A Closer Look at the Limitations of Instruction Tuning
2402.05119
0
0
Abstract
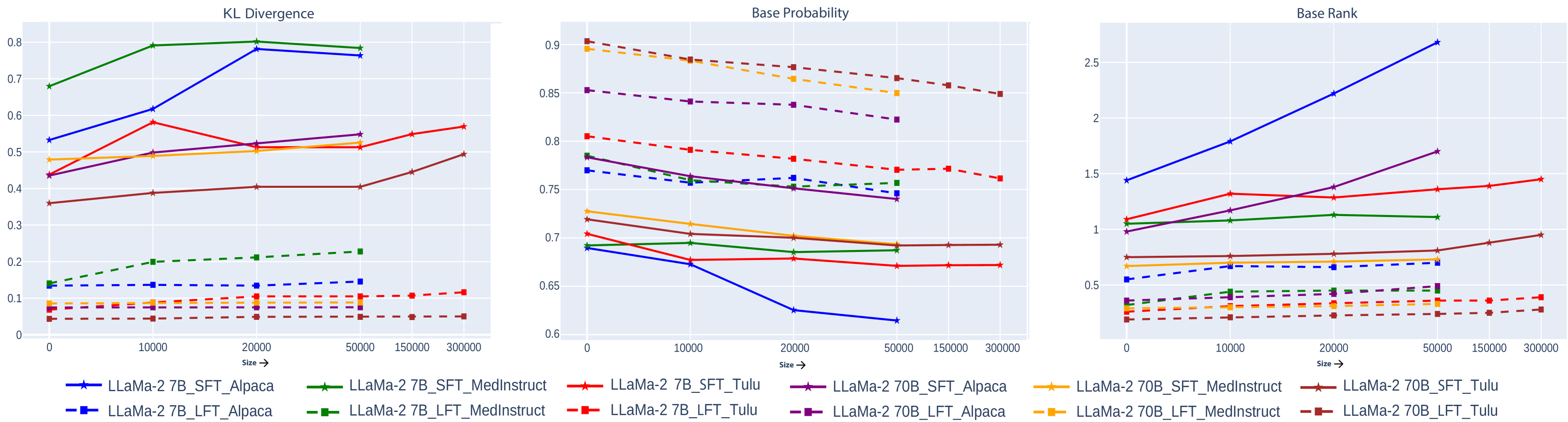
Instruction Tuning (IT), the process of training large language models (LLMs) using instruction-response pairs, has emerged as the predominant method for transforming base pre-trained LLMs into open-domain conversational agents. While IT has achieved notable success and widespread adoption, its limitations and shortcomings remain underexplored. In this paper, through rigorous experiments and an in-depth analysis of the changes LLMs undergo through IT, we reveal various limitations of IT. In particular, we show that (1) IT fails to enhance knowledge or skills in LLMs. LoRA fine-tuning is limited to learning response initiation and style tokens, and full-parameter fine-tuning leads to knowledge degradation. (2) Copying response patterns from IT datasets derived from knowledgeable sources leads to a decline in response quality. (3) Full-parameter fine-tuning increases hallucination by inaccurately borrowing tokens from conceptually similar instances in the IT dataset for generating responses. (4) Popular methods to improve IT do not lead to performance improvements over a simple LoRA fine-tuned model. Our findings reveal that responses generated solely from pre-trained knowledge consistently outperform responses by models that learn any form of new knowledge from IT on open-source datasets. We hope the insights and challenges revealed in this paper inspire future work in related directions.
Create account to get full access
Overview
- The paper examines the limitations of instruction tuning, a technique used to train large language models to follow instructions and complete tasks.
- It explores how instruction tuning affects the models' underlying knowledge and capabilities, beyond just their performance on instruction-following tasks.
- The research provides insights into the strengths and weaknesses of this approach, which has become increasingly popular in the field of artificial intelligence.
Plain English Explanation
Instruction tuning is a way of training large language models, like GPT-3, to follow specific instructions and complete tasks. This paper takes a closer look at the limitations of this technique. It investigates how instruction tuning affects the models' fundamental knowledge and capabilities, rather than just their ability to follow instructions.
The researchers found that while instruction tuning can improve a model's performance on instruction-following tasks, it doesn't necessarily enhance the model's underlying knowledge or understanding. In other words, a model trained this way may be good at following instructions, but it may not have a deeper grasp of the concepts involved or the ability to apply that knowledge in more general ways.
The paper provides insights into the trade-offs and potential pitfalls of relying too heavily on instruction tuning. It suggests that while this approach can be useful in certain contexts, it may not be the best way to develop models with robust, general-purpose knowledge and capabilities.
Technical Explanation
The paper presents a series of experiments that examine the impact of instruction tuning on the underlying knowledge and capabilities of large language models. The researchers used a pre-trained language model as a starting point and then fine-tuned it on a set of instructions, following a similar approach to instruction tuning loss over instructions.
They then evaluated the model's performance on a range of tasks, including both instruction-following and knowledge-based assessments. The results suggest that while instruction tuning can lead to improved performance on the specific tasks the model was trained on, it does not necessarily translate to a deeper understanding or broader knowledge.
For example, the authors found that instruction-tuned models performed well on tasks like answering questions based on given instructions, but struggled with more open-ended tasks that required drawing inferences or applying knowledge in novel ways. This raises questions about the limitations of instruction-tuned language models' ability to capture and utilize knowledge.
The paper also explores the potential reasons for these limitations, such as the tendency of instruction tuning to focus the model's attention on specific task details rather than broader conceptual understanding. The authors suggest that a more balanced approach, combining instruction tuning with other techniques, may be necessary to develop models with truly robust and flexible capabilities.
Critical Analysis
The paper raises important questions about the limitations of instruction tuning and the need to consider the broader implications of this approach. While the authors acknowledge the potential benefits of instruction tuning, such as improved performance on task-specific objectives, they highlight the potential drawbacks in terms of the model's underlying knowledge and generalization abilities.
One key limitation of the research is that it focuses on a specific set of tasks and models, and the findings may not necessarily generalize to all instruction-tuned language models or applications. Additionally, the paper does not delve into the potential reasons why instruction tuning may have these limitations, and further research would be needed to fully understand the underlying mechanisms.
That said, the authors raise valid concerns about the potential pitfalls of over-relying on instruction tuning as a primary training approach. They suggest that a more balanced approach, combining instruction tuning with other techniques like zero-shot cross-lingual transfer, may be necessary to develop models with truly robust and flexible capabilities.
Overall, this paper provides a valuable contribution to the ongoing discussion around the strengths and limitations of instruction-based training approaches in the field of artificial intelligence. It encourages readers to think critically about the trade-offs and potential risks associated with this technique, and to consider the broader implications for the development of capable and versatile AI systems.
Conclusion
This paper offers a critical examination of the limitations of instruction tuning, a popular technique for training large language models to follow instructions and complete tasks. The researchers found that while instruction tuning can lead to improved performance on specific instruction-following tasks, it does not necessarily enhance the model's underlying knowledge or broader capabilities.
The findings suggest that a more balanced approach, combining instruction tuning with other techniques, may be necessary to develop AI systems with truly robust and flexible capabilities. The paper encourages the research community to think critically about the trade-offs and potential pitfalls of over-relying on instruction-based training, and to consider the broader implications for the development of capable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024

Contrastive Instruction Tuning
Tianyi Lorena Yan, Fei Wang, James Y. Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, Muhao Chen
0
0
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
6/7/2024
✅
Instruction Tuning With Loss Over Instructions
Zhengyan Shi, Adam X. Yang, Bin Wu, Laurence Aitchison, Emine Yilmaz, Aldo Lipani
0
0
Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (e.g., MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (e.g., MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that the improvement can be attributed to reduced overfitting to instruction tuning datasets. Our work provides practical guidance for instruction tuning LMs, especially in low-resource scenarios.
5/24/2024
Instruction-tuned Language Models are Better Knowledge Learners
Zhengbao Jiang, Zhiqing Sun, Weijia Shi, Pedro Rodriguez, Chunting Zhou, Graham Neubig, Xi Victoria Lin, Wen-tau Yih, Srinivasan Iyer
0
0
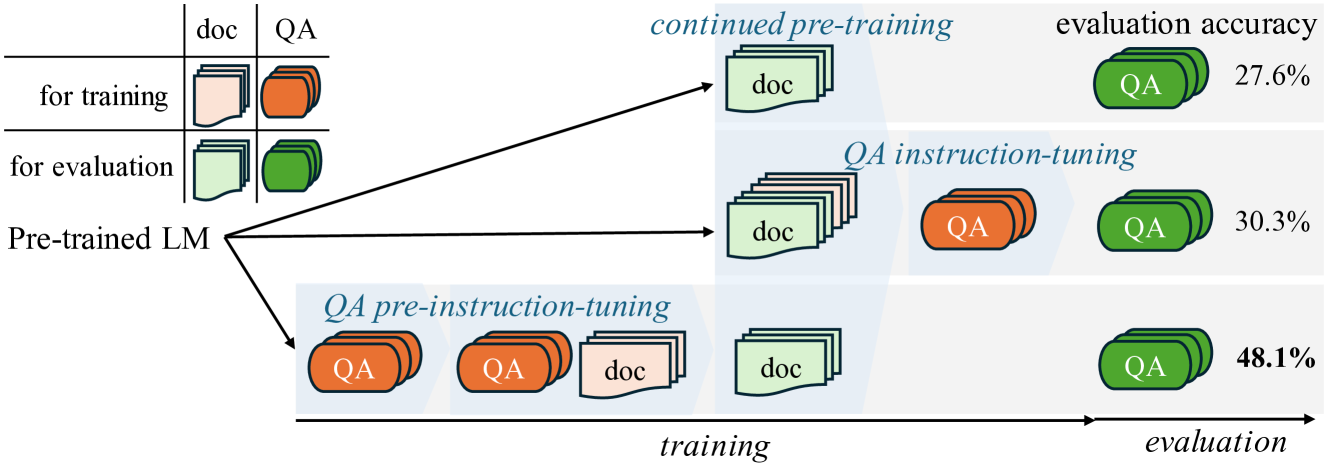
In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that pre-instruction-tuning significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
5/28/2024