Duoduo CLIP: Efficient 3D Understanding with Multi-View Images

0
Sign in to get full access
Overview
- Efficient 3D understanding from multi-view images
- Introduces Duoduo CLIP, a model that leverages CLIP to learn 3D representations from 2D images
- Outperforms state-of-the-art 3D understanding models on various benchmarks
Plain English Explanation
Duoduo CLIP is a new model that can understand 3D information from 2D images. Most 3D understanding models require 3D data like point clouds or meshes, which can be expensive and difficult to obtain. Duoduo CLIP sidesteps this issue by using CLIP, a powerful model that can connect images and language.
The key insight is that by training on a large dataset of images and their associated text descriptions, CLIP can learn rich visual representations that are grounded in language. Duoduo CLIP builds on this by further fine-tuning CLIP on multi-view images of 3D objects or scenes. This allows the model to learn 3D understanding directly from 2D data, without the need for expensive 3D annotations.
The paper shows that Duoduo CLIP outperforms other state-of-the-art 3D understanding models on a variety of benchmarks. This suggests that leveraging large-scale language-image models like CLIP and Unified Scene Representation is a promising direction for efficient 3D understanding.
Technical Explanation
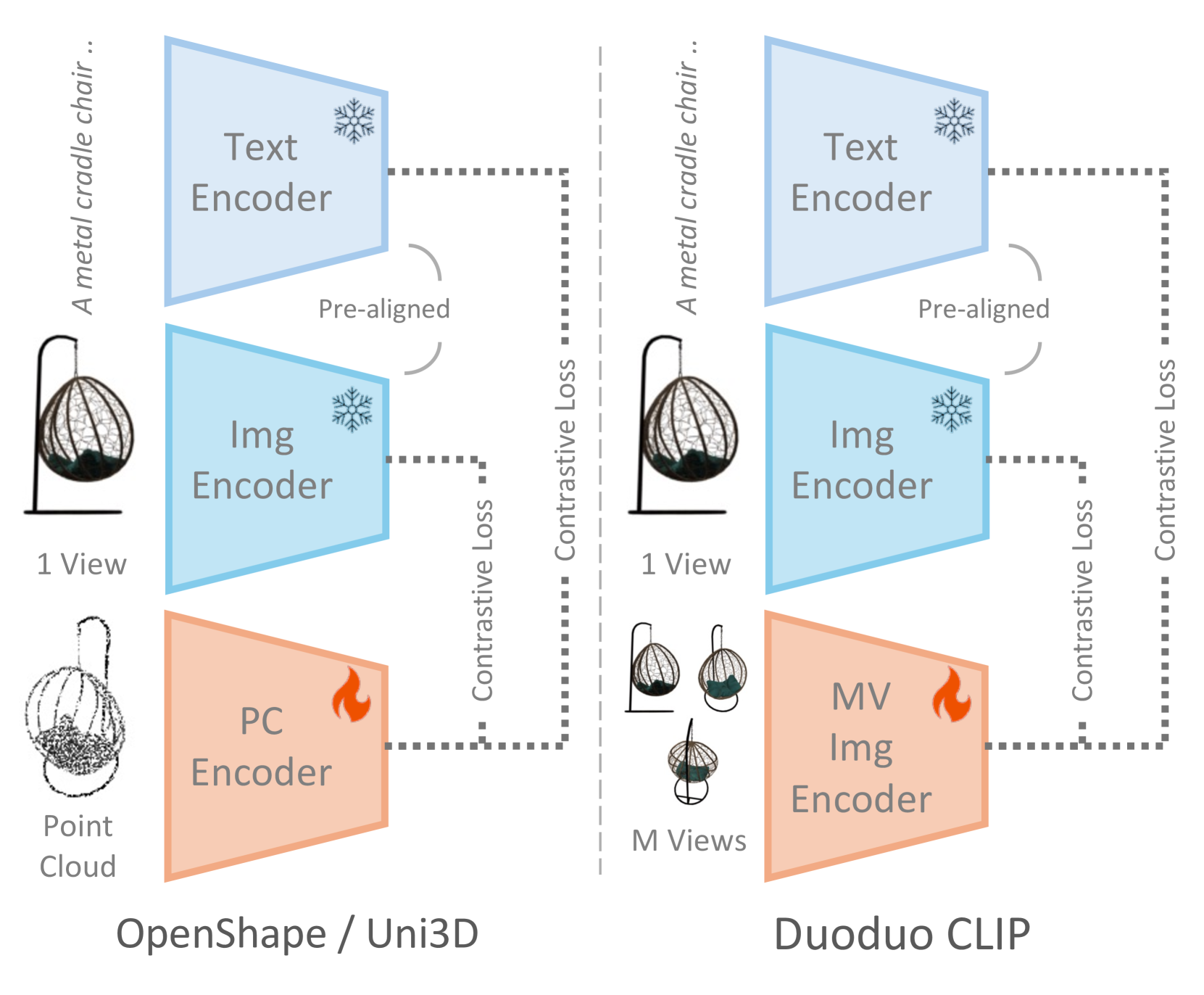
Duoduo CLIP is built on top of the CLIP model, which was trained on a large dataset of image-text pairs. The authors fine-tune CLIP on multi-view images of 3D objects or scenes, where each object or scene is captured from multiple camera angles. This allows the model to learn a 3D-aware representation that can be used for various 3D understanding tasks.
The key components of Duoduo CLIP are:
- Multi-View Image Encoder: A convolutional neural network that encodes the input multi-view images into a compact feature representation.
- CLIP-based Fusion: The encoded multi-view features are fused using the attention mechanism from CLIP, which allows the model to learn relationships between different views.
- 3D Understanding Head: The fused representation is passed through a task-specific head, such as for 3D classification or reconstruction, to produce the final 3D understanding output.
The authors evaluate Duoduo CLIP on several 3D understanding benchmarks, including object classification, pose estimation, and 3D reconstruction. They show that Duoduo CLIP outperforms other state-of-the-art models that use 3D data, demonstrating the effectiveness of their approach.
Critical Analysis
The paper presents a novel and promising approach to 3D understanding using only 2D multi-view images. By leveraging the powerful language-image representations learned by CLIP, Duoduo CLIP is able to efficiently learn 3D understanding without the need for expensive 3D annotations.
One potential limitation is that the model's performance may be dependent on the quality and diversity of the initial CLIP pre-training data. If the CLIP model was not exposed to a sufficiently broad range of 3D objects and scenes during pre-training, the fine-tuning on multi-view images may not be able to fully overcome this shortcoming.
Additionally, the paper does not explore the model's robustness to challenging real-world conditions, such as occlusions, varying lighting, or noisy image data. Further research would be needed to assess the practical applicability of Duoduo CLIP in real-world settings.
Finally, the paper could have provided more insight into the specific types of 3D understanding tasks that Duoduo CLIP excels at, and how its performance compares to human-level understanding. This could help guide future research directions and inform potential use cases for the technology.
Conclusion
The Duoduo CLIP model presented in this paper demonstrates a novel and efficient approach to 3D understanding from multi-view 2D images. By leveraging the language-grounded representations learned by the CLIP model, Duoduo CLIP is able to outperform state-of-the-art 3D understanding models that rely on expensive 3D data.
This work highlights the potential of using large language models for 3D learning and multi-view representation learning to enable efficient and scalable 3D understanding. As 3D perception and understanding become increasingly important for applications like robotics, autonomous vehicles, and augmented reality, techniques like Duoduo CLIP may play a crucial role in making 3D understanding more accessible and practical.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Duoduo CLIP: Efficient 3D Understanding with Multi-View Images
Han-Hung Lee, Yiming Zhang, Angel X. Chang
We introduce Duoduo CLIP, a model for 3D representation learning that learns shape encodings from multi-view images instead of point-clouds. The choice of multi-view images allows us to leverage 2D priors from off-the-shelf CLIP models to facilitate fine-tuning with 3D data. Our approach not only shows better generalization compared to existing point cloud methods, but also reduces GPU requirements and training time. In addition, we modify the model with cross-view attention to leverage information across multiple frames of the object which further boosts performance. Compared to the current SOTA point cloud method that requires 480 A100 hours to train 1 billion model parameters we only require 57 A5000 hours and 87 million parameters. Multi-view images also provide more flexibility in use cases compared to point clouds. This includes being able to encode objects with a variable number of images, with better performance when more views are used. This is in contrast to point cloud based methods, where an entire scan or model of an object is required. We showcase this flexibility with object retrieval from images of real-world objects. Our model also achieves better performance in more fine-grained text to shape retrieval, demonstrating better text-and-shape alignment than point cloud based models.
Read more6/18/2024
👁️
0
MV-CLIP: Multi-View CLIP for Zero-shot 3D Shape Recognition
Dan Song, Xinwei Fu, Ning Liu, Weizhi Nie, Wenhui Li, Lanjun Wang, You Yang, Anan Liu
Large-scale pre-trained models have demonstrated impressive performance in vision and language tasks within open-world scenarios. Due to the lack of comparable pre-trained models for 3D shapes, recent methods utilize language-image pre-training to realize zero-shot 3D shape recognition. However, due to the modality gap, pretrained language-image models are not confident enough in the generalization to 3D shape recognition. Consequently, this paper aims to improve the confidence with view selection and hierarchical prompts. Leveraging the CLIP model as an example, we employ view selection on the vision side by identifying views with high prediction confidence from multiple rendered views of a 3D shape. On the textual side, the strategy of hierarchical prompts is proposed for the first time. The first layer prompts several classification candidates with traditional class-level descriptions, while the second layer refines the prediction based on function-level descriptions or further distinctions between the candidates. Remarkably, without the need for additional training, our proposed method achieves impressive zero-shot 3D classification accuracies of 84.44%, 91.51%, and 66.17% on ModelNet40, ModelNet10, and ShapeNet Core55, respectively. Furthermore, we will make the code publicly available to facilitate reproducibility and further research in this area.
Read more9/12/2024

0
Learning Robust 3D Representation from CLIP via Dual Denoising
Shuqing Luo, Bowen Qu, Wei Gao
In this paper, we explore a critical yet under-investigated issue: how to learn robust and well-generalized 3D representation from pre-trained vision language models such as CLIP. Previous works have demonstrated that cross-modal distillation can provide rich and useful knowledge for 3D data. However, like most deep learning models, the resultant 3D learning network is still vulnerable to adversarial attacks especially the iterative attack. In this work, we propose Dual Denoising, a novel framework for learning robust and well-generalized 3D representations from CLIP. It combines a denoising-based proxy task with a novel feature denoising network for 3D pre-training. Additionally, we propose utilizing parallel noise inference to enhance the generalization of point cloud features under cross domain settings. Experiments show that our model can effectively improve the representation learning performance and adversarial robustness of the 3D learning network under zero-shot settings without adversarial training. Our code is available at https://github.com/luoshuqing2001/Dual_Denoising.
Read more7/2/2024
0
CLIP3D-AD: Extending CLIP for 3D Few-Shot Anomaly Detection with Multi-View Images Generation
Zuo Zuo, Jiahao Dong, Yao Wu, Yanyun Qu, Zongze Wu
Few-shot anomaly detection methods can effectively address data collecting difficulty in industrial scenarios. Compared to 2D few-shot anomaly detection (2D-FSAD), 3D few-shot anomaly detection (3D-FSAD) is still an unexplored but essential task. In this paper, we propose CLIP3D-AD, an efficient 3D-FSAD method extended on CLIP. We successfully transfer strong generalization ability of CLIP into 3D-FSAD. Specifically, we synthesize anomalous images on given normal images as sample pairs to adapt CLIP for 3D anomaly classification and segmentation. For classification, we introduce an image adapter and a text adapter to fine-tune global visual features and text features. Meanwhile, we propose a coarse-to-fine decoder to fuse and facilitate intermediate multi-layer visual representations of CLIP. To benefit from geometry information of point cloud and eliminate modality and data discrepancy when processed by CLIP, we project and render point cloud to multi-view normal and anomalous images. Then we design multi-view fusion module to fuse features of multi-view images extracted by CLIP which are used to facilitate visual representations for further enhancing vision-language correlation. Extensive experiments demonstrate that our method has a competitive performance of 3D few-shot anomaly classification and segmentation on MVTec-3D AD dataset.
Read more6/28/2024