuses on image classification tasks, and it would be interesting to see how CACL performs on other types of data, such as tabular data or multi-label problems. Investigating the robustness of CACL to different data distributions and tasks could further demonstrate its broader applicability.
Overall, the CACL method represents an important contribution to the field of weakly supervised learning, and the authors' experimental results are compelling. Further research exploring the method's limitations and extensions could lead to even more impactful advancements in learning from partial label information.
Conclusion
This paper introduces a novel class-aware and augmentation-free contrastive learning approach for learning from label proportion, a form of weakly supervised learning. The proposed CACL method effectively leverages the available class proportion information to learn useful representations without requiring data augmentation.
The authors' experiments demonstrate that CACL achieves state-of-the-art performance on several benchmark datasets, outperforming other methods for learning from label proportion. This suggests the CACL approach could be a valuable tool for real-world applications where detailed labels are scarce or expensive to obtain.
By advancing the state of the art in learning from label proportion, this research contributes to the broader goal of developing more efficient and practical machine learning techniques that can thrive in the face of limited or partial supervision. Further exploration of CACL's capabilities and extensions could lead to even more impactful advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Class-aware and Augmentation-free Contrastive Learning from Label Proportion
Jialiang Wang, Ning Zhang, Shimin Di, Ruidong Wang, Lei Chen
Learning from Label Proportion (LLP) is a weakly supervised learning scenario in which training data is organized into predefined bags of instances, disclosing only the class label proportions per bag. This paradigm is essential for user modeling and personalization, where user privacy is paramount, offering insights into user preferences without revealing individual data. LLP faces a unique difficulty: the misalignment between bag-level supervision and the objective of instance-level prediction, primarily due to the inherent ambiguity in label proportion matching. Previous studies have demonstrated deep representation learning can generate auxiliary signals to promote the supervision level in the image domain. However, applying these techniques to tabular data presents significant challenges: 1) they rely heavily on label-invariant augmentation to establish multi-view, which is not feasible with the heterogeneous nature of tabular datasets, and 2) tabular datasets often lack sufficient semantics for perfect class distinction, making them prone to suboptimality caused by the inherent ambiguity of label proportion matching. To address these challenges, we propose an augmentation-free contrastive framework TabLLP-BDC that introduces class-aware supervision (explicitly aware of class differences) at the instance level. Our solution features a two-stage Bag Difference Contrastive (BDC) learning mechanism that establishes robust class-aware instance-level supervision by disassembling the nuance between bag label proportions, without relying on augmentations. Concurrently, our model presents a pioneering multi-task pretraining pipeline tailored for tabular-based LLP, capturing intrinsic tabular feature correlations in alignment with label proportion distribution. Extensive experiments demonstrate that TabLLP-BDC achieves state-of-the-art performance for LLP in the tabular domain.
Read more8/14/2024

0
Theoretical Proportion Label Perturbation for Learning from Label Proportions in Large Bags
Shunsuke Kubo, Shinnosuke Matsuo, Daiki Suehiro, Kazuhiro Terada, Hiroaki Ito, Akihiko Yoshizawa, Ryoma Bise
Learning from label proportions (LLP) is a kind of weakly supervised learning that trains an instance-level classifier from label proportions of bags, which consist of sets of instances without using instance labels. A challenge in LLP arises when the number of instances in a bag (bag size) is numerous, making the traditional LLP methods difficult due to GPU memory limitations. This study aims to develop an LLP method capable of learning from bags with large sizes. In our method, smaller bags (mini-bags) are generated by sampling instances from large-sized bags (original bags), and these mini-bags are used in place of the original bags. However, the proportion of a mini-bag is unknown and differs from that of the original bag, leading to overfitting. To address this issue, we propose a perturbation method for the proportion labels of sampled mini-bags to mitigate overfitting to noisy label proportions. This perturbation is added based on the multivariate hypergeometric distribution, which is statistically modeled. Additionally, loss weighting is implemented to reduce the negative impact of proportions sampled from the tail of the distribution. Experimental results demonstrate that the proportion label perturbation and loss weighting achieve classification accuracy comparable to that obtained without sampling. Our codes are available at https://github.com/stainlessnight/LLP-LargeBags.
Read more8/27/2024

0
Optimistic Rates for Learning from Label Proportions
Gene Li, Lin Chen, Adel Javanmard, Vahab Mirrokni
We consider a weakly supervised learning problem called Learning from Label Proportions (LLP), where examples are grouped into ``bags'' and only the average label within each bag is revealed to the learner. We study various learning rules for LLP that achieve PAC learning guarantees for classification loss. We establish that the classical Empirical Proportional Risk Minimization (EPRM) learning rule (Yu et al., 2014) achieves fast rates under realizability, but EPRM and similar proportion matching learning rules can fail in the agnostic setting. We also show that (1) a debiased proportional square loss, as well as (2) a recently proposed EasyLLP learning rule (Busa-Fekete et al., 2023) both achieve ``optimistic rates'' (Panchenko, 2002); in both the realizable and agnostic settings, their sample complexity is optimal (up to log factors) in terms of $epsilon, delta$, and VC dimension.
Read more6/4/2024
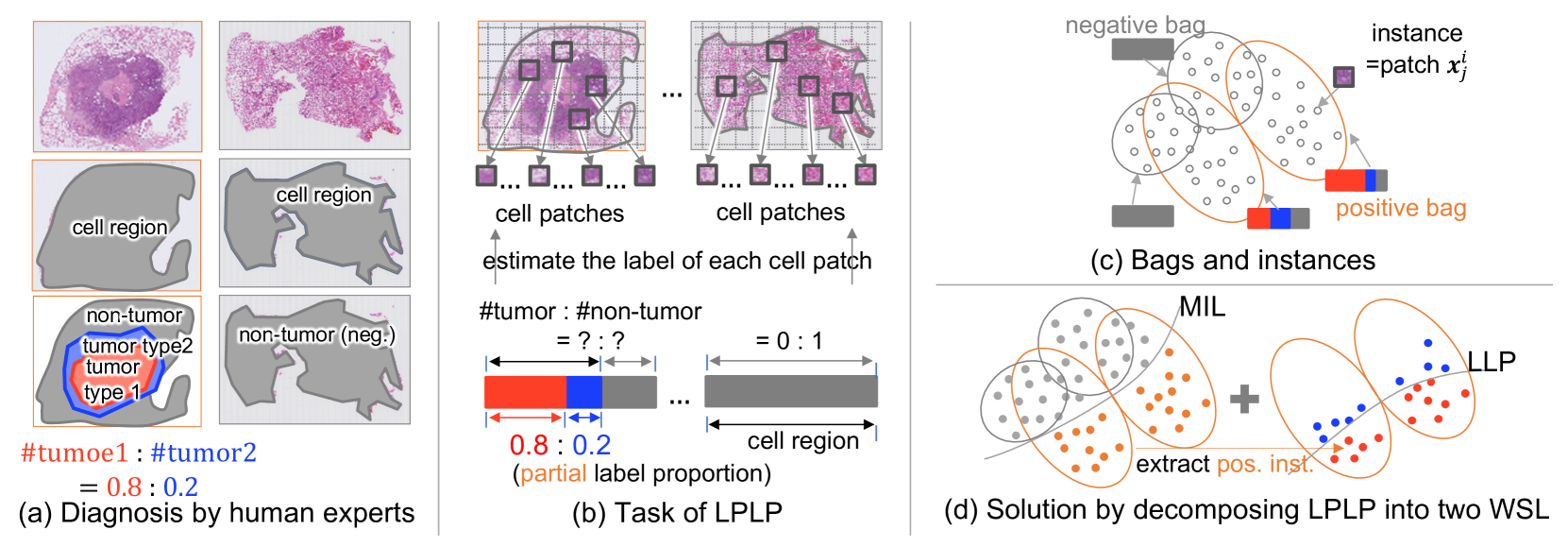
0
Learning from Partial Label Proportions for Whole Slide Image Segmentation
Shinnosuke Matsuo, Daiki Suehiro, Seiichi Uchida, Hiroaki Ito, Kazuhiro Terada, Akihiko Yoshizawa, Ryoma Bise
In this paper, we address the segmentation of tumor subtypes in whole slide images (WSI) by utilizing incomplete label proportions. Specifically, we utilize `partial' label proportions, which give the proportions among tumor subtypes but do not give the proportion between tumor and non-tumor. Partial label proportions are recorded as the standard diagnostic information by pathologists, and we, therefore, want to use them for realizing the segmentation model that can classify each WSI patch into one of the tumor subtypes or non-tumor. We call this problem ``learning from partial label proportions (LPLP)'' and formulate the problem as a weakly supervised learning problem. Then, we propose an efficient algorithm for this challenging problem by decomposing it into two weakly supervised learning subproblems: multiple instance learning (MIL) and learning from label proportions (LLP). These subproblems are optimized efficiently in the end-to-end manner. The effectiveness of our algorithm is demonstrated through experiments conducted on two WSI datasets.
Read more5/16/2024