Combining inherent knowledge of vision-language models with unsupervised domain adaptation through strong-weak guidance

0
🤷
Sign in to get full access
Overview
- Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source dataset to an unlabeled target dataset.
- Vision-language models have shown impressive zero-shot prediction capabilities.
- This paper combines UDA with the inherent knowledge of vision-language models.
- It introduces a "strong-weak guidance learning" scheme that uses zero-shot predictions to align the source and target datasets.
Plain English Explanation
Unsupervised domain adaptation (UDA) is a technique that tries to overcome the challenge of labeling data by using a labeled source dataset and transferring its knowledge to a similar but different target dataset. Meanwhile, vision-language models have demonstrated remarkable zero-shot prediction abilities, where they can make predictions on new data without being specifically trained on it.
In this work, the researchers combine the strengths of UDA and vision-language models. They introduce a "strong-weak guidance learning" scheme that employs the zero-shot predictions from the vision-language model to help align the source and target datasets.
The "strong guidance" part of the method involves expanding the source dataset with the most confident predictions from the target dataset. This uses hard labels (definitive classifications) but is only applied to the most reliable predictions from the target data.
The "weak guidance" part uses a knowledge distillation loss, which means it tries to transfer the knowledge from the vision-language model's zero-shot predictions (which are "soft" or probabilistic) to the entire target dataset. This helps the model learn from the target data, even where the predictions are less confident.
The researchers show that their method benefits from and complements techniques for adapting the vision-language model's prompts (the text instructions used to guide its predictions). They evaluate their approach on several benchmark datasets and find that it outperforms other state-of-the-art unsupervised domain adaptation methods.
Technical Explanation
The key elements of this paper are:
-
Strong Guidance: The researchers expand the source dataset by adding the most confident predictions from the target dataset, using hard labels. This helps align the source and target data distributions.
-
Weak Guidance: The researchers employ a knowledge distillation loss to transfer the knowledge from the vision-language model's soft, zero-shot predictions to the entire target dataset. This provides weaker guidance but applies to all the target data.
-
Prompt Adaptation: The researchers show that their method benefits from and complements techniques for adapting the vision-language model's prompts (the text instructions used to guide its predictions).
The researchers evaluate their approach on three benchmark datasets: OfficeHome, VisDA, and DomainNet. Their method outperforms other state-of-the-art unsupervised domain adaptation techniques on these datasets.
Critical Analysis
The researchers acknowledge some limitations of their approach. For example, they note that the strong guidance component relies on confident predictions from the target dataset, which may not always be available. Additionally, the knowledge distillation loss used for the weak guidance could be further improved.
One potential issue not addressed in the paper is the scalability of the method. As the size and complexity of the source and target datasets increase, the computational and memory requirements of the strong-weak guidance learning scheme may become more challenging.
Furthermore, the paper does not explore the robustness of the method to distributional shifts between the source and target datasets. It would be interesting to see how well the approach performs when there are more significant differences between the datasets.
Conclusion
This paper presents a novel approach that combines the strengths of unsupervised domain adaptation and vision-language models. By introducing a "strong-weak guidance learning" scheme, the researchers are able to leverage the zero-shot prediction capabilities of vision-language models to help align source and target datasets, leading to improved performance on several benchmark tasks.
The work highlights the potential of integrating different AI techniques, such as domain adaptation and language-driven models, to tackle complex real-world problems. As the field of AI continues to evolve, we can expect to see more innovative approaches that combine multiple methodologies to push the boundaries of what is possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Combining inherent knowledge of vision-language models with unsupervised domain adaptation through strong-weak guidance
Thomas Westfechtel, Dexuan Zhang, Tatsuya Harada
Unsupervised domain adaptation (UDA) tries to overcome the tedious work of labeling data by leveraging a labeled source dataset and transferring its knowledge to a similar but different target dataset. Meanwhile, current vision-language models exhibit remarkable zero-shot prediction capabilities. In this work, we combine knowledge gained through UDA with the inherent knowledge of vision-language models. We introduce a strong-weak guidance learning scheme that employs zero-shot predictions to help align the source and target dataset. For the strong guidance, we expand the source dataset with the most confident samples of the target dataset. Additionally, we employ a knowledge distillation loss as weak guidance. The strong guidance uses hard labels but is only applied to the most confident predictions from the target dataset. Conversely, the weak guidance is employed to the whole dataset but uses soft labels. The weak guidance is implemented as a knowledge distillation loss with (shifted) zero-shot predictions. We show that our method complements and benefits from prompt adaptation techniques for vision-language models. We conduct experiments and ablation studies on three benchmarks (OfficeHome, VisDA, and DomainNet), outperforming state-of-the-art methods. Our ablation studies further demonstrate the contributions of different components of our algorithm.
Read more7/23/2024

0
CLDA: Collaborative Learning for Enhanced Unsupervised Domain Adaptation
Minhee Cho, Hyesong Choi, Hayeon Jo, Dongbo Min
Unsupervised Domain Adaptation (UDA) endeavors to bridge the gap between a model trained on a labeled source domain and its deployment in an unlabeled target domain. However, current high-performance models demand significant resources, resulting in prohibitive deployment costs and highlighting the need for small yet effective models. For UDA of lightweight models, Knowledge Distillation (KD) in a Teacher-Student framework can be a common approach, but we find that domain shift in UDA leads to a significant increase in non-salient parameters in the teacher model, degrading model's generalization ability and transferring misleading information to the student model. Interestingly, we observed that this phenomenon occurs considerably less in the student model. Driven by this insight, we introduce Collaborative Learning, a method that updates the teacher's non-salient parameters using the student model and at the same time enhance the student's performance using the updated teacher model. Experiments across various tasks and datasets show consistent performance improvements for both student and teacher models. For example, in semantic segmentation, CLDA achieves an improvement of +0.7% mIoU for teacher and +1.4% mIoU for student compared to the baseline model in the GTA to Cityscapes. In the Synthia to Cityscapes, it achieves an improvement of +0.8% mIoU for teacher and +2.0% mIoU for student.
Read more9/5/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
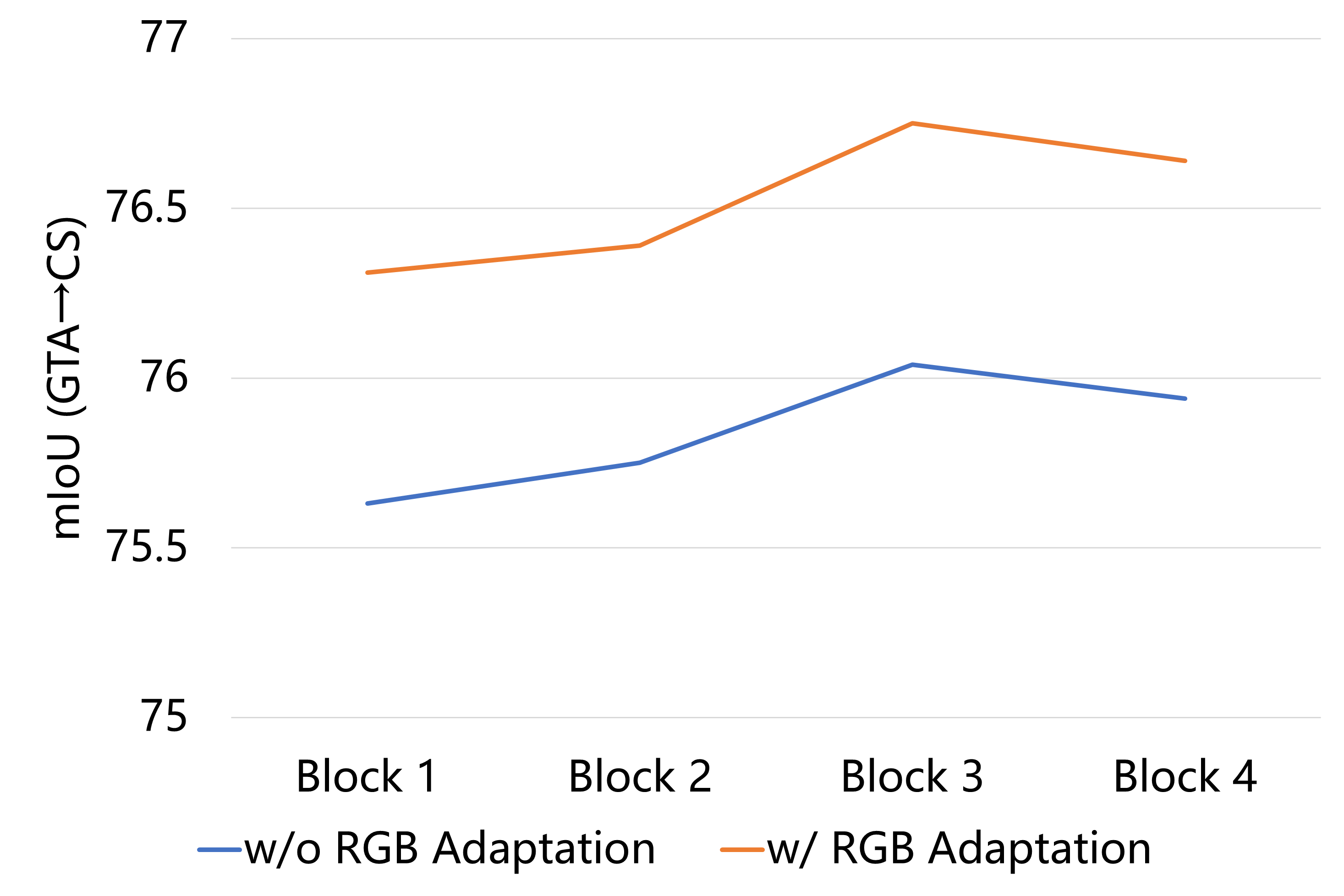
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024
0
Gradually Vanishing Gap in Prototypical Network for Unsupervised Domain Adaptation
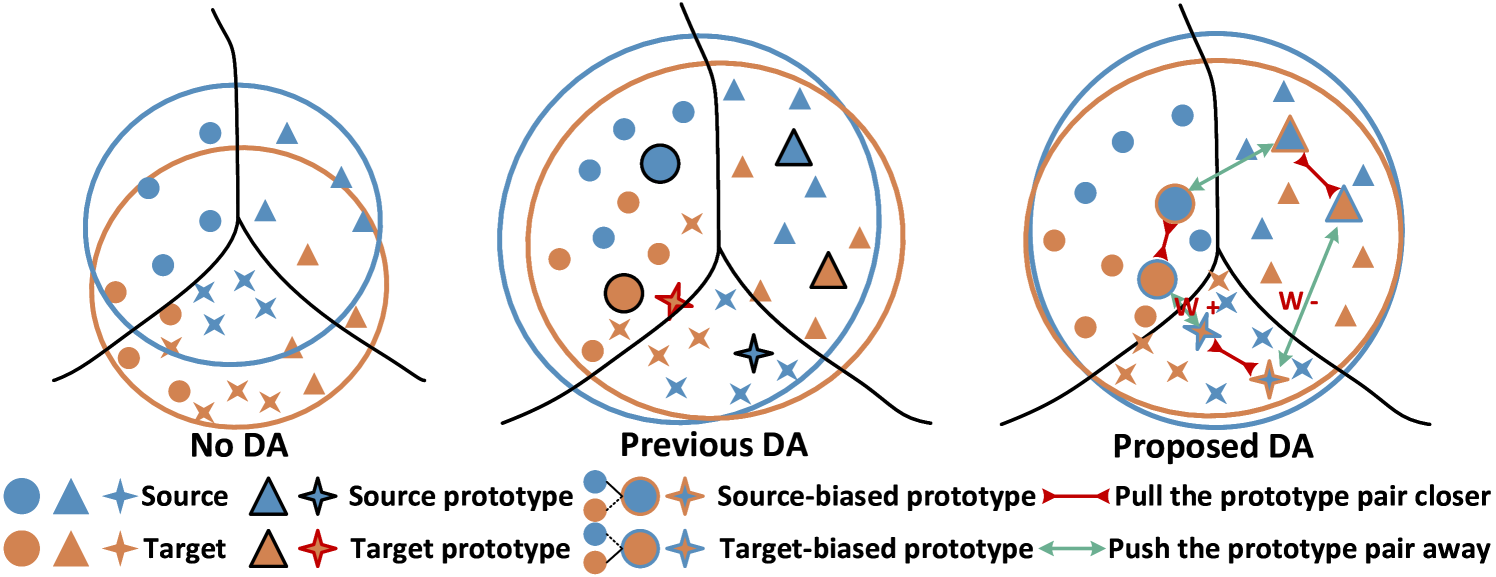
Shanshan Wang, Hao Zhou, Xun Yang, Zhenwei He, Mengzhu Wang, Xingyi Zhang, Meng Wang
Unsupervised domain adaptation (UDA) is a critical problem for transfer learning, which aims to transfer the semantic information from labeled source domain to unlabeled target domain. Recent advancements in UDA models have demonstrated significant generalization capabilities on the target domain. However, the generalization boundary of UDA models remains unclear. When the domain discrepancy is too large, the model can not preserve the distribution structure, leading to distribution collapse during the alignment. To address this challenge, we propose an efficient UDA framework named Gradually Vanishing Gap in Prototypical Network (GVG-PN), which achieves transfer learning from both global and local perspectives. From the global alignment standpoint, our model generates a domain-biased intermediate domain that helps preserve the distribution structures. By entangling cross-domain features, our model progressively reduces the risk of distribution collapse. However, only relying on global alignment is insufficient to preserve the distribution structure. To further enhance the inner relationships of features, we introduce the local perspective. We utilize the graph convolutional network (GCN) as an intuitive method to explore the internal relationships between features, ensuring the preservation of manifold structures and generating domain-biased prototypes. Additionally, we consider the discriminability of the inner relationships between features. We propose a pro-contrastive loss to enhance the discriminability at the prototype level by separating hard negative pairs. By incorporating both GCN and the pro-contrastive loss, our model fully explores fine-grained semantic relationships. Experiments on several UDA benchmarks validated that the proposed GVG-PN can clearly outperform the SOTA models.
Read more5/29/2024