Recurrent Drafter for Fast Speculative Decoding in Large Language Models

0

Sign in to get full access
Overview
- This paper introduces the Recurrent Drafter, a novel technique for fast speculative decoding in large language models.
- The Recurrent Drafter generates draft outputs in parallel with the main model, allowing for faster generation of final outputs.
- The paper evaluates the Recurrent Drafter on various language tasks, demonstrating significant speedups compared to traditional decoding approaches.
Plain English Explanation
The Recurrent Drafter for Fast Speculative Decoding in Large Language Models paper presents a new way to make large language models, like GPT-3 or BERT, generate text more quickly. Large language models are powerful but can be slow to produce outputs, especially for tasks like answering questions or generating stories.
The key idea of the Recurrent Drafter is to have the model create "draft" outputs in parallel with the main output. This allows the model to quickly generate multiple potential outputs, which can then be refined and selected from to produce the final output. This is like a human writer quickly jotting down several ideas before choosing the best one to develop further.
The paper shows that this Recurrent Drafter approach can significantly speed up the text generation process, without sacrificing the quality of the final outputs. This could be very useful for applications that require fast, high-quality language generation, such as conversational assistants, creative writing tools, or real-time translation.
Technical Explanation
The Recurrent Drafter for Fast Speculative Decoding in Large Language Models paper introduces a novel technique called the Recurrent Drafter to enable faster speculative decoding in large language models.
The key idea is to have the language model generate multiple draft outputs in parallel with the main output. This is achieved by introducing a recurrent "drafting" module that runs concurrently with the main language model. The drafting module takes the current input and hidden state of the language model and generates a draft output, which is then used to guide and accelerate the final output generation.
The authors evaluate the Recurrent Drafter on a variety of language tasks, including text generation, question answering, and summarization. They show that the Recurrent Drafter can provide significant speedups (up to 2.5x) compared to traditional decoding approaches, while maintaining the quality of the final outputs.
The paper also discusses the connection between the Recurrent Drafter and other speculative decoding techniques, such as Speculative Decoding for Multimodal Large Language Models, Direct Alignment Draft Model for Speculative Decoding in Chat, Draft-Verify for Lossless Large Language Model Acceleration, and Chimera: A Lossless Decoding Method for Accelerating Large Language Models.
Critical Analysis
The Recurrent Drafter for Fast Speculative Decoding in Large Language Models paper presents a promising approach to accelerating language model decoding, but there are a few potential limitations and areas for further research.
One concern is the computational overhead of running the drafting module in parallel with the main model. While the authors report significant speedups, the additional computational resources required could be a bottleneck, especially for resource-constrained applications.
Additionally, the paper focuses on standard language tasks like text generation and summarization. It would be valuable to explore the Recurrent Drafter's performance on more diverse and challenging tasks, such as open-ended dialogue, where the benefits of faster decoding may be even more pronounced.
The authors also acknowledge that the Recurrent Drafter may not be suitable for all language model applications, as the drafting process could introduce biases or other unwanted artifacts in the final outputs. Further research is needed to understand the limitations and potential pitfalls of this approach.
Overall, the Recurrent Drafter for Fast Speculative Decoding in Large Language Models paper presents an exciting and promising direction for accelerating language model inference, but more work is needed to fully understand its capabilities and limitations.
Conclusion
The Recurrent Drafter for Fast Speculative Decoding in Large Language Models paper introduces a novel technique for speeding up the decoding process in large language models. By generating draft outputs in parallel with the main output, the Recurrent Drafter can significantly reduce the time required to produce high-quality text, while maintaining the overall quality.
This approach has the potential to greatly benefit a wide range of applications that rely on fast, high-quality language generation, such as conversational assistants, creative writing tools, and real-time translation. The paper also lays the groundwork for further research into speculative decoding techniques and their integration with large language models.
As the field of natural language processing continues to advance, innovations like the Recurrent Drafter will be crucial in making these powerful models more accessible and useful in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Recurrent Drafter for Fast Speculative Decoding in Large Language Models
Aonan Zhang, Chong Wang, Yi Wang, Xuanyu Zhang, Yunfei Cheng
In this paper, we introduce an improved approach of speculative decoding aimed at enhancing the efficiency of serving large language models. Our method capitalizes on the strengths of two established techniques: the classic two-model speculative decoding approach, and the more recent single-model approach, Medusa. Drawing inspiration from Medusa, our approach adopts a single-model strategy for speculative decoding. However, our method distinguishes itself by employing a single, lightweight draft head with a recurrent dependency design, akin in essence to the small, draft model uses in classic speculative decoding, but without the complexities of the full transformer architecture. And because of the recurrent dependency, we can use beam search to swiftly filter out undesired candidates with the draft head. The outcome is a method that combines the simplicity of single-model design and avoids the need to create a data-dependent tree attention structure only for inference in Medusa. We empirically demonstrate the effectiveness of the proposed method on several popular open source language models, along with a comprehensive analysis of the trade-offs involved in adopting this approach.
Read more5/31/2024

0
Graph-Structured Speculative Decoding
Zhuocheng Gong, Jiahao Liu, Ziyue Wang, Pengfei Wu, Jingang Wang, Xunliang Cai, Dongyan Zhao, Rui Yan
Speculative decoding has emerged as a promising technique to accelerate the inference of Large Language Models (LLMs) by employing a small language model to draft a hypothesis sequence, which is then validated by the LLM. The effectiveness of this approach heavily relies on the balance between performance and efficiency of the draft model. In our research, we focus on enhancing the proportion of draft tokens that are accepted to the final output by generating multiple hypotheses instead of just one. This allows the LLM more options to choose from and select the longest sequence that meets its standards. Our analysis reveals that hypotheses produced by the draft model share many common token sequences, suggesting a potential for optimizing computation. Leveraging this observation, we introduce an innovative approach utilizing a directed acyclic graph (DAG) to manage the drafted hypotheses. This structure enables us to efficiently predict and merge recurring token sequences, vastly reducing the computational demands of the draft model. We term this approach Graph-structured Speculative Decoding (GSD). We apply GSD across a range of LLMs, including a 70-billion parameter LLaMA-2 model, and observe a remarkable speedup of 1.73$times$ to 1.96$times$, significantly surpassing standard speculative decoding.
Read more7/24/2024
0
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
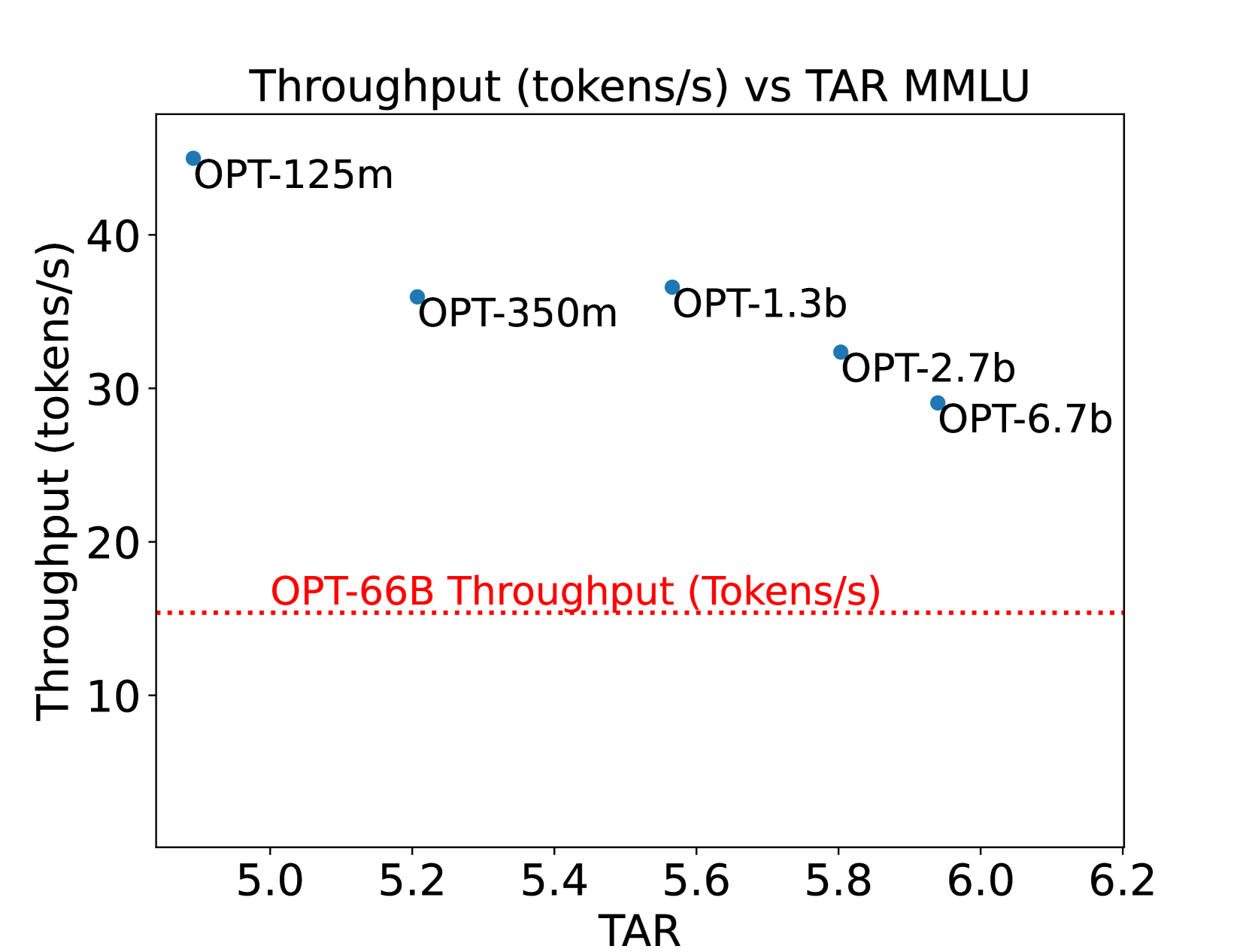
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 111% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
Read more8/13/2024
0
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Euiin Yi, Taehyeon Kim, Hongseok Jeung, Du-Seong Chang, Se-Young Yun
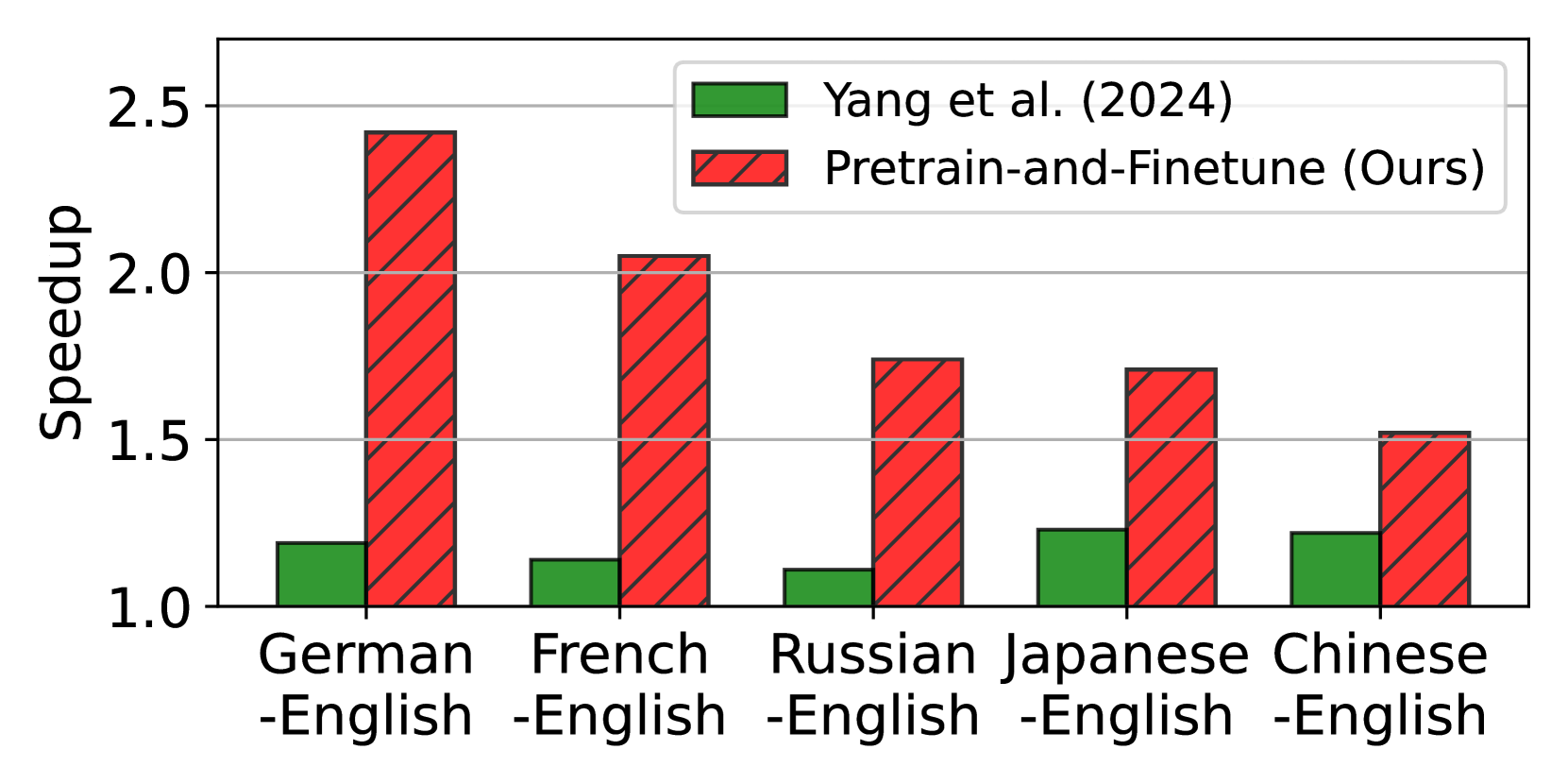
Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.
Read more6/26/2024