CLDA: Collaborative Learning for Enhanced Unsupervised Domain Adaptation

0

Sign in to get full access
Overview
- Proposes a novel approach called Collaborative Learning for Domain Adaptation (CLDA) to enhance unsupervised domain adaptation
- CLDA leverages the knowledge of multiple models trained on different domains to improve adaptation to a target domain
- Demonstrates the effectiveness of CLDA on several benchmarks, outperforming state-of-the-art unsupervised domain adaptation methods
Plain English Explanation
The paper introduces a new technique called Collaborative Learning for Domain Adaptation (CLDA) that aims to improve unsupervised domain adaptation. Domain adaptation is the process of transferring knowledge from a source domain, where labeled data is available, to a target domain, where labeled data is scarce or unavailable.
CLDA works by leveraging the knowledge of multiple models that have been trained on different source domains. These models are then used to enhance the adaptation to the target domain, rather than relying on a single source model. The key idea is that the combined knowledge from multiple sources can provide a richer and more robust representation for the target domain, leading to better adaptation performance.
The paper demonstrates the effectiveness of CLDA on several benchmark datasets, showing that it outperforms state-of-the-art unsupervised domain adaptation methods. This suggests that the collaborative approach can be a valuable tool for improving the performance of AI systems when they are deployed in new environments or contexts where labeled data is limited.
Technical Explanation
The paper proposes a novel Collaborative Learning for Domain Adaptation (CLDA) approach to enhance unsupervised domain adaptation. The main idea is to leverage the knowledge of multiple models trained on different source domains to improve the adaptation to a target domain.
The CLDA framework consists of three key components:
-
Source Model Training: The authors train multiple source models on different source domains using standard supervised learning techniques.
-
Collaborative Learning: The source models are then used to guide the training of a target model on the unlabeled target domain data. This is done by aligning the target model's representations with the ensemble of source models, encouraging the target model to learn a more robust and discriminative representation.
-
Target Model Adaptation: The collaboratively trained target model is further fine-tuned on the target domain data to specialize its representations for the target task.
The authors evaluate CLDA on several benchmark datasets for unsupervised domain adaptation and show that it outperforms state-of-the-art methods. This suggests that the collaborative approach can effectively leverage the complementary knowledge from multiple source models to enhance the adaptation to the target domain, even when labeled data is scarce.
Critical Analysis
The paper presents a compelling approach to unsupervised domain adaptation, but there are a few potential limitations and areas for further research:
-
Scalability: The paper focuses on a relatively small number of source domains (typically 2-3). It's unclear how CLDA would scale to a larger number of diverse source domains, which may be necessary for real-world applications.
-
Compatibility of Source Domains: The paper does not address the issue of how to select appropriate source domains that are compatible with the target domain. The effectiveness of CLDA may depend on the similarity and complementarity of the source and target domains.
-
Interpretability: The paper does not provide much insight into how the collaborative learning process works and why it leads to better adaptation performance. A more detailed analysis of the internal representations and their evolution during training could help understand the strengths and limitations of the approach.
-
Computational Complexity: The need to train multiple source models and perform the collaborative learning step may increase the computational overhead compared to simpler unsupervised domain adaptation methods. The paper could explore ways to improve the efficiency of the CLDA framework.
Despite these potential limitations, the CLDA approach represents an interesting and promising direction for enhancing unsupervised domain adaptation, especially in scenarios where multiple related source domains are available. Further research could address the scalability, compatibility, interpretability, and efficiency of the method, ultimately leading to more robust and practical domain adaptation solutions.
Conclusion
The paper introduces Collaborative Learning for Domain Adaptation (CLDA), a novel approach that leverages the knowledge of multiple source models to improve unsupervised domain adaptation. By aligning the target model's representations with an ensemble of source models, CLDA can learn more robust and discriminative features for the target domain, outperforming state-of-the-art methods.
The demonstrated effectiveness of CLDA suggests that collaborative learning can be a valuable tool for enhancing the performance of AI systems when deployed in new environments or contexts where labeled data is scarce. Further research on scalability, compatibility, interpretability, and efficiency could help make CLDA a more practical and widely applicable domain adaptation technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLDA: Collaborative Learning for Enhanced Unsupervised Domain Adaptation
Minhee Cho, Hyesong Choi, Hayeon Jo, Dongbo Min
Unsupervised Domain Adaptation (UDA) endeavors to bridge the gap between a model trained on a labeled source domain and its deployment in an unlabeled target domain. However, current high-performance models demand significant resources, resulting in prohibitive deployment costs and highlighting the need for small yet effective models. For UDA of lightweight models, Knowledge Distillation (KD) in a Teacher-Student framework can be a common approach, but we find that domain shift in UDA leads to a significant increase in non-salient parameters in the teacher model, degrading model's generalization ability and transferring misleading information to the student model. Interestingly, we observed that this phenomenon occurs considerably less in the student model. Driven by this insight, we introduce Collaborative Learning, a method that updates the teacher's non-salient parameters using the student model and at the same time enhance the student's performance using the updated teacher model. Experiments across various tasks and datasets show consistent performance improvements for both student and teacher models. For example, in semantic segmentation, CLDA achieves an improvement of +0.7% mIoU for teacher and +1.4% mIoU for student compared to the baseline model in the GTA to Cityscapes. In the Synthia to Cityscapes, it achieves an improvement of +0.8% mIoU for teacher and +2.0% mIoU for student.
Read more9/5/2024
🤷
0
Combining inherent knowledge of vision-language models with unsupervised domain adaptation through strong-weak guidance
Thomas Westfechtel, Dexuan Zhang, Tatsuya Harada
Unsupervised domain adaptation (UDA) tries to overcome the tedious work of labeling data by leveraging a labeled source dataset and transferring its knowledge to a similar but different target dataset. Meanwhile, current vision-language models exhibit remarkable zero-shot prediction capabilities. In this work, we combine knowledge gained through UDA with the inherent knowledge of vision-language models. We introduce a strong-weak guidance learning scheme that employs zero-shot predictions to help align the source and target dataset. For the strong guidance, we expand the source dataset with the most confident samples of the target dataset. Additionally, we employ a knowledge distillation loss as weak guidance. The strong guidance uses hard labels but is only applied to the most confident predictions from the target dataset. Conversely, the weak guidance is employed to the whole dataset but uses soft labels. The weak guidance is implemented as a knowledge distillation loss with (shifted) zero-shot predictions. We show that our method complements and benefits from prompt adaptation techniques for vision-language models. We conduct experiments and ablation studies on three benchmarks (OfficeHome, VisDA, and DomainNet), outperforming state-of-the-art methods. Our ablation studies further demonstrate the contributions of different components of our algorithm.
Read more7/23/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
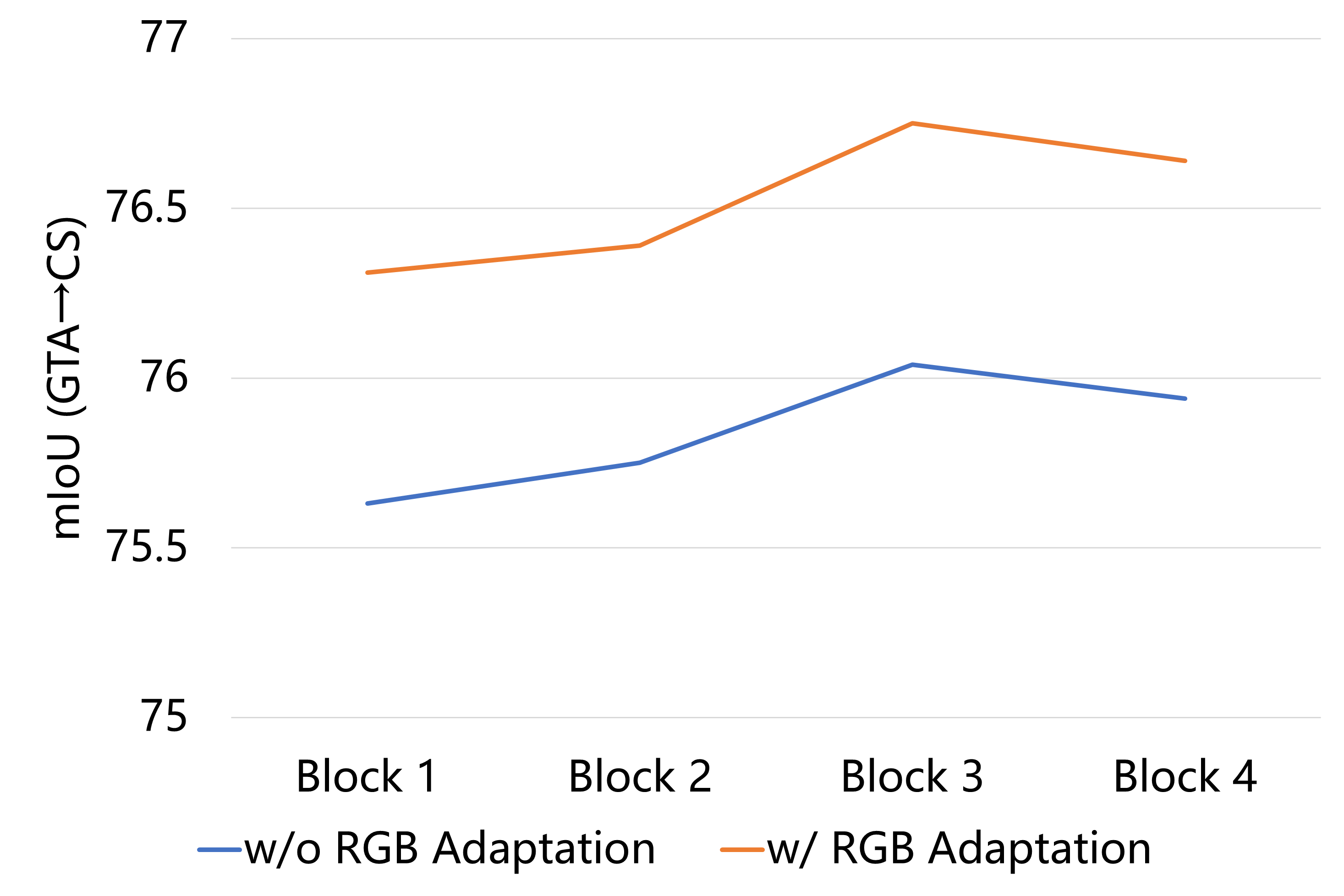
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024
0
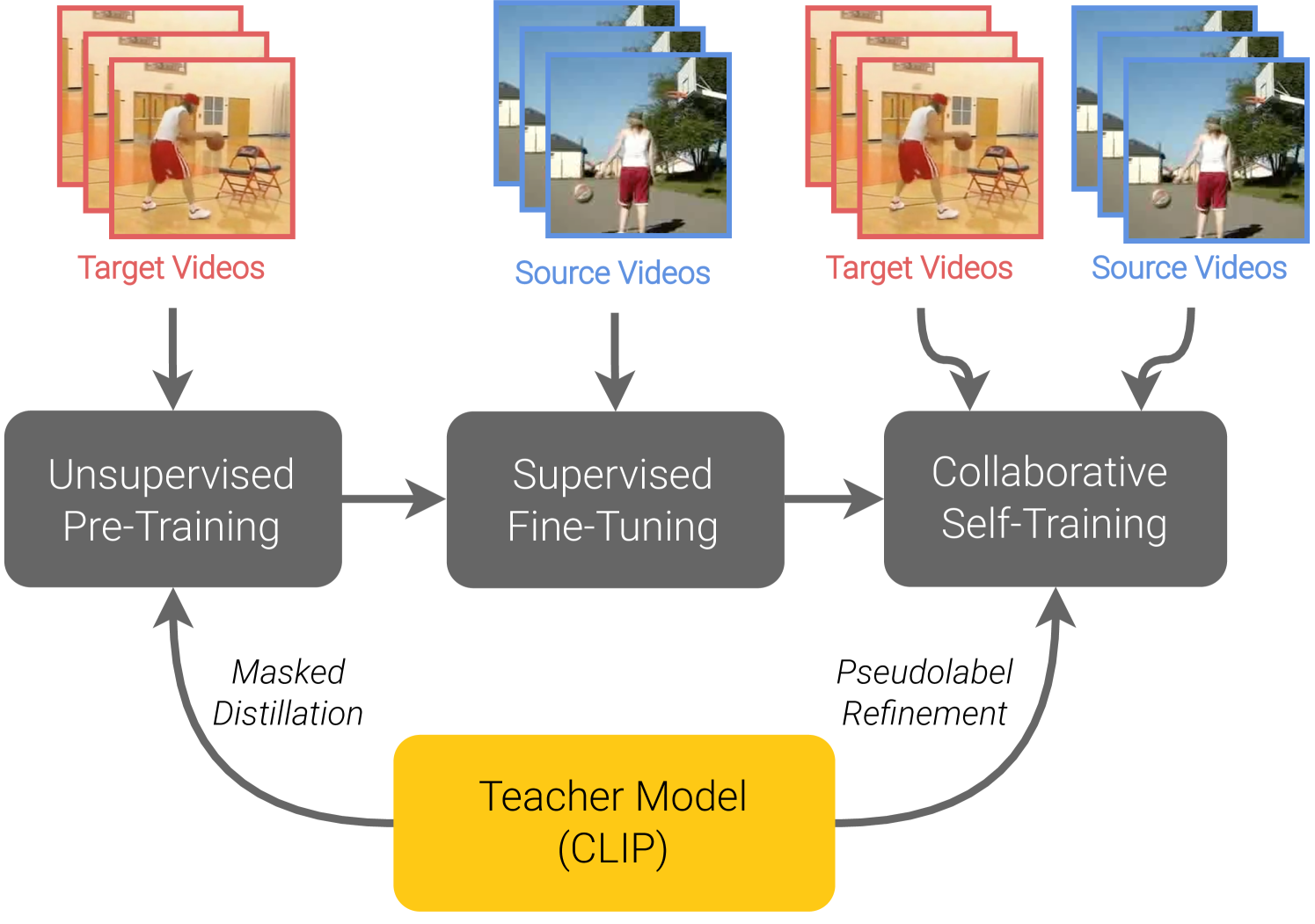
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Arun Reddy, William Paul, Corban Rivera, Ketul Shah, Celso M. de Melo, Rama Chellappa
In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.
Read more4/23/2024