Classifying Cancer Stage with Open-Source Clinical Large Language Models
2404.01589
0
0
💬
Abstract
Cancer stage classification is important for making treatment and care management plans for oncology patients. Information on staging is often included in unstructured form in clinical, pathology, radiology and other free-text reports in the electronic health record system, requiring extensive work to parse and obtain. To facilitate the extraction of this information, previous NLP approaches rely on labeled training datasets, which are labor-intensive to prepare. In this study, we demonstrate that without any labeled training data, open-source clinical large language models (LLMs) can extract pathologic tumor-node-metastasis (pTNM) staging information from real-world pathology reports. Our experiments compare LLMs and a BERT-based model fine-tuned using the labeled data. Our findings suggest that while LLMs still exhibit subpar performance in Tumor (T) classification, with the appropriate adoption of prompting strategies, they can achieve comparable performance on Metastasis (M) classification and improved performance on Node (N) classification.
Create account to get full access
Overview
- This paper presents a study on using open-source clinical large language models (LLMs) to classify cancer stage from medical text.
- The researchers trained and evaluated several LLM-based models on a cancer staging dataset, aiming to provide a cost-effective solution for automated cancer staging.
- The paper was accepted for presentation at the IEEE International Conference on Healthcare Informatics (IEEE ICHI 2024).
Plain English Explanation
Cancer stage is an important factor in determining the best treatment options and prognosis for a patient. Traditionally, cancer staging has relied on manual review of medical records and imaging by trained clinicians. However, this process can be time-consuming and resource-intensive, especially with the increasing volume of clinical data.
The researchers in this study explored using open-source large language models as a more automated and scalable approach to cancer staging. Large language models are AI systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. The researchers fine-tuned several of these models on a dataset of cancer patient records, teaching the models to recognize patterns and features that are indicative of different cancer stages.
By leveraging these powerful language models, the researchers were able to develop a system that could accurately classify cancer stage from the textual information in medical reports, without the need for manual expert review. This could potentially save time and resources for healthcare providers, while also ensuring more consistent and standardized cancer staging across different institutions.
Technical Explanation
The researchers in this study explored the use of open-source clinical large language models (LLMs) for the task of cancer stage classification. They fine-tuned several LLM-based models, including BERT, RoBERTa, and BioBERT, on a dataset of cancer patient records with labeled cancer stages.
The dataset consisted of structured and unstructured clinical data, such as diagnostic reports, pathology reports, and clinical notes. The researchers preprocessed the text data, removing personally identifiable information and converting it to a format suitable for the LLM models.
During the fine-tuning process, the researchers optimized the LLM models for the cancer stage classification task by adjusting various hyperparameters, such as learning rate, batch size, and number of training epochs. They also experimented with different model architectures and input representations to improve the models' performance.
The researchers evaluated the trained models using standard metrics, such as accuracy, F1-score, and area under the receiver operating characteristic (ROC) curve. Their results showed that the fine-tuned LLM models were able to achieve high classification accuracy, outperforming traditional machine learning approaches on the same task.
The researchers also conducted ablation studies to understand the importance of different input features and the impact of the fine-tuning process on the models' performance. They found that the LLM-based models were able to effectively leverage the contextual information and domain-specific knowledge embedded in the pre-trained language models, leading to improved cancer stage classification compared to models trained from scratch.
Critical Analysis
The researchers have presented a promising approach for automated cancer stage classification using open-source clinical language models. The use of large, pre-trained language models, such as BERT and RoBERTa, allows for effective transfer learning and leveraging of domain-specific knowledge, which is a key advantage over traditional machine learning methods that require extensive feature engineering.
However, the study does have some limitations. The dataset used for training and evaluation was relatively small, and the researchers acknowledged that larger and more diverse datasets would be needed to further validate the generalizability of their approach. Additionally, the study focused solely on textual data, and the potential integration of structured clinical data or medical images could further improve the classification performance.
It would also be interesting to see how the LLM-based models perform on more nuanced or ambiguous cancer staging cases, where expert clinician judgment may be required. The researchers could explore ways to incorporate human-in-the-loop approaches or provide uncertainty estimates to assist clinicians in the decision-making process.
Furthermore, the study did not delve into the interpretability and explainability of the LLM-based models, which is an important consideration for their adoption in clinical settings. Providing insights into the key features and decision-making processes of the models could help build trust and facilitate their integration into clinical workflows.
Overall, the researchers have demonstrated the potential of open-source clinical language models for automated cancer stage classification, paving the way for further research and development in this area. Continued advancements in large language model techniques and the integration of multimodal data could lead to even more robust and reliable systems for supporting clinical decision-making.
Conclusion
This study presents a novel approach to cancer stage classification using open-source clinical large language models. The researchers have shown that these powerful language models can be effectively fine-tuned to provide accurate and scalable cancer staging, potentially reducing the burden on healthcare providers and improving the consistency of cancer staging across different institutions.
The research also highlights the broader potential of leveraging large language models in the healthcare domain, particularly for tasks that involve processing and understanding unstructured clinical data. As the field of language model-based healthcare applications continues to evolve, this study serves as an important contribution, demonstrating the feasibility and effectiveness of this approach for automated cancer staging.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CancerLLM: A Large Language Model in Cancer Domain
Mingchen Li, Anne Blaes, Steven Johnson, Hongfang Liu, Hua Xu, Rui Zhang
0
0
Medical Large Language Models (LLMs) such as ClinicalCamel 70B, Llama3-OpenBioLLM 70B have demonstrated impressive performance on a wide variety of medical NLP task.However, there still lacks a large language model (LLM) specifically designed for cancer domain. Moreover, these LLMs typically have billions of parameters, making them computationally expensive for healthcare systems.Thus, in this study, we propose CancerLLM, a model with 7 billion parameters and a Mistral-style architecture, pre-trained on 2,676,642 clinical notes and 515,524 pathology reports covering 17 cancer types, followed by fine-tuning on three cancer-relevant tasks, including cancer phenotypes extraction, cancer diagnosis generation, and cancer treatment plan generation. Our evaluation demonstrated that CancerLLM achieves state-of-the-art results compared to other existing LLMs, with an average F1 score improvement of 8.1%. Additionally, CancerLLM outperforms other models on two proposed robustness testbeds. This illustrates that CancerLLM can be effectively applied to clinical AI systems, enhancing clinical research and healthcare delivery in the field of cancer.
6/18/2024
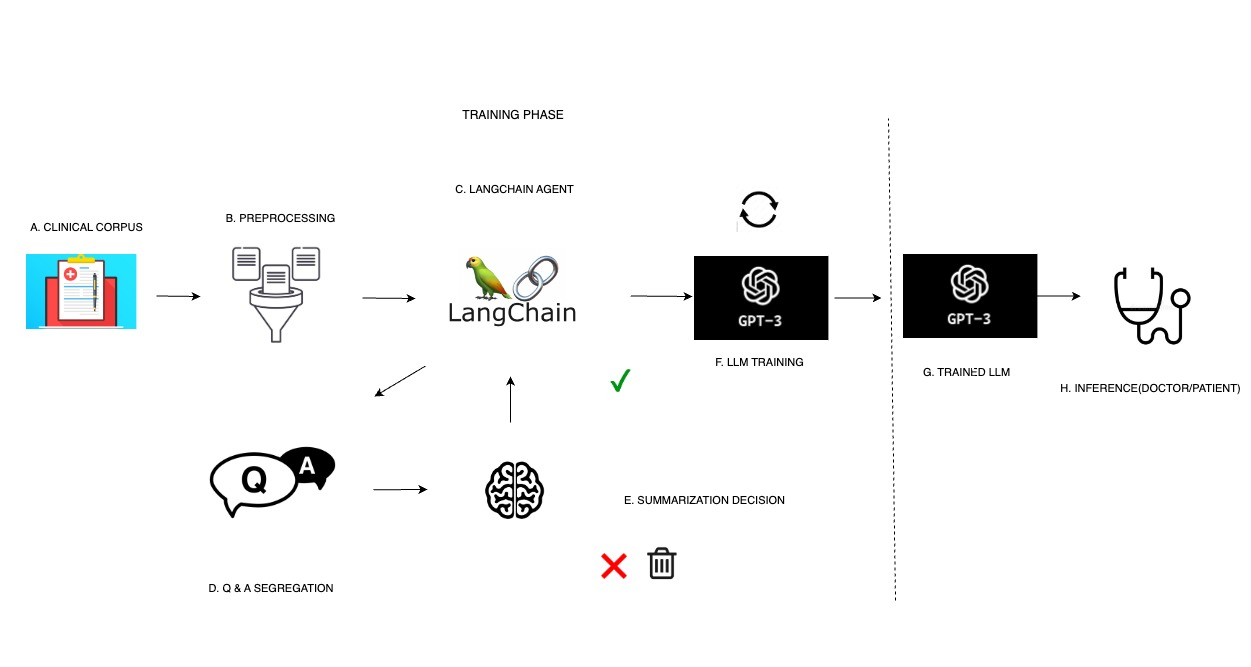
A Large Language Model Pipeline for Breast Cancer Oncology
Tristen Pool, Dennis Trujillo
0
0
Large language models (LLMs) have demonstrated potential in the innovation of many disciplines. However, how they can best be developed for oncology remains underdeveloped. State-of-the-art OpenAI models were fine-tuned on a clinical dataset and clinical guidelines text corpus for two important cancer treatment factors, adjuvant radiation therapy and chemotherapy, using a novel Langchain prompt engineering pipeline. A high accuracy (0.85+) was achieved in the classification of adjuvant radiation therapy and chemotherapy for breast cancer patients. Furthermore, a confidence interval was formed from observational data on the quality of treatment from human oncologists to estimate the proportion of scenarios in which the model must outperform the original oncologist in its treatment prediction to be a better solution overall as 8.2% to 13.3%. Due to indeterminacy in the outcomes of cancer treatment decisions, future investigation, potentially a clinical trial, would be required to determine if this threshold was met by the models. Nevertheless, with 85% of U.S. cancer patients receiving treatment at local community facilities, these kinds of models could play an important part in expanding access to quality care with outcomes that lie, at minimum, close to a human oncologist.
6/17/2024
💬
Exploring Multilingual Large Language Models for Enhanced TNM classification of Radiology Report in lung cancer staging
Hidetoshi Matsuo, Mizuho Nishio, Takaaki Matsunaga, Koji Fujimoto, Takamichi Murakami
0
0
Background: Structured radiology reports remains underdeveloped due to labor-intensive structuring and narrative-style reporting. Deep learning, particularly large language models (LLMs) like GPT-3.5, offers promise in automating the structuring of radiology reports in natural languages. However, although it has been reported that LLMs are less effective in languages other than English, their radiological performance has not been extensively studied. Purpose: This study aimed to investigate the accuracy of TNM classification based on radiology reports using GPT3.5-turbo (GPT3.5) and the utility of multilingual LLMs in both Japanese and English. Material and Methods: Utilizing GPT3.5, we developed a system to automatically generate TNM classifications from chest CT reports for lung cancer and evaluate its performance. We statistically analyzed the impact of providing full or partial TNM definitions in both languages using a Generalized Linear Mixed Model. Results: Highest accuracy was attained with full TNM definitions and radiology reports in English (M = 94%, N = 80%, T = 47%, and ALL = 36%). Providing definitions for each of the T, N, and M factors statistically improved their respective accuracies (T: odds ratio (OR) = 2.35, p < 0.001; N: OR = 1.94, p < 0.01; M: OR = 2.50, p < 0.001). Japanese reports exhibited decreased N and M accuracies (N accuracy: OR = 0.74 and M accuracy: OR = 0.21). Conclusion: This study underscores the potential of multilingual LLMs for automatic TNM classification in radiology reports. Even without additional model training, performance improvements were evident with the provided TNM definitions, indicating LLMs' relevance in radiology contexts.
6/13/2024
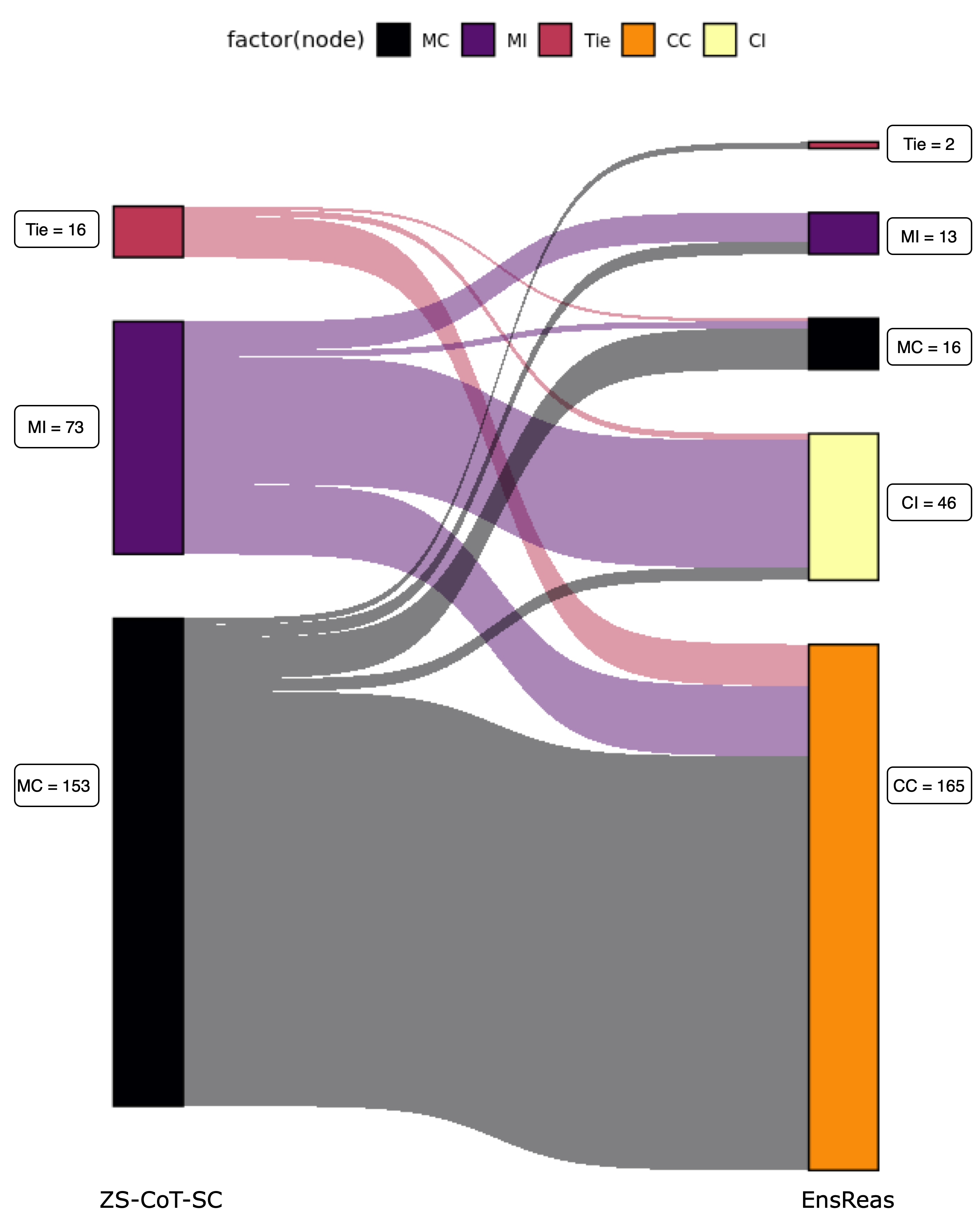
Beyond Self-Consistency: Ensemble Reasoning Boosts Consistency and Accuracy of LLMs in Cancer Staging
Chia-Hsuan Chang, Mary M. Lucas, Yeawon Lee, Christopher C. Yang, Grace Lu-Yao
0
0
Advances in large language models (LLMs) have encouraged their adoption in the healthcare domain where vital clinical information is often contained in unstructured notes. Cancer staging status is available in clinical reports, but it requires natural language processing to extract the status from the unstructured text. With the advance in clinical-oriented LLMs, it is promising to extract such status without extensive efforts in training the algorithms. Prompting approaches of the pre-trained LLMs that elicit a model's reasoning process, such as chain-of-thought, may help to improve the trustworthiness of the generated responses. Using self-consistency further improves model performance, but often results in inconsistent generations across the multiple reasoning paths. In this study, we propose an ensemble reasoning approach with the aim of improving the consistency of the model generations. Using an open access clinical large language model to determine the pathologic cancer stage from real-world pathology reports, we show that the ensemble reasoning approach is able to improve both the consistency and performance of the LLM in determining cancer stage, thereby demonstrating the potential to use these models in clinical or other domains where reliability and trustworthiness are critical.
4/23/2024