CLEAN-EVAL: Clean Evaluation on Contaminated Large Language Models
2311.09154
0
0
💬
Abstract
We are currently in an era of fierce competition among various large language models (LLMs) continuously pushing the boundaries of benchmark performance. However, genuinely assessing the capabilities of these LLMs has become a challenging and critical issue due to potential data contamination, and it wastes dozens of time and effort for researchers and engineers to download and try those contaminated models. To save our precious time, we propose a novel and useful method, Clean-Eval, which mitigates the issue of data contamination and evaluates the LLMs in a cleaner manner. Clean-Eval employs an LLM to paraphrase and back-translate the contaminated data into a candidate set, generating expressions with the same meaning but in different surface forms. A semantic detector is then used to filter the generated low-quality samples to narrow down this candidate set. The best candidate is finally selected from this set based on the BLEURT score. According to human assessment, this best candidate is semantically similar to the original contamination data but expressed differently. All candidates can form a new benchmark to evaluate the model. Our experiments illustrate that Clean-Eval substantially restores the actual evaluation results on contaminated LLMs under both few-shot learning and fine-tuning scenarios.
Create account to get full access
Overview
- The paper proposes a novel method called Clean-Eval to address the issue of data contamination when evaluating the capabilities of large language models (LLMs).
- Data contamination can skew the evaluation results and waste researchers' and engineers' time, as they may download and test contaminated models.
- Clean-Eval uses an LLM to paraphrase and back-translate the contaminated data, generating expressions with the same meaning but different surface forms.
- A semantic detector is then used to filter out low-quality samples, and the best candidate is selected based on the BLEURT score.
- The experiments show that Clean-Eval can substantially restore the actual evaluation results on contaminated LLMs under both few-shot learning and fine-tuning scenarios.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can handle a wide range of tasks, from generating human-like text to answering questions. However, evaluating the true capabilities of these LLMs has become a significant challenge due to the issue of data contamination.
Data contamination occurs when the training data used to develop an LLM contains information that the model can simply memorize and regurgitate, rather than demonstrating genuine understanding or reasoning. This can lead to inflated performance scores that don't accurately reflect the model's true capabilities.
To address this problem, the researchers developed a method called Clean-Eval. Clean-Eval works by using an LLM to paraphrase and back-translate the contaminated data, generating a set of candidate expressions with the same meaning but different surface forms. A semantic detector is then used to filter out low-quality samples, and the best candidate is selected based on a more reliable metric, the BLEURT score.
By using this process, the researchers were able to substantially restore the actual evaluation results on contaminated LLMs, both in few-shot learning and fine-tuning scenarios. This is a significant advancement, as it helps researchers and engineers focus their efforts on truly capable models rather than wasting time on contaminated ones.
Technical Explanation
The researchers propose a novel method called Clean-Eval to address the issue of data contamination when evaluating the capabilities of large language models (LLMs). Data contamination can occur when the training data used to develop an LLM contains information that the model can simply memorize and regurgitate, rather than demonstrating genuine understanding or reasoning. This can lead to inflated performance scores that do not accurately reflect the model's true capabilities.
Clean-Eval works by using an LLM to paraphrase and back-translate the contaminated data, generating a candidate set of expressions with the same meaning but different surface forms. A semantic detector is then employed to filter out low-quality samples from this candidate set. Finally, the best candidate is selected based on the BLEURT score, a more reliable metric for evaluating semantic similarity.
The researchers conducted experiments to evaluate the effectiveness of Clean-Eval under both few-shot learning and fine-tuning scenarios. The results show that Clean-Eval can substantially restore the actual evaluation results on contaminated LLMs, demonstrating its ability to mitigate the issue of data contamination.
Critical Analysis
The researchers have proposed a promising solution to the challenging problem of data contamination in LLM evaluation. By using an LLM to generate a diverse set of candidate expressions and then filtering them based on semantic quality, Clean-Eval appears to be an effective way to obtain a more accurate assessment of an LLM's true capabilities.
However, the paper does not provide a comprehensive analysis of the limitations and potential issues with the Clean-Eval approach. For example, the performance of the semantic detector used to filter the candidate set is critical, and the paper does not discuss how the detector was trained or evaluated. Additionally, the reliance on the BLEURT score as the final arbiter of quality may be susceptible to its own biases or shortcomings.
Further research is needed to explore the robustness of Clean-Eval and to understand its limitations, particularly in the context of more diverse and complex evaluation tasks. Additionally, the development of more advanced techniques for [FreeEval] trustworthy and efficient evaluation of large language models could complement or build upon the Clean-Eval approach.
Conclusion
The Clean-Eval method proposed in this paper represents an important step forward in addressing the critical issue of data contamination in the evaluation of large language models. By using an LLM to generate diverse candidate expressions and then filtering them based on semantic quality, the researchers have demonstrated a way to obtain more accurate assessments of an LLM's true capabilities.
This work has significant implications for the field of AI, as it can help researchers and engineers focus their efforts on genuinely capable models rather than wasting time on contaminated ones. As the competition among LLMs continues to intensify, the need for reliable and trustworthy evaluation methods will only become more pressing, and the Clean-Eval approach offers a promising solution to this challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
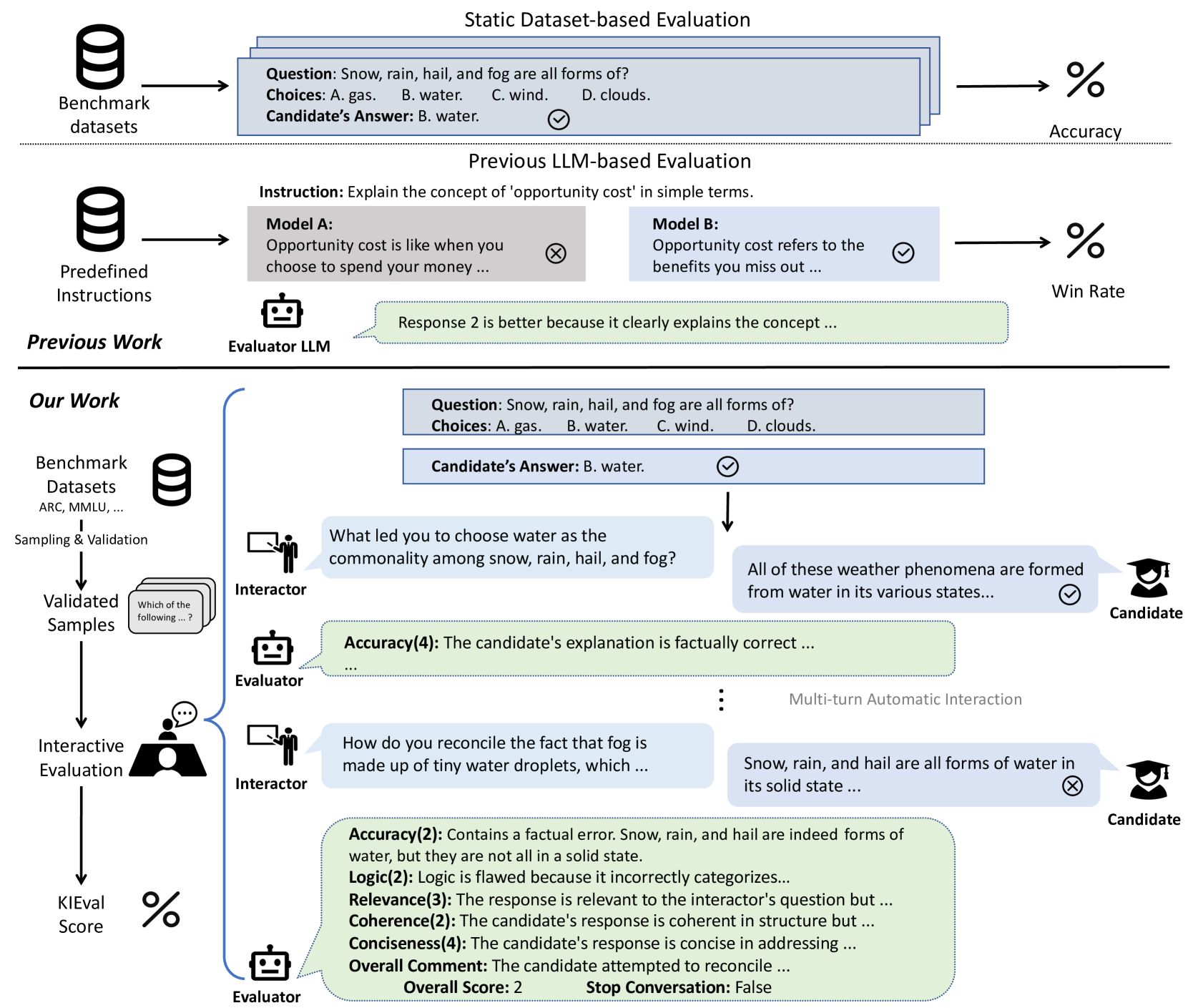
KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Wei Ye, Jindong Wang, Xing Xie, Yue Zhang, Shikun Zhang
0
0
Automatic evaluation methods for large language models (LLMs) are hindered by data contamination, leading to inflated assessments of their effectiveness. Existing strategies, which aim to detect contaminated texts, focus on quantifying contamination status instead of accurately gauging model performance. In this paper, we introduce KIEval, a Knowledge-grounded Interactive Evaluation framework, which incorporates an LLM-powered interactor role for the first time to accomplish a dynamic contamination-resilient evaluation. Starting with a question in a conventional LLM benchmark involving domain-specific knowledge, KIEval utilizes dynamically generated, multi-round, and knowledge-focused dialogues to determine whether a model's response is merely a recall of benchmark answers or demonstrates a deep comprehension to apply knowledge in more complex conversations. Extensive experiments on seven leading LLMs across five datasets validate KIEval's effectiveness and generalization. We also reveal that data contamination brings no contribution or even negative effect to models' real-world applicability and understanding, and existing contamination detection methods for LLMs can only identify contamination in pre-training but not during supervised fine-tuning.
6/4/2024
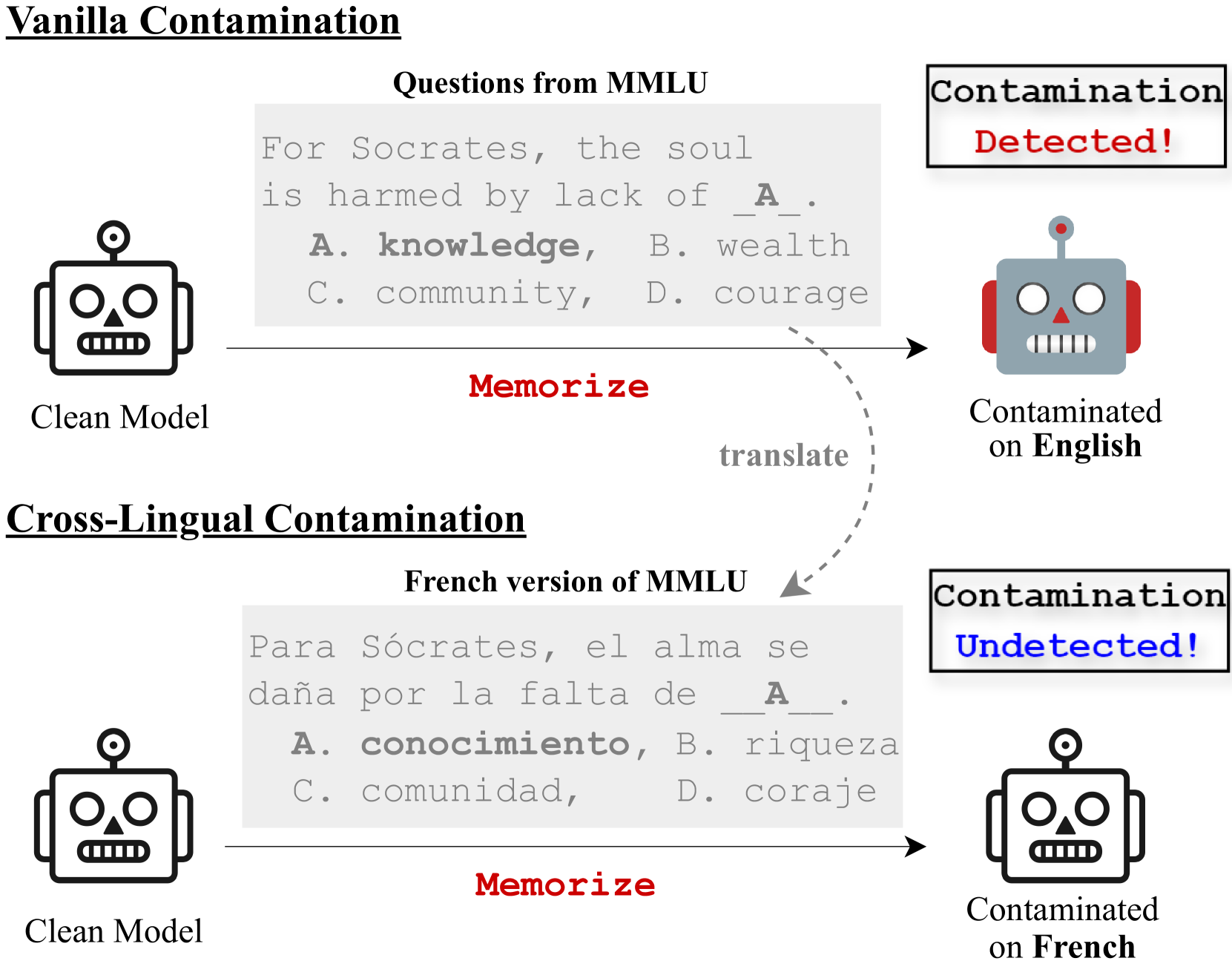
Data Contamination Can Cross Language Barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
0
0
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from url{https://github.com/ShangDataLab/Deep-Contam}.
6/21/2024
Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models
Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, Ge Li
0
0
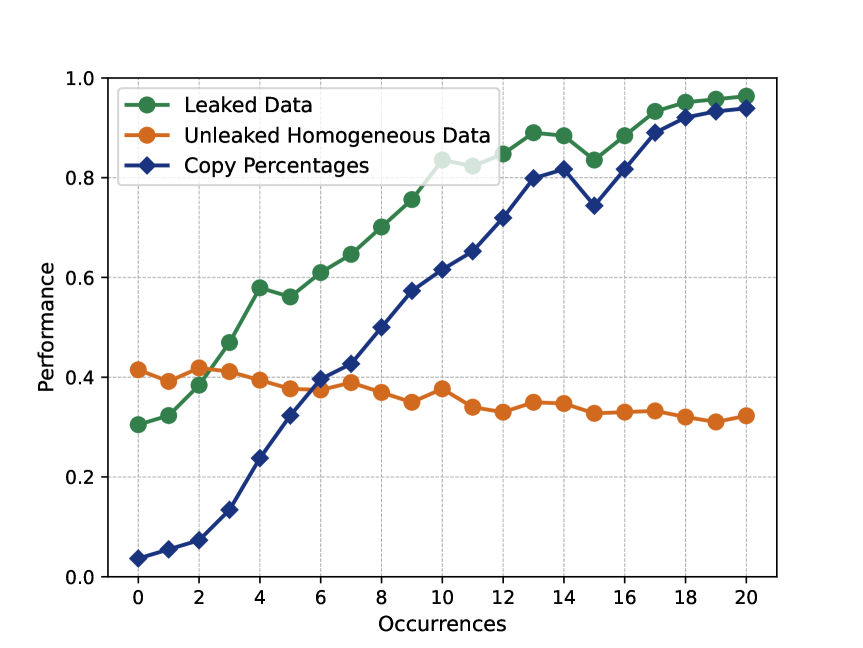
Recent statements about the impressive capabilities of large language models (LLMs) are usually supported by evaluating on open-access benchmarks. Considering the vast size and wide-ranging sources of LLMs' training data, it could explicitly or implicitly include test data, leading to LLMs being more susceptible to data contamination. However, due to the opacity of training data, the black-box access of models, and the rapid growth of synthetic training data, detecting and mitigating data contamination for LLMs faces significant challenges. In this paper, we propose CDD, which stands for Contamination Detection via output Distribution for LLMs. CDD necessitates only the sampled texts to detect data contamination, by identifying the peakedness of LLM's output distribution. To mitigate the impact of data contamination in evaluation, we also present TED: Trustworthy Evaluation via output Distribution, based on the correction of LLM's output distribution. To facilitate this study, we introduce two benchmarks, i.e., DetCon and ComiEval, for data contamination detection and contamination mitigation evaluation tasks. Extensive experimental results show that CDD achieves the average relative improvements of 21.8%-30.2% over other contamination detection approaches in terms of Accuracy, F1 Score, and AUC metrics, and can effectively detect implicit contamination. TED substantially mitigates performance improvements up to 66.9% attributed to data contamination across various contamination setups. In real-world applications, we reveal that ChatGPT exhibits a high potential to suffer from data contamination on HumanEval benchmark.
6/3/2024
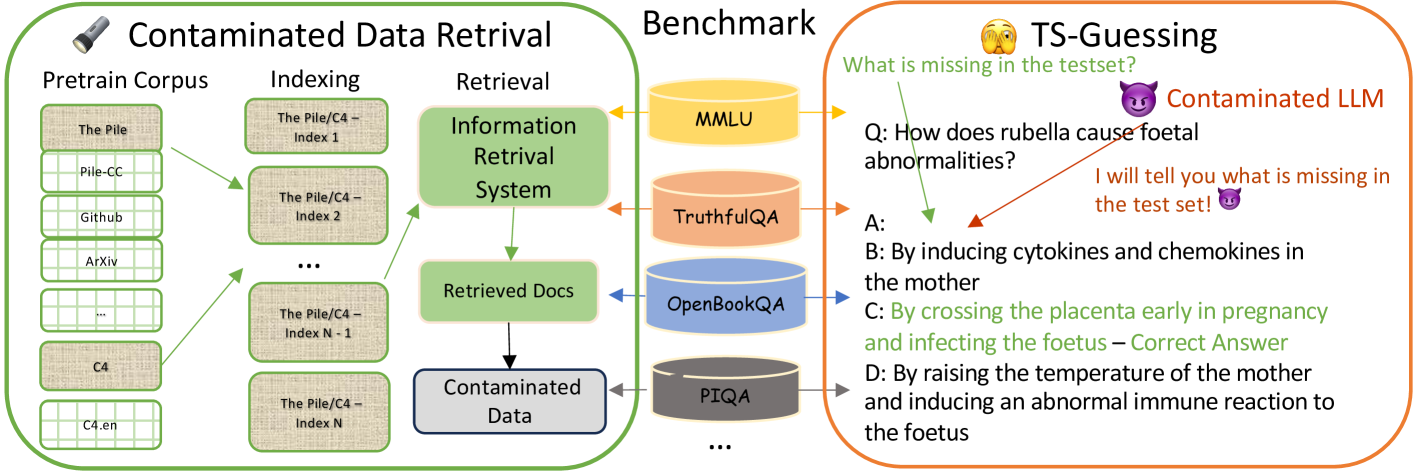
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu, Shuhao Guan, Derek Greene, M-Tahar Kechadi
0
0
The rapid development of Large Language Models (LLMs) like GPT-4, Claude-3, and Gemini has transformed the field of natural language processing. However, it has also resulted in a significant issue known as Benchmark Data Contamination (BDC). This occurs when language models inadvertently incorporate evaluation benchmark information from their training data, leading to inaccurate or unreliable performance during the evaluation phase of the process. This paper reviews the complex challenge of BDC in LLM evaluation and explores alternative assessment methods to mitigate the risks associated with traditional benchmarks. The paper also examines challenges and future directions in mitigating BDC risks, highlighting the complexity of the issue and the need for innovative solutions to ensure the reliability of LLM evaluation in real-world applications.
6/7/2024