Clover: Regressive Lightweight Speculative Decoding with Sequential Knowledge

0
📶
Sign in to get full access
Overview
- Large language models (LLMs) suffer from low efficiency due to the mismatch between the requirements of auto-regressive decoding and the design of most contemporary GPUs
- Parallel decoding, a type of speculative decoding algorithm, has demonstrated impressive efficiency improvements in generation
- However, this approach deviates from the training objective of next token prediction, resulting in a low hit rate for candidate tokens
- This paper proposes a new speculative decoding algorithm, Clover, which integrates sequential knowledge into the parallel decoding process to improve the hit rate of speculators and boost overall efficiency
Plain English Explanation
Large language models, which are powerful AI systems that can generate human-like text, often struggle with efficiency. This is because the way they generate text, known as auto-regressive decoding, doesn't match well with the design of most modern graphics processing units (GPUs) used to run these models.
Specifically, these models have billions or even trillions of parameters that need to be loaded into the GPU's limited memory for computation. However, during the decoding process, only a small batch of tokens (the basic units of text) is actually computed at a time. As a result, the GPU spends most of its time transferring data rather than doing actual computations.
To address this issue, researchers have been exploring a technique called parallel decoding, which involves using multiple "decoding heads" to predict multiple subsequent tokens simultaneously. This can improve efficiency by verifying these candidate tokens in a single decoding step.
However, this approach has a drawback: it deviates from the original training objective of the model, which is to predict the next token in a sequence. This means that the model is less likely to accurately predict the correct next token, leading to a low "hit rate" for the speculated tokens.
In this paper, the researchers propose a new algorithm called Clover, which aims to address this issue by integrating the sequential knowledge from the pre-speculated tokens into the parallel decoding process. This helps to improve the hit rate of the speculators, leading to a more efficient overall decoding process.
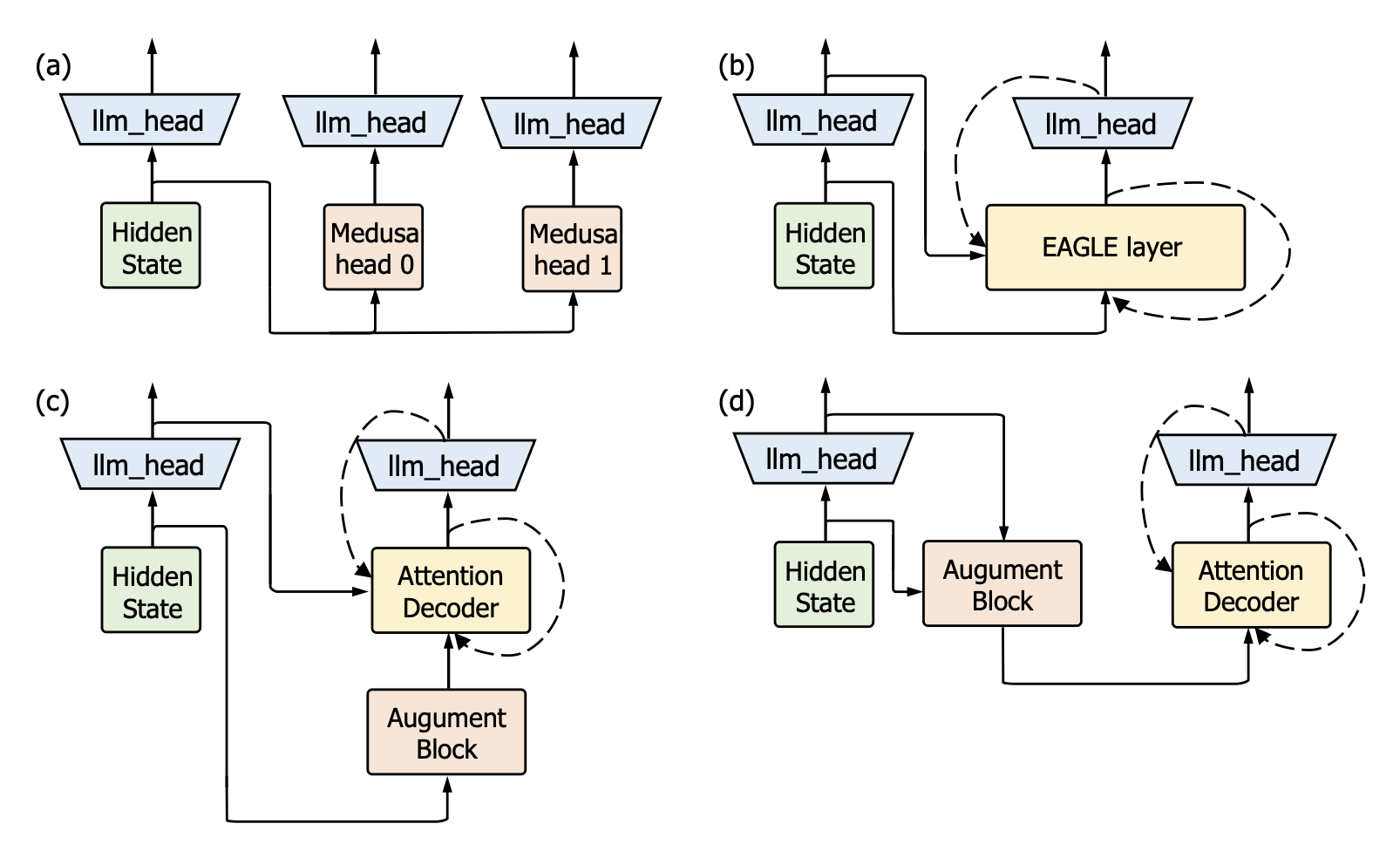
Clover does this by using a "Regressive Connection" to transmit the sequential knowledge from the pre-speculated tokens, and an "Attention Decoder" to integrate these tokens. Additionally, Clover incorporates an "Augmenting Block" that modifies the hidden states of the model to better align with the purpose of speculative generation rather than just next token prediction.
The researchers' experiments show that Clover outperforms both the baseline method and the previously top-performing Medusa method, with efficiency improvements of up to 91% on a smaller dataset and 146% on a larger one.
Technical Explanation
The paper proposes a new speculative decoding algorithm called Clover, which aims to improve the efficiency of large language models by better integrating the sequential knowledge from pre-speculated tokens into the parallel decoding process.
The key elements of Clover's architecture include:
-
Regressive Connection: This component transmits the sequential knowledge from the pre-speculated tokens to the parallel decoding process, helping to improve the hit rate of the speculated tokens.
-
Attention Decoder: This module integrates the speculated tokens, using attention mechanisms to combine the information from the pre-speculated tokens with the current decoding state.
-
Augmenting Block: This block modifies the hidden states of the model to better align with the purpose of speculative generation, rather than just next token prediction.
The researchers evaluate Clover's performance on two benchmarks, Baichuan-Small and Baichuan-Large, comparing it to both a baseline method and the previously top-performing Medusa approach. Their results show that Clover outperforms both, with efficiency improvements of up to 91% on Baichuan-Small and 146% on Baichuan-Large, as well as exceeding Medusa's performance by up to 37% on Baichuan-Small and 57% on Baichuan-Large.
Critical Analysis
The paper presents a novel and promising approach to improving the efficiency of large language models through the use of a speculative decoding algorithm. The key strengths of the Clover algorithm are its ability to better integrate sequential knowledge from pre-speculated tokens, which helps to improve the hit rate of the speculated tokens and overall decoding efficiency.
However, the paper does not explore some potential limitations or areas for further research. For example, the impact of the Clover algorithm on the overall quality and coherence of the generated text is not thoroughly assessed. Additionally, the paper does not discuss how Clover might perform on a wider range of language modeling tasks beyond the specific benchmarks used in the experiments.
It would also be interesting to see how Clover compares to other speculative decoding approaches or combined tokenization and speculative techniques that have been proposed in the literature. A more comprehensive comparison to the state-of-the-art in this area would help to further contextualize the contributions of the Clover algorithm.
Overall, the Clover algorithm represents an exciting advance in the field of large language model efficiency, and the paper provides a solid technical foundation for this approach. However, further research is needed to fully understand its strengths, limitations, and potential applications in real-world scenarios.
Conclusion
This paper introduces Clover, a new speculative decoding algorithm for large language models that aims to improve efficiency by better integrating sequential knowledge from pre-speculated tokens. Clover's key innovations, including the Regressive Connection, Attention Decoder, and Augmenting Block, demonstrate significant performance improvements over both baseline and state-of-the-art methods.
The findings in this paper suggest that incorporating sequential knowledge into parallel decoding processes can be a promising avenue for enhancing the efficiency of large language models, which is crucial as these models continue to grow in scale and complexity. By addressing the mismatch between auto-regressive decoding and GPU architecture, Clover represents an important step forward in making these powerful AI systems more practical and accessible for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Clover: Regressive Lightweight Speculative Decoding with Sequential Knowledge
Bin Xiao, Chunan Shi, Xiaonan Nie, Fan Yang, Xiangwei Deng, Lei Su, Weipeng Chen, Bin Cui
Large language models (LLMs) suffer from low efficiency as the mismatch between the requirement of auto-regressive decoding and the design of most contemporary GPUs. Specifically, billions to trillions of parameters must be loaded to the GPU cache through its limited memory bandwidth for computation, but only a small batch of tokens is actually computed. Consequently, the GPU spends most of its time on memory transfer instead of computation. Recently, parallel decoding, a type of speculative decoding algorithms, is becoming more popular and has demonstrated impressive efficiency improvement in generation. It introduces extra decoding heads to large models, enabling them to predict multiple subsequent tokens simultaneously and verify these candidate continuations in a single decoding step. However, this approach deviates from the training objective of next token prediction used during pre-training, resulting in a low hit rate for candidate tokens. In this paper, we propose a new speculative decoding algorithm, Clover, which integrates sequential knowledge into the parallel decoding process. This enhancement improves the hit rate of speculators and thus boosts the overall efficiency. Clover transmits the sequential knowledge from pre-speculated tokens via the Regressive Connection, then employs an Attention Decoder to integrate these speculated tokens. Additionally, Clover incorporates an Augmenting Block that modifies the hidden states to better align with the purpose of speculative generation rather than next token prediction. The experiment results demonstrate that Clover outperforms the baseline by up to 91% on Baichuan-Small and 146% on Baichuan-Large, respectively, and exceeds the performance of the previously top-performing method, Medusa, by up to 37% on Baichuan-Small and 57% on Baichuan-Large, respectively.
Read more5/2/2024
0
Clover-2: Accurate Inference for Regressive Lightweight Speculative Decoding
Bin Xiao, Lujun Gui, Lei Su, Weipeng Chen
Large Language Models (LLMs) frequently suffer from inefficiencies, largely attributable to the discord between the requirements of auto-regressive decoding and the architecture of contemporary GPUs. Recently, regressive lightweight speculative decoding has garnered attention for its notable efficiency improvements in text generation tasks. This approach utilizes a lightweight regressive draft model, like a Recurrent Neural Network (RNN) or a single transformer decoder layer, leveraging sequential information to iteratively predict potential tokens. Specifically, RNN draft models are computationally economical but tend to deliver lower accuracy, while attention decoder layer models exhibit the opposite traits. This paper presents Clover-2, an advanced iteration of Clover, an RNN-based draft model designed to achieve comparable accuracy to that of attention decoder layer models while maintaining minimal computational overhead. Clover-2 enhances the model architecture and incorporates knowledge distillation to increase Clover's accuracy and improve overall efficiency. We conducted experiments using the open-source Vicuna 7B and LLaMA3-Instruct 8B models. The results demonstrate that Clover-2 surpasses existing methods across various model architectures, showcasing its efficacy and robustness.
Read more8/2/2024
0
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Read more4/16/2024

0
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
Jacob K Christopher, Brian R Bartoldson, Bhavya Kailkhura, Ferdinando Fioretto
Speculative decoding has emerged as a widely adopted method to accelerate large language model inference without sacrificing the quality of the model outputs. While this technique has facilitated notable speed improvements by enabling parallel sequence verification, its efficiency remains inherently limited by the reliance on incremental token generation in existing draft models. To overcome this limitation, this paper proposes an adaptation of speculative decoding which uses discrete diffusion models to generate draft sequences. This allows parallelization of both the drafting and verification steps, providing significant speed-ups to the inference process. Our proposed approach, Speculative Diffusion Decoding (SpecDiff), is validated on standard language generation benchmarks and empirically demonstrated to provide a up to 8.7x speed-up over standard generation processes and up to 2.5x speed-up over existing speculative decoding approaches.
Read more8/20/2024