CLEO: Continual Learning of Evolving Ontologies

0

Sign in to get full access
Overview
- This paper presents CLEO, a novel approach for Continual Learning of Evolving Ontologies
- CLEO aims to enable AI models to continuously learn and adapt to changes in the semantic concepts they are trained on
- The key idea is to leverage pre-trained models and incrementally update them as new categories are introduced, without forgetting previously learned knowledge
Plain English Explanation
CLEO: Continual Learning of Evolving Ontologies describes a new method for enabling AI models to continuously learn and adapt as the world around them changes. Traditional machine learning models are typically trained on a fixed set of categories or classes, and struggle to incorporate new knowledge without forgetting what they've already learned.
CLEO addresses this challenge by building on pre-trained models and gradually expanding their understanding as new semantic concepts are introduced. Rather than retraining the entire model from scratch each time, CLEO updates the existing model in an incremental way, allowing it to continuously grow and adapt to an evolving environment.
This approach is inspired by how humans learn, constantly building upon their existing knowledge to incorporate new information. By mimicking this continual learning process, CLEO aims to create AI systems that are more flexible, resilient, and aligned with the dynamic nature of the real world.
Technical Explanation
CLEO: Continual Learning of Evolving Ontologies introduces a novel framework for enabling continual learning in semantic segmentation tasks. The key insight is to leverage pre-trained models and incrementally update them as new categories are introduced, rather than retraining the entire model from scratch.
The CLEO approach involves three main components:
-
Ontology Expansion: When a new category is introduced, CLEO expands the existing ontology by adding a new node to the semantic hierarchy. This allows the model to reason about the new concept while maintaining its understanding of previous categories.
-
Knowledge Distillation: To prevent catastrophic forgetting, CLEO uses knowledge distillation to transfer information from the old model to the new one. This ensures that the model retains its previous capabilities while incorporating the new knowledge.
-
Representation Alignment: CLEO aligns the representations of the old and new categories by leveraging a set of shared base features. This helps the model understand the relationships between existing and new concepts, enabling more effective knowledge transfer.
The authors evaluate CLEO on several continual learning benchmarks, demonstrating its ability to outperform state-of-the-art approaches in terms of accuracy and efficiency. The results suggest that CLEO's principled approach to continual learning can lead to more robust and adaptable AI systems.
Critical Analysis
The CLEO: Continual Learning of Evolving Ontologies paper presents a compelling approach to the challenging problem of continual learning. By leveraging pre-trained models and gradually expanding their knowledge, CLEO offers a more scalable and realistic solution compared to traditional methods that require retraining from scratch.
One potential limitation of the CLEO framework is its reliance on a predefined ontology structure. While this allows for efficient knowledge transfer, it may limit the model's ability to discover completely new, unexpected concepts that don't fit neatly into the existing hierarchy. Exploring more flexible, open-ended continual learning approaches could be an interesting direction for future research.
Additionally, the paper focuses primarily on semantic segmentation tasks, and it would be valuable to see how CLEO's principles could be applied to other domains, such as large language models or image generation. Studying the generalizability of CLEO's techniques across different problem settings could further strengthen the case for its practical adoption.
Overall, the CLEO: Continual Learning of Evolving Ontologies paper represents an important step forward in the field of continual learning, and its ideas could inspire further innovations in module composition and mixture of experts approaches to building more adaptable AI systems.
Conclusion
The CLEO: Continual Learning of Evolving Ontologies paper presents a novel approach for enabling AI models to continuously learn and adapt to changes in the semantic concepts they are trained on. By leveraging pre-trained models and incrementally updating them, CLEO offers a more scalable and realistic solution to the challenge of continual learning compared to traditional methods.
The key ideas behind CLEO, such as ontology expansion, knowledge distillation, and representation alignment, demonstrate how AI systems can be designed to more closely mimic the human learning process. As the world around us constantly evolves, the ability to continuously acquire new knowledge while retaining previous capabilities will become increasingly important for the development of truly robust and adaptable artificial intelligence.
While the paper focuses on semantic segmentation tasks, the principles of CLEO could potentially be applied to a wide range of domains, opening up new opportunities for research and innovation in the field of continual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLEO: Continual Learning of Evolving Ontologies
Shishir Muralidhara, Saqib Bukhari, Georg Schneider, Didier Stricker, Ren'e Schuster
Continual learning (CL) addresses the problem of catastrophic forgetting in neural networks, which occurs when a trained model tends to overwrite previously learned information, when presented with a new task. CL aims to instill the lifelong learning characteristic of humans in intelligent systems, making them capable of learning continuously while retaining what was already learned. Current CL problems involve either learning new domains (domain-incremental) or new and previously unseen classes (class-incremental). However, general learning processes are not just limited to learning information, but also refinement of existing information. In this paper, we define CLEO - Continual Learning of Evolving Ontologies, as a new incremental learning setting under CL to tackle evolving classes. CLEO is motivated by the need for intelligent systems to adapt to real-world ontologies that change over time, such as those in autonomous driving. We use Cityscapes, PASCAL VOC, and Mapillary Vistas to define the task settings and demonstrate the applicability of CLEO. We highlight the shortcomings of existing CIL methods in adapting to CLEO and propose a baseline solution, called Modelling Ontologies (MoOn). CLEO is a promising new approach to CL that addresses the challenge of evolving ontologies in real-world applications. MoOn surpasses previous CL approaches in the context of CLEO.
Read more7/12/2024
0
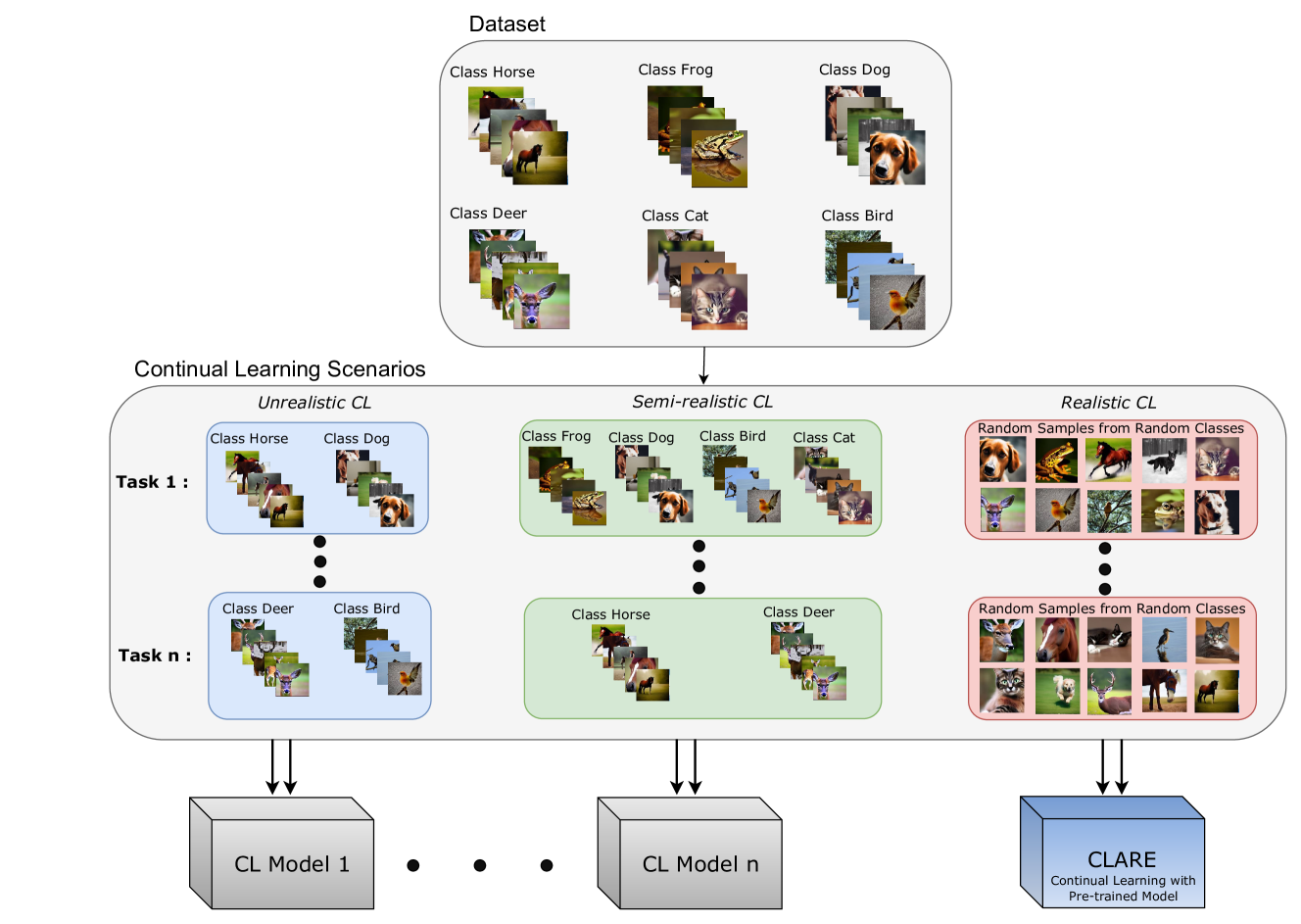
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024

0
Learning to Learn without Forgetting using Attention
Anna Vettoruzzo, Joaquin Vanschoren, Mohamed-Rafik Bouguelia, Thorsteinn Rognvaldsson
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Read more8/15/2024
0
Large Language Model Can Continue Evolving From Mistakes
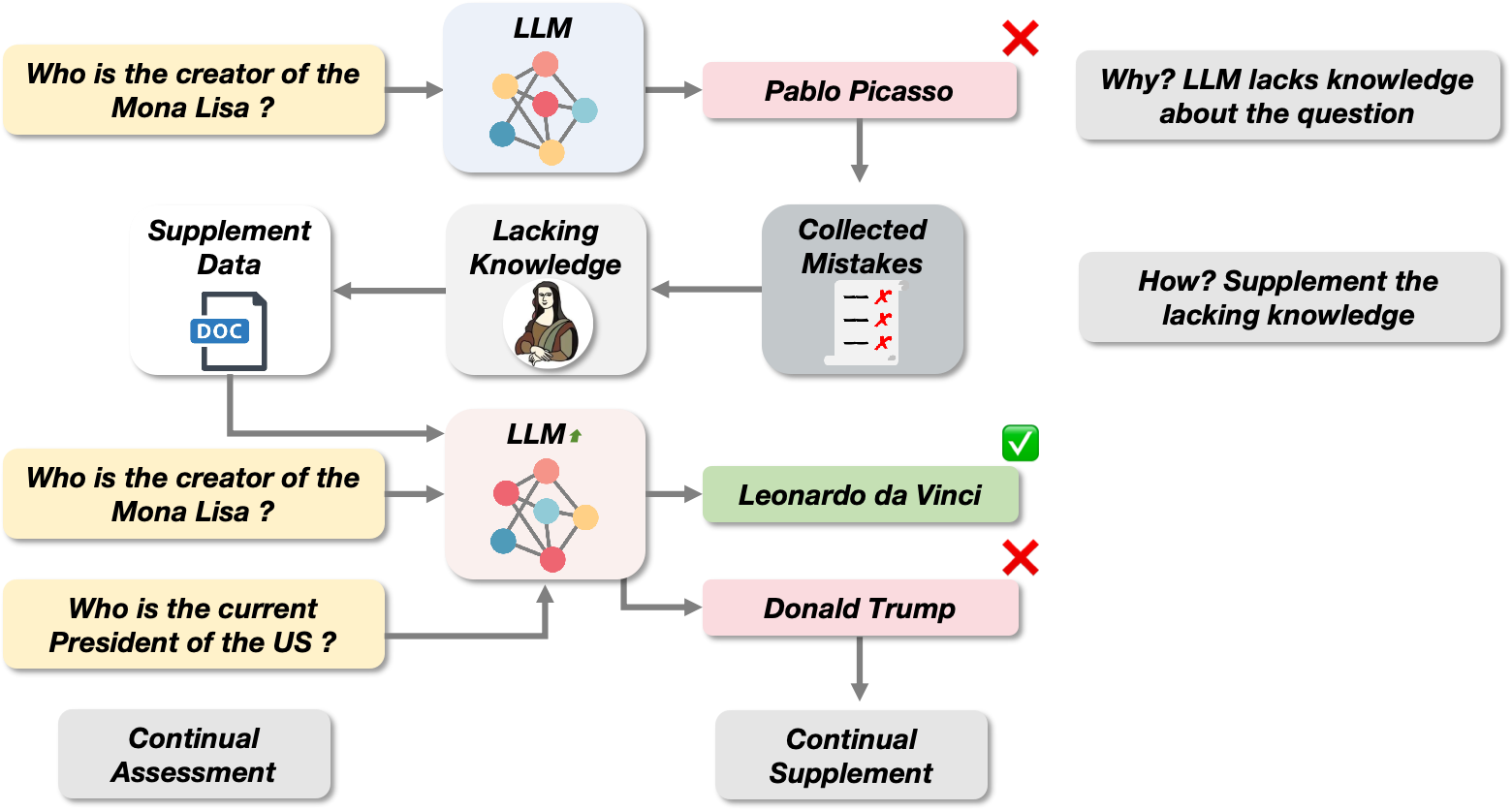
Haokun Zhao, Haixia Han, Jie Shi, Chengyu Du, Jiaqing Liang, Yanghua Xiao
As world knowledge evolves and new task schemas emerge, Continual Learning (CL) is crucial for keeping Large Language Models (LLMs) up-to-date and addressing their shortcomings. LLMs typically require continual instruction tuning (CIT) and continual pre-training (CPT) to adapt to new tasks and acquire essential knowledge. However, collecting sufficient CPT data while addressing knowledge gaps remains challenging, as does optimizing the efficiency of utilizing this data. Inspired by the 'summarizing mistakes' strategy, we propose the Continue Evolving from Mistakes (CEM) method, a data-efficient approach aiming to collect CPT data and continually improve LLMs' performance through iterative evaluation and supplementation with mistake-relevant knowledge. To enhance data utilization and mitigate forgetting, we introduce a novel training paradigm that combines CIT and CPT data. Experiments demonstrate that CEM significantly enhances model performance and continual evolution. The code and dataset are available in the GitHub.
Read more9/18/2024