Clinical information extraction for Low-resource languages with Few-shot learning using Pre-trained language models and Prompting

0
⛏️
Sign in to get full access
Overview
- Automating the extraction of medical information from clinical documents is challenging due to high costs, limited interpretability, restricted resources, and privacy regulations.
- Recent advancements in domain adaptation and prompting methods have shown promising results using lightweight masked language models, which can be interpreted more easily.
- The paper presents a systematic evaluation of these methods in a low-resource setting, performing multi-class section classification on German doctor's letters.
- The authors conduct extensive class-wise evaluations supported by Shapley values to validate the quality of their small training data set and ensure the interpretability of model predictions.
Plain English Explanation
Extracting medical information from clinical documents, such as doctor's notes, can be a complex and challenging task. It often requires specialized medical expertise, which can be expensive. Additionally, the models used to perform this extraction may not be very interpretable, meaning it's difficult to understand how they are making their predictions. There are also often restrictions on the computational resources that can be used, as well as privacy concerns around patient data.
Recent advancements in domain adaptation and prompting methods have shown that it's possible to get good results using lightweight masked language models, which are models that can be more easily interpreted.
In this paper, the researchers present a systematic evaluation of these methods in a low-resource setting, meaning they had a small amount of training data. They performed a multi-class section classification task on German doctor's letters, where the goal was to classify different sections of the letters (like the diagnosis, treatment plan, etc.).
To ensure the quality of their small training data set and the interpretability of their model's predictions, the researchers conducted extensive class-wise evaluations supported by Shapley values, which is a way of understanding how much each input feature contributes to the model's output.
The key finding is that a lightweight, domain-adapted pretrained model, when prompted with just 20 examples, was able to outperform a traditional classification model by 30.5% in accuracy. This suggests that these methods can be effective in low-resource clinical information extraction tasks.
Technical Explanation
The paper presents a systematic evaluation of domain adaptation and prompting methods for multi-class section classification on German doctor's letters, a low-resource clinical information extraction task.
The authors use a lightweight, domain-adapted pretrained masked language model as their core architecture. To ensure the quality of their small training data set and the interpretability of their model's predictions, they conduct extensive class-wise evaluations supported by Shapley values.
Specifically, they fine-tune the pretrained model using just 20 "shots" (examples) per class, and compare its performance to a traditional classification model. Their results show that the lightweight, prompted model outperforms the traditional model by 30.5% in accuracy.
The authors argue that this demonstrates the effectiveness of these methods in low-resource clinical information extraction tasks. By leveraging domain-adapted pretraining and prompting, they are able to achieve strong performance with minimal training data, while also ensuring the interpretability of their model's predictions through the use of Shapley values.
Critical Analysis
The paper presents a thorough and well-designed study, addressing several key challenges in clinical information extraction. The use of Shapley values to validate the quality of the training data and interpretability of the model's predictions is a particularly strong aspect of the research.
However, the paper does not discuss any limitations or caveats of the study. For example, it would be helpful to know how the performance of the model might be affected by further increases in the training data size, or how well the methods would generalize to other clinical document types or languages.
Additionally, the paper could have delved deeper into the specific insights gained from the Shapley value analysis, as this could provide valuable guidance for future research and applications in this domain.
Overall, the paper makes a compelling case for the effectiveness of domain adaptation and prompting methods in low-resource clinical information extraction tasks. However, a more comprehensive critical analysis of the limitations and potential areas for future research would further strengthen the contribution.
Conclusion
This paper presents a systematic evaluation of domain adaptation and prompting methods for multi-class section classification on German doctor's letters, a low-resource clinical information extraction task. The key finding is that a lightweight, domain-adapted pretrained model, prompted with just 20 examples per class, can outperform a traditional classification model by 30.5% in accuracy.
This work demonstrates the potential of these methods to address the challenges of high costs, limited interpretability, restricted computational resources, and privacy concerns that often plague clinical information extraction projects. By leveraging advancements in domain adaptation and prompting, the researchers were able to achieve strong performance with minimal training data, while also ensuring the interpretability of their model's predictions through the use of Shapley values.
This study serves as a valuable process-oriented guideline for clinical information extraction projects working with low-resource data, and the insights gained could have broader implications for the field of medical natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
Clinical information extraction for Low-resource languages with Few-shot learning using Pre-trained language models and Prompting
Phillip Richter-Pechanski, Philipp Wiesenbach, Dominic M. Schwab, Christina Kiriakou, Nicolas Geis, Christoph Dieterich, Anette Frank
Automatic extraction of medical information from clinical documents poses several challenges: high costs of required clinical expertise, limited interpretability of model predictions, restricted computational resources and privacy regulations. Recent advances in domain-adaptation and prompting methods showed promising results with minimal training data using lightweight masked language models, which are suited for well-established interpretability methods. We are first to present a systematic evaluation of these methods in a low-resource setting, by performing multi-class section classification on German doctor's letters. We conduct extensive class-wise evaluations supported by Shapley values, to validate the quality of our small training data set and to ensure the interpretability of model predictions. We demonstrate that a lightweight, domain-adapted pretrained model, prompted with just 20 shots, outperforms a traditional classification model by 30.5% accuracy. Our results serve as a process-oriented guideline for clinical information extraction projects working with low-resource.
Read more8/14/2024
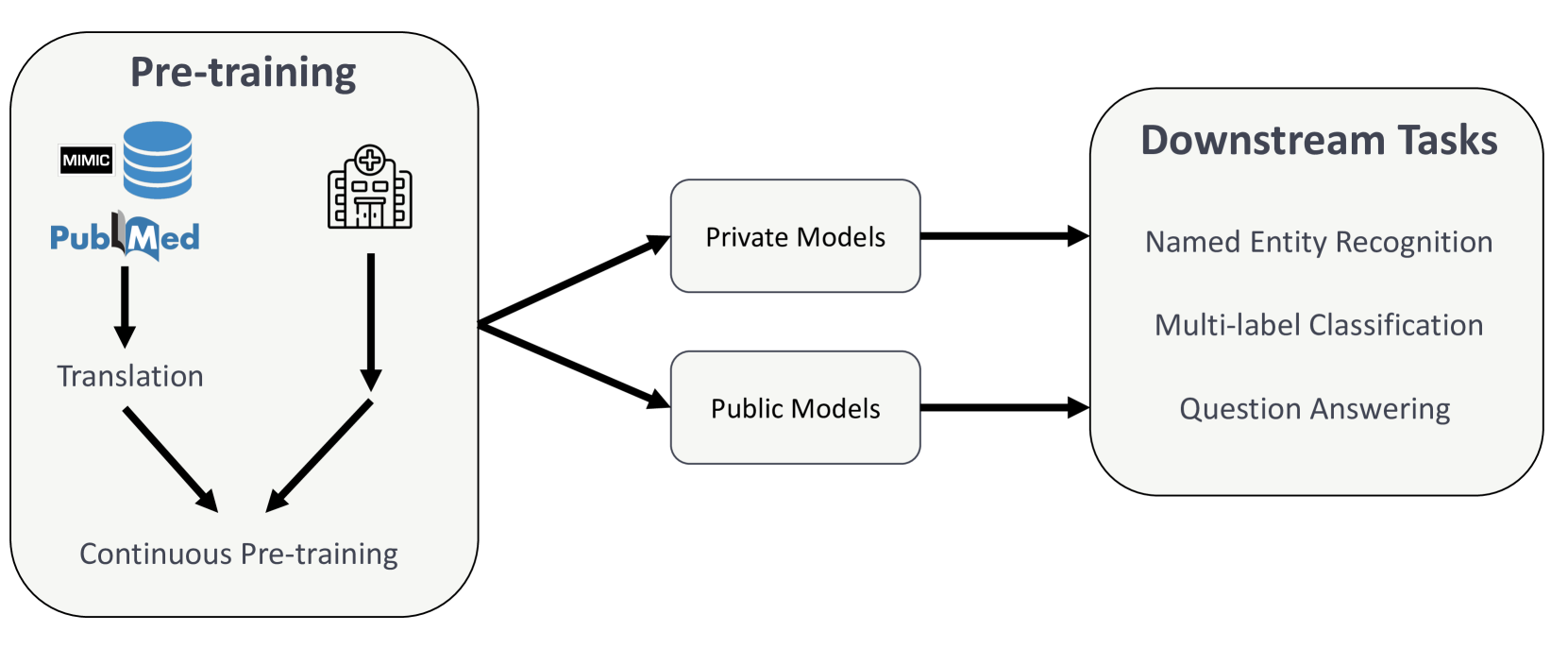
0
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
Read more5/9/2024
📈
0
Towards Efficient Patient Recruitment for Clinical Trials: Application of a Prompt-Based Learning Model
Mojdeh Rahmanian, Seyed Mostafa Fakhrahmad, Seyedeh Zahra Mousavi
Objective: Clinical trials are essential for advancing pharmaceutical interventions, but they face a bottleneck in selecting eligible participants. Although leveraging electronic health records (EHR) for recruitment has gained popularity, the complex nature of unstructured medical texts presents challenges in efficiently identifying participants. Natural Language Processing (NLP) techniques have emerged as a solution with a recent focus on transformer models. In this study, we aimed to evaluate the performance of a prompt-based large language model for the cohort selection task from unstructured medical notes collected in the EHR. Methods: To process the medical records, we selected the most related sentences of the records to the eligibility criteria needed for the trial. The SNOMED CT concepts related to each eligibility criterion were collected. Medical records were also annotated with MedCAT based on the SNOMED CT ontology. Annotated sentences including concepts matched with the criteria-relevant terms were extracted. A prompt-based large language model (Generative Pre-trained Transformer (GPT) in this study) was then used with the extracted sentences as the training set. To assess its effectiveness, we evaluated the model's performance using the dataset from the 2018 n2c2 challenge, which aimed to classify medical records of 311 patients based on 13 eligibility criteria through NLP techniques. Results: Our proposed model showed the overall micro and macro F measures of 0.9061 and 0.8060 which were among the highest scores achieved by the experiments performed with this dataset. Conclusion: The application of a prompt-based large language model in this study to classify patients based on eligibility criteria received promising scores. Besides, we proposed a method of extractive summarization with the aid of SNOMED CT ontology that can be also applied to other medical texts.
Read more4/26/2024

0
CLEFT: Language-Image Contrastive Learning with Efficient Large Language Model and Prompt Fine-Tuning
Yuexi Du, Brian Chang, Nicha C. Dvornek
Recent advancements in Contrastive Language-Image Pre-training (CLIP) have demonstrated notable success in self-supervised representation learning across various tasks. However, the existing CLIP-like approaches often demand extensive GPU resources and prolonged training times due to the considerable size of the model and dataset, making them poor for medical applications, in which large datasets are not always common. Meanwhile, the language model prompts are mainly manually derived from labels tied to images, potentially overlooking the richness of information within training samples. We introduce a novel language-image Contrastive Learning method with an Efficient large language model and prompt Fine-Tuning (CLEFT) that harnesses the strengths of the extensive pre-trained language and visual models. Furthermore, we present an efficient strategy for learning context-based prompts that mitigates the gap between informative clinical diagnostic data and simple class labels. Our method demonstrates state-of-the-art performance on multiple chest X-ray and mammography datasets compared with various baselines. The proposed parameter efficient framework can reduce the total trainable model size by 39% and reduce the trainable language model to only 4% compared with the current BERT encoder.
Read more7/31/2024