L(u)PIN: LLM-based Political Ideology Nowcasting
2405.07320
0
0
📊
Abstract
The quantitative analysis of political ideological positions is a difficult task. In the past, various literature focused on parliamentary voting data of politicians, party manifestos and parliamentary speech to estimate political disagreement and polarization in various political systems. However previous methods of quantitative political analysis suffered from a common challenge which was the amount of data available for analysis. Also previous methods frequently focused on a more general analysis of politics such as overall polarization of the parliament or party-wide political ideological positions. In this paper, we present a method to analyze ideological positions of individual parliamentary representatives by leveraging the latent knowledge of LLMs. The method allows us to evaluate the stance of politicians on an axis of our choice allowing us to flexibly measure the stance of politicians in regards to a topic/controversy of our choice. We achieve this by using a fine-tuned BERT classifier to extract the opinion-based sentences from the speeches of representatives and projecting the average BERT embeddings for each representative on a pair of reference seeds. These reference seeds are either manually chosen representatives known to have opposing views on a particular topic or they are generated sentences which where created using the GPT-4 model of OpenAI. We created the sentences by prompting the GPT-4 model to generate a speech that would come from a politician defending a particular position.
Create account to get full access
Overview
- This paper proposes a new method for analyzing the ideological positions of individual politicians based on their parliamentary speeches.
- Previous methods for quantitative political analysis have been limited by the available data, often focusing on overall polarization or party-level positions.
- The proposed approach leverages the latent knowledge of large language models (LLMs) to evaluate the stance of politicians on specific topics or controversies.
Plain English Explanation
The paper discusses a new way to analyze the political views of individual politicians by looking at their parliamentary speeches. In the past, researchers have used data like voting records or party manifestos to estimate the overall political disagreement or polarization in a government. However, these methods were often limited by the amount of data available.
The researchers in this paper have come up with a new technique that uses the "knowledge" inside large language models (LLMs) like BERT to understand the opinions of individual politicians. They do this by identifying opinion-based sentences in the politicians' speeches and then comparing the "average" meaning of those sentences to reference "anchor" points.
These anchor points can either be speeches from politicians with known opposing views on a topic, or they can be generated using a model like GPT-4 to create example speeches expressing different positions. This allows the researchers to measure where each politician stands on a particular issue or controversy, rather than just looking at overall political divides.
Technical Explanation
The key innovation in this paper is the use of fine-tuned language models to analyze the ideological positions of individual politicians based on their parliamentary speeches. The researchers first use a BERT classifier to identify opinion-based sentences in the speech transcripts. They then calculate the average BERT embedding for each politician's speeches and project these onto a spectrum defined by a pair of reference "anchor" points.
These anchor points can be manually selected speeches from politicians with known opposing views on a particular topic, or they can be generated using a large language model like GPT-4 to create example speeches expressing different positions. This flexible approach allows the researchers to measure the stance of politicians on any topic or controversy of interest.
The method builds on prior work in political text analysis and the use of LLMs as augmented agents to extract insights from large text corpora.
Critical Analysis
The proposed method represents a significant advancement in the quantitative analysis of political ideologies, addressing limitations of previous approaches. By leveraging the rich semantic knowledge of LLMs, the researchers can now evaluate the positions of individual politicians on specific issues, rather than just overall polarization.
However, the approach does rely on the quality and accuracy of the LLM models used, as well as the suitability of the chosen anchor points. The researchers acknowledge that further validation and testing would be needed to ensure the method's robustness across different political contexts and topics.
Additionally, the paper does not explore potential biases or blindspots that could arise from the LLM-based analysis, such as the models' inherent biases or the impact of political rhetoric and framing. These are important considerations that warrant further investigation.
Conclusion
This paper presents a novel method for analyzing the ideological positions of individual politicians based on their parliamentary speeches. By using fine-tuned language models to identify opinion-based sentences and project them onto a spectrum defined by reference anchor points, the researchers have developed a flexible and powerful tool for understanding political disagreement and polarization at a granular level.
While the approach requires further validation and refinement, it represents a significant advancement in the field of quantitative political analysis. The ability to measure the stance of politicians on specific topics or controversies has important implications for enhancing our understanding of political dynamics and decision-making processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
The Political Preferences of LLMs
David Rozado
0
0
I report here a comprehensive analysis about the political preferences embedded in Large Language Models (LLMs). Namely, I administer 11 political orientation tests, designed to identify the political preferences of the test taker, to 24 state-of-the-art conversational LLMs, both closed and open source. When probed with questions/statements with political connotations, most conversational LLMs tend to generate responses that are diagnosed by most political test instruments as manifesting preferences for left-of-center viewpoints. This does not appear to be the case for five additional base (i.e. foundation) models upon which LLMs optimized for conversation with humans are built. However, the weak performance of the base models at coherently answering the tests' questions makes this subset of results inconclusive. Finally, I demonstrate that LLMs can be steered towards specific locations in the political spectrum through Supervised Fine-Tuning (SFT) with only modest amounts of politically aligned data, suggesting SFT's potential to embed political orientation in LLMs. With LLMs beginning to partially displace traditional information sources like search engines and Wikipedia, the societal implications of political biases embedded in LLMs are substantial.
6/4/2024
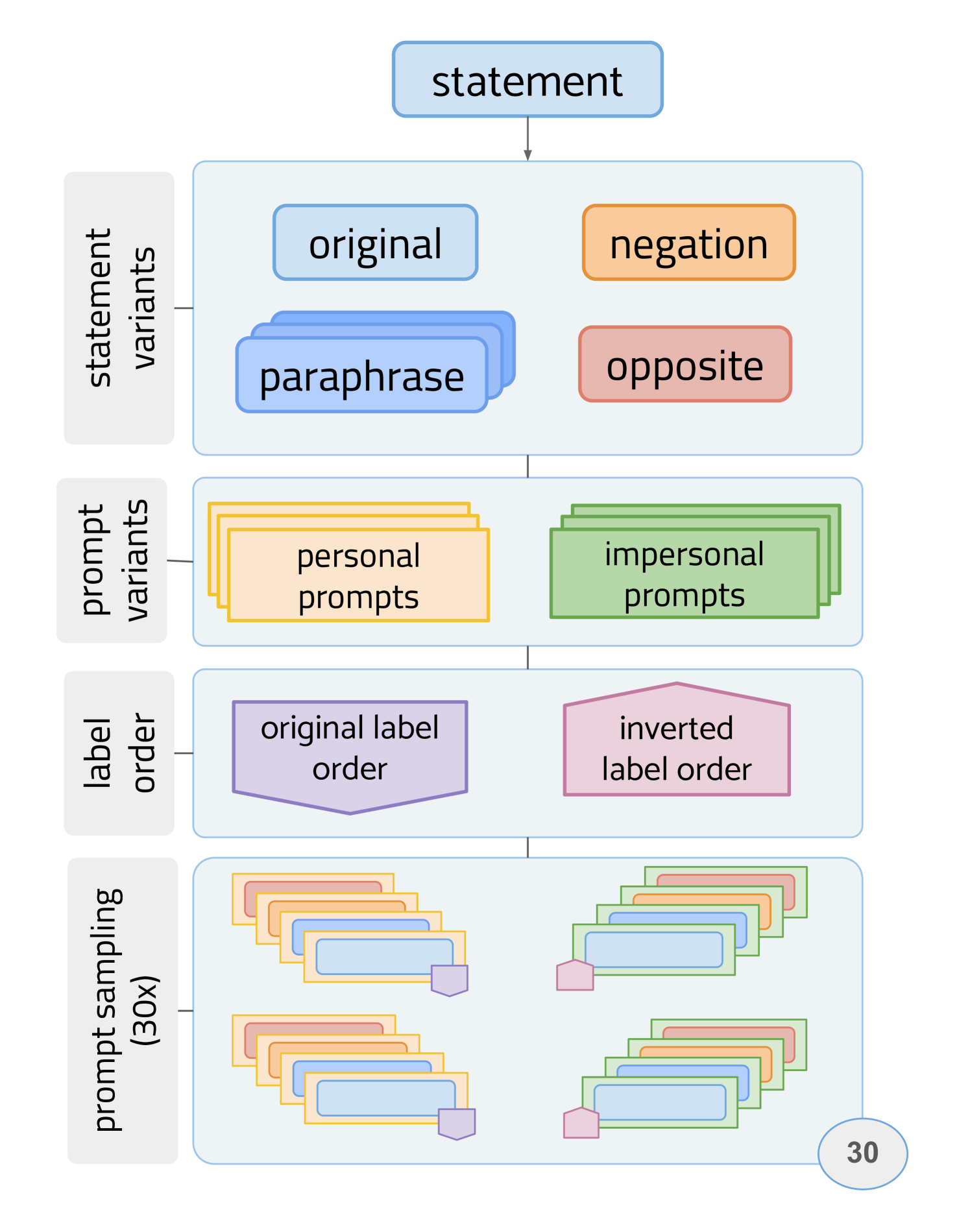
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
Tanise Ceron, Neele Falk, Ana Bari'c, Dmitry Nikolaev, Sebastian Pad'o
0
0
Due to the widespread use of large language models (LLMs) in ubiquitous systems, we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings (Feng et al., 2023; Motoki et al., 2024). However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy domains. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They evince a (left-wing) positive stance towards environment protection, social welfare state and liberal society but also (right-wing) law and order, with no consistent preferences in foreign policy and migration.
6/5/2024

Revealing Fine-Grained Values and Opinions in Large Language Models
Dustin Wright, Arnav Arora, Nadav Borenstein, Srishti Yadav, Serge Belongie, Isabelle Augenstein
0
0
Uncovering latent values and opinions in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by presenting LLMs with survey questions and quantifying their stances towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.
6/28/2024
💬
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
0
0
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
6/6/2024