Clover-2: Accurate Inference for Regressive Lightweight Speculative Decoding

0
Sign in to get full access
Overview
- The paper discusses formatting instructions for NeurIPS 2023 conference submissions.
- It covers important details like paper length, formatting, and submission requirements.
- The instructions aim to ensure a consistent and professional appearance for all NeurIPS papers.
Plain English Explanation
The paper provides guidance on how to properly format and submit papers for the NeurIPS 2023 conference. NeurIPS is a prestigious machine learning conference, and having a consistent format across all submissions helps create a professional and polished final program.
The instructions cover key details like:
- Paper length - Papers must be no more than 9 pages, with an optional 1 page for references.
- Formatting - Using specific font sizes, margins, and layouts to ensure a clean, readable appearance.
- Submission process - How to properly submit papers and any required supplementary material.
Following these guidelines helps authors create NeurIPS submissions that are easy for reviewers to read and assess. It also ensures a consistent look and feel across all accepted papers in the final conference proceedings.
Technical Explanation
The paper outlines the formatting instructions for submitting papers to the NeurIPS 2023 conference. It covers several key aspects:
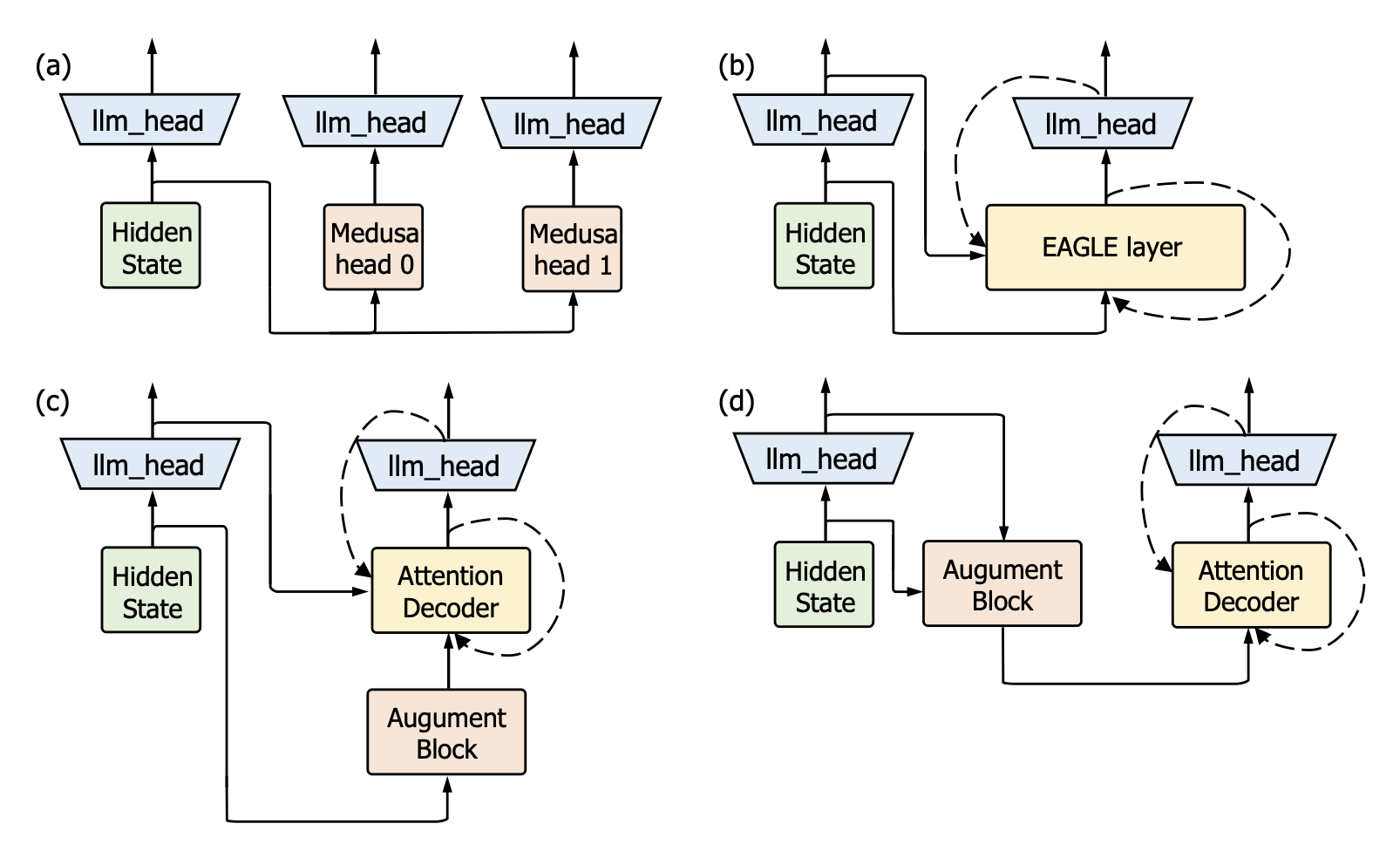
Speculative Decoding and Tree Attention: The paper discusses the use of speculative decoding, which involves generating multiple possible continuations of a sequence in parallel, and tree attention, which captures long-range dependencies in language models.
Formatting Requirements: The instructions detail the specific formatting requirements for NeurIPS papers, including page limits, font sizes, margins, and layout. For example, papers must be no more than 9 pages long, with an optional 1 page for references.
Submission Process: The paper also explains the submission process, including how to properly submit papers and any required supplementary material through the conference website.
Critical Analysis
The formatting instructions provided in the paper are comprehensive and well-documented, ensuring a consistent appearance for all NeurIPS 2023 submissions. However, the paper does not address potential challenges or limitations that authors may face when following these guidelines.
For example, the strict page limits may pose difficulties for authors trying to thoroughly describe their research within the allotted space. Additionally, the formatting requirements, while necessary for consistency, could inadvertently disadvantage authors who are less familiar with typesetting or document preparation.
It would be helpful if the paper also discussed ways for authors to overcome these potential hurdles, such as providing tips for concise writing or guidance on using document preparation tools effectively.
Conclusion
The formatting instructions for the NeurIPS 2023 conference are an important resource for authors, ensuring a professional and consistent appearance for all accepted papers. By following these guidelines, authors can focus on effectively communicating their research without getting bogged down in formatting details.
While the instructions are comprehensive, there may be opportunities to further support authors in navigating the submission process and meeting the strict formatting requirements. Overall, these guidelines help maintain the high standards and presentation quality of the NeurIPS conference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Clover-2: Accurate Inference for Regressive Lightweight Speculative Decoding
Bin Xiao, Lujun Gui, Lei Su, Weipeng Chen
Large Language Models (LLMs) frequently suffer from inefficiencies, largely attributable to the discord between the requirements of auto-regressive decoding and the architecture of contemporary GPUs. Recently, regressive lightweight speculative decoding has garnered attention for its notable efficiency improvements in text generation tasks. This approach utilizes a lightweight regressive draft model, like a Recurrent Neural Network (RNN) or a single transformer decoder layer, leveraging sequential information to iteratively predict potential tokens. Specifically, RNN draft models are computationally economical but tend to deliver lower accuracy, while attention decoder layer models exhibit the opposite traits. This paper presents Clover-2, an advanced iteration of Clover, an RNN-based draft model designed to achieve comparable accuracy to that of attention decoder layer models while maintaining minimal computational overhead. Clover-2 enhances the model architecture and incorporates knowledge distillation to increase Clover's accuracy and improve overall efficiency. We conducted experiments using the open-source Vicuna 7B and LLaMA3-Instruct 8B models. The results demonstrate that Clover-2 surpasses existing methods across various model architectures, showcasing its efficacy and robustness.
Read more8/2/2024
📶
0
Clover: Regressive Lightweight Speculative Decoding with Sequential Knowledge
Bin Xiao, Chunan Shi, Xiaonan Nie, Fan Yang, Xiangwei Deng, Lei Su, Weipeng Chen, Bin Cui
Large language models (LLMs) suffer from low efficiency as the mismatch between the requirement of auto-regressive decoding and the design of most contemporary GPUs. Specifically, billions to trillions of parameters must be loaded to the GPU cache through its limited memory bandwidth for computation, but only a small batch of tokens is actually computed. Consequently, the GPU spends most of its time on memory transfer instead of computation. Recently, parallel decoding, a type of speculative decoding algorithms, is becoming more popular and has demonstrated impressive efficiency improvement in generation. It introduces extra decoding heads to large models, enabling them to predict multiple subsequent tokens simultaneously and verify these candidate continuations in a single decoding step. However, this approach deviates from the training objective of next token prediction used during pre-training, resulting in a low hit rate for candidate tokens. In this paper, we propose a new speculative decoding algorithm, Clover, which integrates sequential knowledge into the parallel decoding process. This enhancement improves the hit rate of speculators and thus boosts the overall efficiency. Clover transmits the sequential knowledge from pre-speculated tokens via the Regressive Connection, then employs an Attention Decoder to integrate these speculated tokens. Additionally, Clover incorporates an Augmenting Block that modifies the hidden states to better align with the purpose of speculative generation rather than next token prediction. The experiment results demonstrate that Clover outperforms the baseline by up to 91% on Baichuan-Small and 146% on Baichuan-Large, respectively, and exceeds the performance of the previously top-performing method, Medusa, by up to 37% on Baichuan-Small and 57% on Baichuan-Large, respectively.
Read more5/2/2024
0
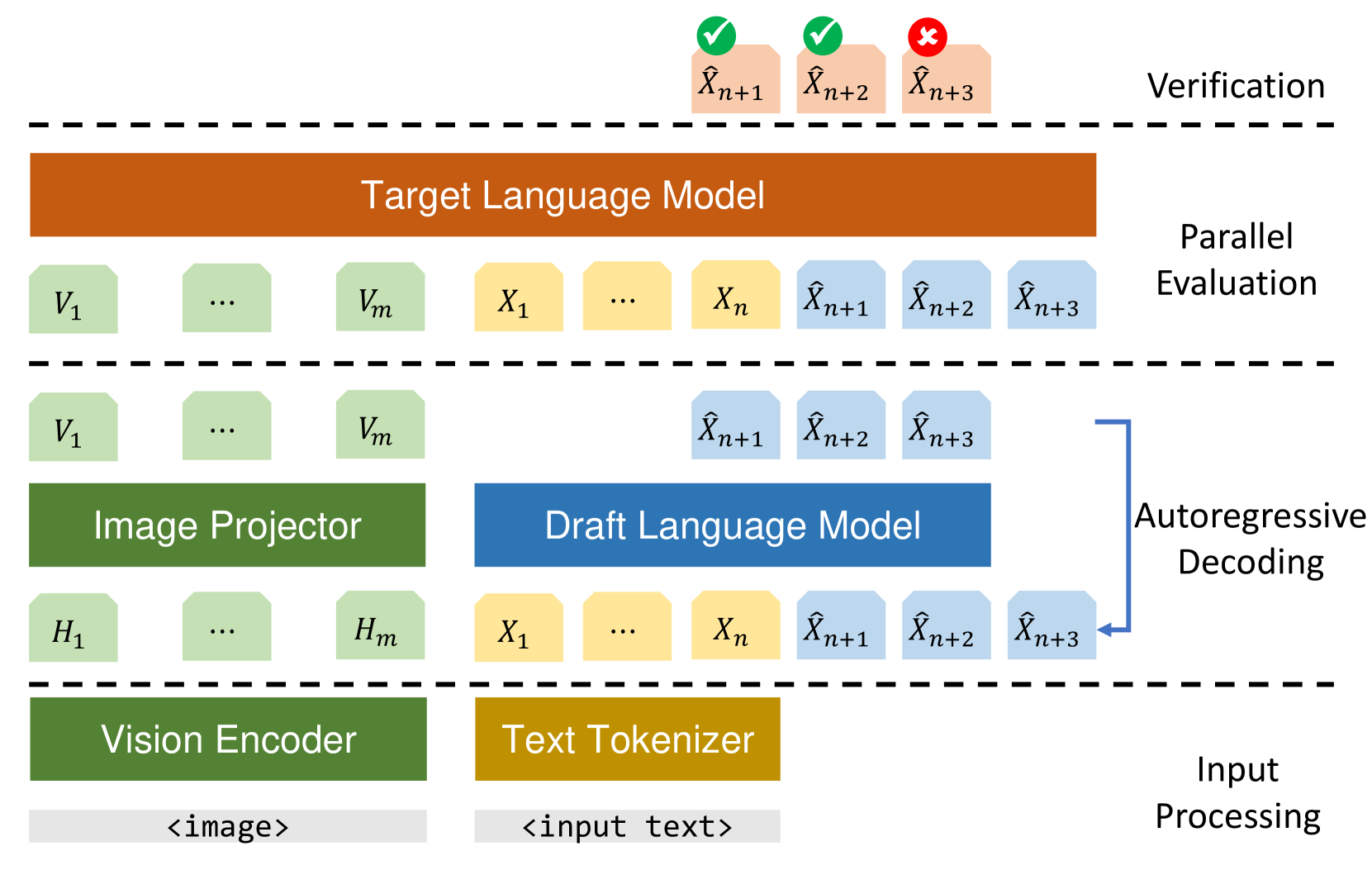
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Read more4/16/2024

0
Recurrent Drafter for Fast Speculative Decoding in Large Language Models
Aonan Zhang, Chong Wang, Yi Wang, Xuanyu Zhang, Yunfei Cheng
In this paper, we introduce an improved approach of speculative decoding aimed at enhancing the efficiency of serving large language models. Our method capitalizes on the strengths of two established techniques: the classic two-model speculative decoding approach, and the more recent single-model approach, Medusa. Drawing inspiration from Medusa, our approach adopts a single-model strategy for speculative decoding. However, our method distinguishes itself by employing a single, lightweight draft head with a recurrent dependency design, akin in essence to the small, draft model uses in classic speculative decoding, but without the complexities of the full transformer architecture. And because of the recurrent dependency, we can use beam search to swiftly filter out undesired candidates with the draft head. The outcome is a method that combines the simplicity of single-model design and avoids the need to create a data-dependent tree attention structure only for inference in Medusa. We empirically demonstrate the effectiveness of the proposed method on several popular open source language models, along with a comprehensive analysis of the trade-offs involved in adopting this approach.
Read more5/31/2024