CLIP-Guided Source-Free Object Detection in Aerial Images

0

Sign in to get full access
Overview
- The paper proposes a method for object detection in aerial images using the CLIP (Contrastive Language-Image Pre-training) model in a source-free domain adaptation setting.
- The approach leverages the powerful language-vision capabilities of CLIP to guide the training of a detection model without requiring labeled data from the target domain.
- The method involves a self-training process where the CLIP model is used to generate pseudo-labels for unlabeled target domain images, which are then used to fine-tune the detection model.
- The proposed technique achieves state-of-the-art performance on several aerial image datasets, demonstrating its effectiveness in adapting to new domains without access to source data.
Plain English Explanation
The paper presents a way to detect objects in aerial images, like those taken from drones or satellites, without needing a lot of labeled training data. This is done by using a powerful AI model called CLIP that can understand the relationship between images and text.
How it works:
- The researchers start with a detection model that has been trained on some aerial images, but this model may not work well on new images from a different location or taken in different conditions.
- Instead of getting more labeled data from the new location, they use CLIP to automatically generate "pseudo-labels" - predictions about what objects are in the new unlabeled images.
- They then use these pseudo-labels to fine-tune the detection model, allowing it to adapt to the new domain without any labeled data from that domain.
Why it's useful:
- This technique, called source-free domain adaptation, can save a lot of time and effort compared to collecting and labeling new data for every new location or scenario.
- The CLIP model acts as a "guide" to help the detection model learn about the new domain, enhancing its zero-shot capabilities and improving anomaly detection.
- This approach can help raise the bar for detecting AI-generated images by leveraging the powerful language-vision understanding of CLIP.
Technical Explanation
The paper proposes a CLIP-guided source-free object detection framework for aerial images. The key components are:
-
Self-training: The method starts with a pre-trained object detection model and uses CLIP to generate pseudo-labels for unlabeled target domain images. These pseudo-labels are then used to fine-tune the detection model, allowing it to adapt to the new domain without access to any labeled target data.
-
CLIP Guidance: The CLIP model is used to extract visual and semantic features from the target images. These features are used to generate high-quality pseudo-labels that capture the relevant object classes and their spatial locations. This CLIP-guided pseudo-labeling is a crucial component that enables effective domain adaptation.
The proposed approach is evaluated on several aerial image datasets, demonstrating state-of-the-art performance in the source-free domain adaptation setting. Compared to previous methods, the CLIP-guided approach shows significant improvements, highlighting the benefits of leveraging powerful language-vision models like CLIP for this task.
Critical Analysis
The paper presents a well-designed and effective approach for source-free object detection in aerial images. The use of CLIP to generate high-quality pseudo-labels is a key innovation that allows the method to adapt to new domains without access to labeled target data.
However, the paper does not fully address the potential limitations of this approach. For example, the performance of the method may be sensitive to the quality and coverage of the CLIP model, which was pre-trained on a limited set of internet images. Applying this technique to significantly different aerial image domains, such as those with very different object classes or imaging characteristics, could be challenging.
Additionally, the paper does not discuss the computational cost or inference speed of the proposed approach, which could be important considerations for real-world deployment, especially in time-sensitive applications like disaster response.
Further research could explore ways to make the method more robust to domain shifts, potentially by incorporating additional techniques like domain-specific fine-tuning of CLIP or using multiple CLIP models as complementary sources of guidance.
Conclusion
The paper presents a novel and effective approach for CLIP-guided source-free object detection in aerial images. By leveraging the powerful language-vision capabilities of CLIP, the method can adapt to new domains without requiring any labeled target data, making it a valuable tool for real-world applications where data collection and annotation can be costly and time-consuming.
The strong empirical results demonstrate the potential of this technique, and the paper opens up interesting research directions in exploring the broader applications of language-vision models like CLIP for domain adaptation and transfer learning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLIP-Guided Source-Free Object Detection in Aerial Images
Nanqing Liu, Xun Xu, Yongyi Su, Chengxin Liu, Peiliang Gong, Heng-Chao Li
Domain adaptation is crucial in aerial imagery, as the visual representation of these images can significantly vary based on factors such as geographic location, time, and weather conditions. Additionally, high-resolution aerial images often require substantial storage space and may not be readily accessible to the public. To address these challenges, we propose a novel Source-Free Object Detection (SFOD) method. Specifically, our approach begins with a self-training framework, which significantly enhances the performance of baseline methods. To alleviate the noisy labels in self-training, we utilize Contrastive Language-Image Pre-training (CLIP) to guide the generation of pseudo-labels, termed CLIP-guided Aggregation (CGA). By leveraging CLIP's zero-shot classification capability, we aggregate its scores with the original predicted bounding boxes, enabling us to obtain refined scores for the pseudo-labels. To validate the effectiveness of our method, we constructed two new datasets from different domains based on the DIOR dataset, named DIOR-C and DIOR-Cloudy. Experimental results demonstrate that our method outperforms other comparative algorithms. The code is available at https://github.com/Lans1ng/SFOD-RS.
Read more5/31/2024
0
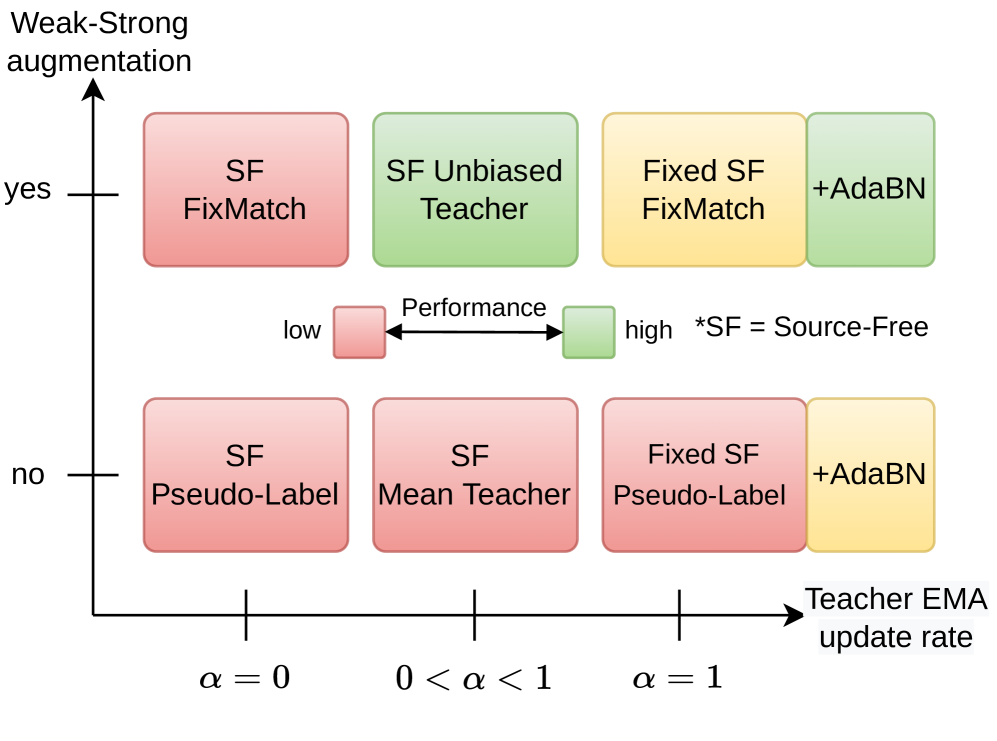
Simplifying Source-Free Domain Adaptation for Object Detection: Effective Self-Training Strategies and Performance Insights
Yan Hao, Florent Forest, Olga Fink
This paper focuses on source-free domain adaptation for object detection in computer vision. This task is challenging and of great practical interest, due to the cost of obtaining annotated data sets for every new domain. Recent research has proposed various solutions for Source-Free Object Detection (SFOD), most being variations of teacher-student architectures with diverse feature alignment, regularization and pseudo-label selection strategies. Our work investigates simpler approaches and their performance compared to more complex SFOD methods in several adaptation scenarios. We highlight the importance of batch normalization layers in the detector backbone, and show that adapting only the batch statistics is a strong baseline for SFOD. We propose a simple extension of a Mean Teacher with strong-weak augmentation in the source-free setting, Source-Free Unbiased Teacher (SF-UT), and show that it actually outperforms most of the previous SFOD methods. Additionally, we showcase that an even simpler strategy consisting in training on a fixed set of pseudo-labels can achieve similar performance to the more complex teacher-student mutual learning, while being computationally efficient and mitigating the major issue of teacher-student collapse. We conduct experiments on several adaptation tasks using benchmark driving datasets including (Foggy)Cityscapes, Sim10k and KITTI, and achieve a notable improvement of 4.7% AP50 on Cityscapes$rightarrow$Foggy-Cityscapes compared with the latest state-of-the-art in SFOD. Source code is available at https://github.com/EPFL-IMOS/simple-SFOD.
Read more7/11/2024
🔎
0
Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Yan Li, Weiwei Guo, Xue Yang, Ning Liao, Dunyun He, Jiaqi Zhou, Wenxian Yu
An increasingly massive number of remote-sensing images spurs the development of extensible object detectors that can detect objects beyond training categories without costly collecting new labeled data. In this paper, we aim to develop open-vocabulary object detection (OVD) technique in aerial images that scales up object vocabulary size beyond training data. The performance of OVD greatly relies on the quality of class-agnostic region proposals and pseudo-labels for novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework following the student-teacher self-learning mechanism employs the RemoteCLIP model as an extra omniscient teacher with rich knowledge. By doing so, our approach boosts not only novel object proposals but also classification. Furthermore, we devise a dynamic label queue strategy to maintain high-quality pseudo labels during batch training. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 46.5% mAP on VisDroneZSD novel categories, which outperforms the state-of-the-art open-vocabulary detectors by 21.0% mAP. To our best knowledge, this is the first work to apply and develop the open-vocabulary object detection technique for aerial images. The code is available at https://github.com/lizzy8587/CastDet.
Read more8/13/2024
🔎
0
Enhancing Source-Free Domain Adaptive Object Detection with Low-confidence Pseudo Label Distillation
Ilhoon Yoon, Hyeongjun Kwon, Jin Kim, Junyoung Park, Hyunsung Jang, Kwanghoon Sohn
Source-Free domain adaptive Object Detection (SFOD) is a promising strategy for deploying trained detectors to new, unlabeled domains without accessing source data, addressing significant concerns around data privacy and efficiency. Most SFOD methods leverage a Mean-Teacher (MT) self-training paradigm relying heavily on High-confidence Pseudo Labels (HPL). However, these HPL often overlook small instances that undergo significant appearance changes with domain shifts. Additionally, HPL ignore instances with low confidence due to the scarcity of training samples, resulting in biased adaptation toward familiar instances from the source domain. To address this limitation, we introduce the Low-confidence Pseudo Label Distillation (LPLD) loss within the Mean-Teacher based SFOD framework. This novel approach is designed to leverage the proposals from Region Proposal Network (RPN), which potentially encompasses hard-to-detect objects in unfamiliar domains. Initially, we extract HPL using a standard pseudo-labeling technique and mine a set of Low-confidence Pseudo Labels (LPL) from proposals generated by RPN, leaving those that do not overlap significantly with HPL. These LPL are further refined by leveraging class-relation information and reducing the effect of inherent noise for the LPLD loss calculation. Furthermore, we use feature distance to adaptively weight the LPLD loss to focus on LPL containing a larger foreground area. Our method outperforms previous SFOD methods on four cross-domain object detection benchmarks. Extensive experiments demonstrate that our LPLD loss leads to effective adaptation by reducing false negatives and facilitating the use of domain-invariant knowledge from the source model. Code is available at https://github.com/junia3/LPLD.
Read more7/19/2024