Classifying populist language in American presidential and governor speeches using automatic text analysis

0
Sign in to get full access
Overview
- This paper investigates the use of populist language in American presidential and governor speeches using automatic text analysis techniques.
- The research was partly funded by the European Union through an ERC Consolidator grant.
- The views and opinions expressed in the paper are those of the authors and do not necessarily reflect the views of the European Union or the European Research Council Executive Agency.
Plain English Explanation
The researchers in this paper wanted to analyze the use of populist language in speeches given by American presidents and state governors. Populist language is a way of speaking that often appeals to the "common people" and portrays a divide between them and the elite or establishment.
The researchers used automated text analysis techniques to identify and classify this type of language in a large dataset of political speeches. This allowed them to track changes in populist rhetoric over time and compare the usage across different political positions and levels of government.
The goal of this research was to better understand how populist language is used in American politics and whether there are any patterns or trends in its adoption by political leaders. This could provide insights into the role of populism in shaping political discourse and decision-making.
Technical Explanation
The researchers compiled a large dataset of over 100,000 political speeches given by American presidents and state governors between 1900 and 2020. They then used natural language processing techniques to automatically identify and classify the use of populist language within these texts.
Specifically, the researchers developed a machine learning model trained on a corpus of human-annotated speeches to recognize linguistic features associated with populist rhetoric, such as:
- References to "the people" vs. "the elite"
- Expressions of anti-establishment sentiment
- Promises to give power back to the common citizen
By applying this model to their dataset, the researchers were able to track trends in populist language use over time and compare its prevalence across different political offices and levels of government.
The results of their analysis provide insights into how populist messaging has evolved in American politics and how it is leveraged by political leaders to connect with their constituents.
Critical Analysis
The paper presents a rigorous and well-designed study that leverages state-of-the-art natural language processing techniques to analyze populist language in American political speeches. The large dataset and automated analysis approach allow the researchers to uncover trends and patterns that would be difficult to identify through manual coding.
However, the paper does acknowledge some limitations of their approach. For example, the machine learning model may not capture all nuances of populist rhetoric, and the dataset itself may not be fully representative of all political discourse. Additionally, the paper does not delve into the potential implications or real-world impact of the observed trends in populist language use.
Further research could explore how these linguistic patterns relate to specific policy positions or electoral outcomes, as well as the psychological and sociological factors that contribute to the rise and spread of populist rhetoric in American politics.
Conclusion
This paper presents a novel approach to studying the use of populist language in American political discourse. By leveraging automated text analysis techniques, the researchers were able to uncover trends and patterns in how political leaders appeal to the common citizen and position themselves against the establishment.
The insights from this research could have important implications for our understanding of the role of populism in shaping political narratives and decision-making. Additionally, the methodological approach showcased in this paper could be applied to other domains to gain deeper insights into the language and rhetoric used by political and social actors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Classifying populist language in American presidential and governor speeches using automatic text analysis
Olaf van der Veen, Semir Dzebo, Levi Littvay, Kirk Hawkins, Oren Dar
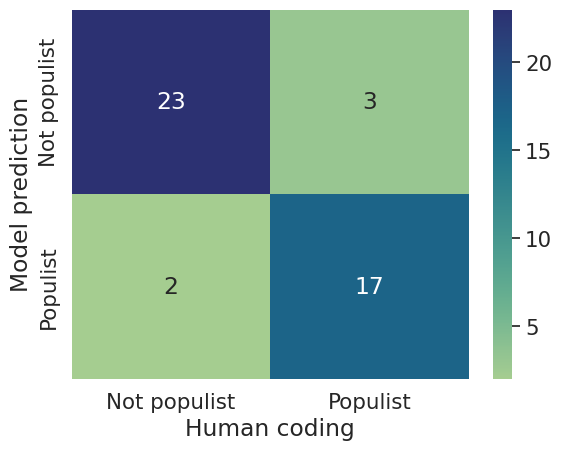
Populism is a concept that is often used but notoriously difficult to measure. Common qualitative measurements like holistic grading or content analysis require great amounts of time and labour, making it difficult to quickly scope out which politicians should be classified as populist and which should not, while quantitative methods show mixed results when it comes to classifying populist rhetoric. In this paper, we develop a pipeline to train and validate an automated classification model to estimate the use of populist language. We train models based on sentences that were identified as populist and pluralist in 300 US governors' speeches from 2010 to 2018 and in 45 speeches of presidential candidates in 2016. We find that these models classify most speeches correctly, including 84% of governor speeches and 89% of presidential speeches. These results extend to different time periods (with 92% accuracy on more recent American governors), different amounts of data (with as few as 70 training sentences per category achieving similar results), and when classifying politicians instead of individual speeches. This pipeline is thus an effective tool that can optimise the systematic and swift classification of the use of populist language in politicians' speeches.
Read more8/28/2024
💬
0
The Face of Populism: Examining Differences in Facial Emotional Expressions of Political Leaders Using Machine Learning
Sara Major, Aleksandar Tomav{s}evi'c
Populist rhetoric employed on online media is characterized as deeply impassioned and often imbued with strong emotions. The aim of this paper is to empirically investigate the differences in affective nonverbal communication of political leaders. We use a deep-learning approach to process a sample of 220 YouTube videos of political leaders from 15 different countries, analyze their facial expressions of emotion and then examine differences in average emotion scores representing the relative presence of 6 emotional states (anger, disgust, fear, happiness, sadness, and surprise) and a neutral expression for each frame of the YouTube video. Based on a sample of manually coded images, we find that this deep-learning approach has 53-60% agreement with human labels. We observe statistically significant differences in the average score of negative emotions between groups of leaders with varying degrees of populist rhetoric.
Read more8/9/2024
📊
0
L(u)PIN: LLM-based Political Ideology Nowcasting
Ken Kato, Annabelle Purnomo, Christopher Cochrane, Raeid Saqur
The quantitative analysis of political ideological positions is a difficult task. In the past, various literature focused on parliamentary voting data of politicians, party manifestos and parliamentary speech to estimate political disagreement and polarization in various political systems. However previous methods of quantitative political analysis suffered from a common challenge which was the amount of data available for analysis. Also previous methods frequently focused on a more general analysis of politics such as overall polarization of the parliament or party-wide political ideological positions. In this paper, we present a method to analyze ideological positions of individual parliamentary representatives by leveraging the latent knowledge of LLMs. The method allows us to evaluate the stance of politicians on an axis of our choice allowing us to flexibly measure the stance of politicians in regards to a topic/controversy of our choice. We achieve this by using a fine-tuned BERT classifier to extract the opinion-based sentences from the speeches of representatives and projecting the average BERT embeddings for each representative on a pair of reference seeds. These reference seeds are either manually chosen representatives known to have opposing views on a particular topic or they are generated sentences which where created using the GPT-4 model of OpenAI. We created the sentences by prompting the GPT-4 model to generate a speech that would come from a politician defending a particular position.
Read more5/14/2024

0
PoliPrompt: A High-Performance Cost-Effective LLM-Based Text Classification Framework for Political Science
Menglin Liu, Ge Shi
Recent advancements in large language models (LLMs) have opened new avenues for enhancing text classification efficiency in political science, surpassing traditional machine learning methods that often require extensive feature engineering, human labeling, and task-specific training. However, their effectiveness in achieving high classification accuracy remains questionable. This paper introduces a three-stage in-context learning approach that leverages LLMs to improve classification accuracy while minimizing experimental costs. Our method incorporates automatic enhanced prompt generation, adaptive exemplar selection, and a consensus mechanism that resolves discrepancies between two weaker LLMs, refined by an advanced LLM. We validate our approach using datasets from the BBC news reports, Kavanaugh Supreme Court confirmation, and 2018 election campaign ads. The results show significant improvements in classification F1 score (+0.36 for zero-shot classification) with manageable economic costs (-78% compared with human labeling), demonstrating that our method effectively addresses the limitations of traditional machine learning while offering a scalable and reliable solution for text analysis in political science.
Read more9/4/2024