Updating CLIP to Prefer Descriptions Over Captions
2406.09458
0
0

Abstract
Although CLIPScore is a powerful generic metric that captures the similarity between a text and an image, it fails to distinguish between a caption that is meant to complement the information in an image and a description that is meant to replace an image entirely, e.g., for accessibility. We address this shortcoming by updating the CLIP model with the Concadia dataset to assign higher scores to descriptions than captions using parameter efficient fine-tuning and a loss objective derived from work on causal interpretability. This model correlates with the judgements of blind and low-vision people while preserving transfer capabilities and has interpretable structure that sheds light on the caption--description distinction.
Create account to get full access
Overview
- This paper proposes a method to update the CLIP (Contrastive Language-Image Pre-training) model to prefer image descriptions over captions.
- CLIP is a popular pre-trained model that learns visual and language representations jointly, enabling tasks like image captioning and visual question answering.
- The authors argue that CLIP's preference for image captions over more detailed descriptions can limit its performance on certain tasks.
- Their proposed method aims to shift CLIP's preference towards more informative image descriptions while maintaining its strong performance on other vision-language tasks.
Plain English Explanation
The paper discusses updating the CLIP model, which is a popular AI system that can understand both images and text. CLIP is trained to match images with their corresponding captions or descriptions. However, the authors found that CLIP often prefers shorter image captions over more detailed descriptions.
This preference for captions over descriptions can be a problem for certain applications, like image accessibility or image search, where more detailed information about an image is valuable.
To address this, the researchers developed a way to update CLIP so that it prefers informative image descriptions over basic captions. This involves modifying how CLIP is trained to better reward descriptions that provide richer information about the image.
The goal is to maintain CLIP's strong performance on tasks like caption generation and visual question answering, while also making it better at understanding and utilizing detailed image descriptions.
Technical Explanation
The paper proposes an approach to update the CLIP (Contrastive Language-Image Pre-training) model to prefer image descriptions over captions. CLIP is a pre-trained vision-language model that learns joint representations of images and text, enabling tasks like image captioning and visual question answering.
The authors observe that CLIP often prioritizes shorter image captions over more informative descriptions, which can limit its performance on certain applications that require detailed understanding of image content. To address this, they introduce a modified training objective that encourages CLIP to better match images with their corresponding descriptions.
Specifically, the authors leverage a contrastive loss function that not only pulls an image and its ground-truth caption/description closer together, but also pushes the image away from negatively sampled captions/descriptions. Crucially, they sample the negative examples such that descriptions are favored over captions during training.
The authors evaluate their approach on several vision-language benchmarks, including image-text retrieval, visual question answering, and image captioning. They demonstrate that their updated CLIP model maintains strong performance on these tasks while exhibiting a clear preference for detailed image descriptions over shorter captions.
Critical Analysis
The paper presents a thoughtful approach to improving the CLIP model's ability to leverage rich image descriptions, which can be valuable for applications like image accessibility and image search. The authors provide a clear motivation for their work and a well-designed experimental setup to evaluate the updated CLIP model's performance.
One potential limitation is that the paper does not explore the impact of this approach on the model's ability to generate high-quality captions, which is an important capability of CLIP. While the authors show that the updated model maintains strong performance on caption-related tasks, it would be valuable to understand if there are any trade-offs in caption generation quality.
Additionally, the paper does not delve into the specific mechanisms by which the updated training objective encourages a preference for descriptions over captions. A more detailed analysis of the learned representations and their differences compared to the original CLIP model could provide additional insights.
Overall, this paper makes a valuable contribution by addressing an important limitation of CLIP and proposing a solution that can broaden the model's applicability. Further research exploring the implications of this approach and potential extensions would be a welcome addition to the field.
Conclusion
This paper presents a method to update the CLIP (Contrastive Language-Image Pre-training) model to prefer detailed image descriptions over shorter captions. The authors argue that CLIP's natural tendency to prioritize captions can limit its performance on tasks that require a deeper understanding of image content, such as image accessibility and image search.
By modifying CLIP's training objective to better reward the matching of images with their corresponding descriptions, the authors demonstrate that the updated model can maintain strong performance on a range of vision-language tasks while exhibiting a clear preference for detailed image descriptions. This work has the potential to enhance the capabilities of CLIP and similar vision-language models, enabling them to better serve applications that require a more comprehensive understanding of visual content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CLIP with Quality Captions: A Strong Pretraining for Vision Tasks
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Oncel Tuzel
0
0
CLIP models perform remarkably well on zero-shot classification and retrieval tasks. But recent studies have shown that learnt representations in CLIP are not well suited for dense prediction tasks like object detection, semantic segmentation or depth estimation. More recently, multi-stage training methods for CLIP models was introduced to mitigate the weak performance of CLIP on downstream tasks. In this work, we find that simply improving the quality of captions in image-text datasets improves the quality of CLIP's visual representations, resulting in significant improvement on downstream dense prediction vision tasks. In fact, we find that CLIP pretraining with good quality captions can surpass recent supervised, self-supervised and weakly supervised pretraining methods. We show that when CLIP model with ViT-B/16 as image encoder is trained on well aligned image-text pairs it obtains 12.1% higher mIoU and 11.5% lower RMSE on semantic segmentation and depth estimation tasks over recent state-of-the-art Masked Image Modeling (MIM) pretraining methods like Masked Autoencoder (MAE). We find that mobile architectures also benefit significantly from CLIP pretraining. A recent mobile vision architecture, MCi2, with CLIP pretraining obtains similar performance as Swin-L, pretrained on ImageNet-22k for semantic segmentation task while being 6.1$times$ smaller. Moreover, we show that improving caption quality results in $10times$ data efficiency when finetuning for dense prediction tasks.
5/16/2024

Jina CLIP: Your CLIP Model Is Also Your Text Retriever
Andreas Koukounas, Georgios Mastrapas, Michael Gunther, Bo Wang, Scott Martens, Isabelle Mohr, Saba Sturua, Mohammad Kalim Akram, Joan Fontanals Mart'inez, Saahil Ognawala, Susana Guzman, Maximilian Werk, Nan Wang, Han Xiao
0
0
Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common embedding space by mapping them to fixed-sized vectors. These models are key to multimodal information retrieval and related tasks. However, CLIP models generally underperform in text-only tasks compared to specialized text models. This creates inefficiencies for information retrieval systems that keep separate embeddings and models for text-only and multimodal tasks. We propose a novel, multi-task contrastive training method to address this issue, which we use to train the jina-clip-v1 model to achieve the state-of-the-art performance on both text-image and text-text retrieval tasks.
6/27/2024

A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions
Jack Urbanek, Florian Bordes, Pietro Astolfi, Mary Williamson, Vasu Sharma, Adriana Romero-Soriano
0
0
Curation methods for massive vision-language datasets trade off between dataset size and quality. However, even the highest quality of available curated captions are far too short to capture the rich visual detail in an image. To show the value of dense and highly-aligned image-text pairs, we collect the Densely Captioned Images (DCI) dataset, containing 7805 natural images human-annotated with mask-aligned descriptions averaging above 1000 words each. With precise and reliable captions associated with specific parts of an image, we can evaluate vision-language models' (VLMs) understanding of image content with a novel task that matches each caption with its corresponding subcrop. As current models are often limited to 77 text tokens, we also introduce a summarized version (sDCI) in which each caption length is limited. We show that modern techniques that make progress on standard benchmarks do not correspond with significant improvement on our sDCI based benchmark. Lastly, we finetune CLIP using sDCI and show significant improvements over the baseline despite a small training set. By releasing the first human annotated dense image captioning dataset, we hope to enable the development of new benchmarks or fine-tuning recipes for the next generation of VLMs to come.
6/18/2024
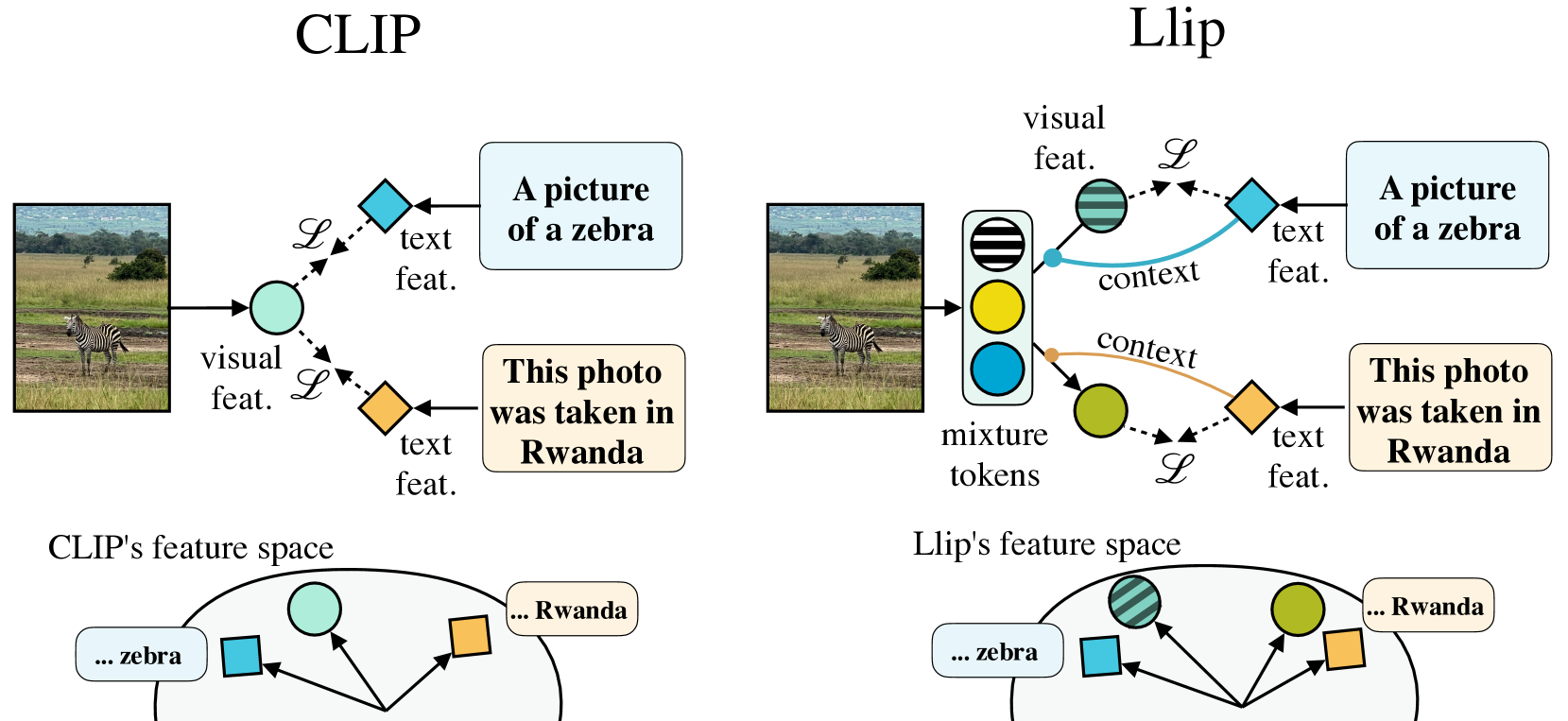
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024