CLUE: Concept-Level Uncertainty Estimation for Large Language Models

0

Sign in to get full access
Overview
- The paper proposes a method called CLUE (Concept-Level Uncertainty Estimation) for estimating uncertainty in large language models.
- CLUE provides uncertainty scores at the concept level, allowing users to understand which parts of a language model's output are more or less reliable.
- The approach is evaluated on several tasks, including question answering and medical diagnosis, demonstrating its effectiveness.
Plain English Explanation
CLUE: Concept-Level Uncertainty Estimation for Large Language Models presents a way to better understand the uncertainty in the outputs of large language models. These models, like GPT-3, can generate human-like text on a wide range of topics, but they don't always know when they are uncertain or making mistakes.
The key idea behind CLUE is to provide uncertainty scores for each individual concept or idea in the model's output, rather than just a single overall score. This allows users to see which parts of the output are more reliable and which parts are more uncertain or speculative.
For example, if a language model is asked to diagnose a medical condition, CLUE could indicate that the model is highly confident about certain symptoms but more uncertain about the underlying cause. This extra information helps users interpret the model's output more accurately and make better decisions.
The researchers tested CLUE on several real-world tasks, including question answering and medical diagnosis. They found that CLUE could reliably identify the model's areas of uncertainty, providing valuable insights that could improve the way these powerful language models are used in practice.
Technical Explanation
CLUE: Concept-Level Uncertainty Estimation for Large Language Models introduces a novel approach for estimating uncertainty in the outputs of large language models. Rather than providing a single overall uncertainty score, CLUE generates uncertainty scores at the individual concept level, allowing users to understand which parts of the model's output are more or less reliable.
The key components of the CLUE method are:
- Concept Extraction: The model's output is first broken down into individual concepts or ideas using a concept extraction module.
- Uncertainty Estimation: For each extracted concept, the model's uncertainty is estimated using a specialized uncertainty estimation module.
- Aggregation: The individual concept-level uncertainty scores are then aggregated to provide an overall uncertainty assessment for the entire output.
The researchers evaluate CLUE on a variety of tasks, including question answering and medical diagnosis. They demonstrate that CLUE can effectively identify the model's areas of uncertainty, which can be crucial for improving the reliability and safety of large language models in real-world applications.
Critical Analysis
The CLUE: Concept-Level Uncertainty Estimation for Large Language Models paper presents a promising approach for enhancing the transparency and interpretability of large language models. By providing uncertainty estimates at the concept level, CLUE can help users better understand the limitations and weaknesses of these powerful models, which is an important step towards making them more robust and trustworthy.
However, the paper also acknowledges several limitations and areas for future research. For instance, the concept extraction module may not always accurately identify the relevant concepts, and the uncertainty estimation process could be further refined. Additionally, the evaluation tasks in the paper are relatively narrow, and more diverse real-world applications would be needed to fully assess the practical value of CLUE.
Overall, the CLUE approach represents an important contribution to the ongoing efforts to improve the uncertainty quantification and reliability of large language models. As these models become increasingly influential in various domains, developing methods like CLUE will be crucial for ensuring their safe and responsible deployment.
Conclusion
CLUE: Concept-Level Uncertainty Estimation for Large Language Models introduces a novel approach for estimating uncertainty in the outputs of large language models. By providing uncertainty scores at the individual concept level, CLUE can help users better understand the reliability and limitations of these powerful models, which is critical for their safe and responsible deployment in real-world applications.
The paper's evaluation demonstrates the effectiveness of the CLUE method across several tasks, including question answering and medical diagnosis. While the approach has some limitations that require further research, it represents an important step towards enhancing the transparency and interpretability of large language models, which will be essential as they continue to grow in influence and impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLUE: Concept-Level Uncertainty Estimation for Large Language Models
Yu-Hsiang Wang, Andrew Bai, Che-Ping Tsai, Cho-Jui Hsieh
Large Language Models (LLMs) have demonstrated remarkable proficiency in various natural language generation (NLG) tasks. Previous studies suggest that LLMs' generation process involves uncertainty. However, existing approaches to uncertainty estimation mainly focus on sequence-level uncertainty, overlooking individual pieces of information within sequences. These methods fall short in separately assessing the uncertainty of each component in a sequence. In response, we propose a novel framework for Concept-Level Uncertainty Estimation (CLUE) for LLMs. We leverage LLMs to convert output sequences into concept-level representations, breaking down sequences into individual concepts and measuring the uncertainty of each concept separately. We conduct experiments to demonstrate that CLUE can provide more interpretable uncertainty estimation results compared with sentence-level uncertainty, and could be a useful tool for various tasks such as hallucination detection and story generation.
Read more9/6/2024

0
Uncertainty Estimation of Large Language Models in Medical Question Answering
Jiaxin Wu, Yizhou Yu, Hong-Yu Zhou
Large Language Models (LLMs) show promise for natural language generation in healthcare, but risk hallucinating factually incorrect information. Deploying LLMs for medical question answering necessitates reliable uncertainty estimation (UE) methods to detect hallucinations. In this work, we benchmark popular UE methods with different model sizes on medical question-answering datasets. Our results show that current approaches generally perform poorly in this domain, highlighting the challenge of UE for medical applications. We also observe that larger models tend to yield better results, suggesting a correlation between model size and the reliability of UE. To address these challenges, we propose Two-phase Verification, a probability-free Uncertainty Estimation approach. First, an LLM generates a step-by-step explanation alongside its initial answer, followed by formulating verification questions to check the factual claims in the explanation. The model then answers these questions twice: first independently, and then referencing the explanation. Inconsistencies between the two sets of answers measure the uncertainty in the original response. We evaluate our approach on three biomedical question-answering datasets using Llama 2 Chat models and compare it against the benchmarked baseline methods. The results show that our Two-phase Verification method achieves the best overall accuracy and stability across various datasets and model sizes, and its performance scales as the model size increases.
Read more7/12/2024
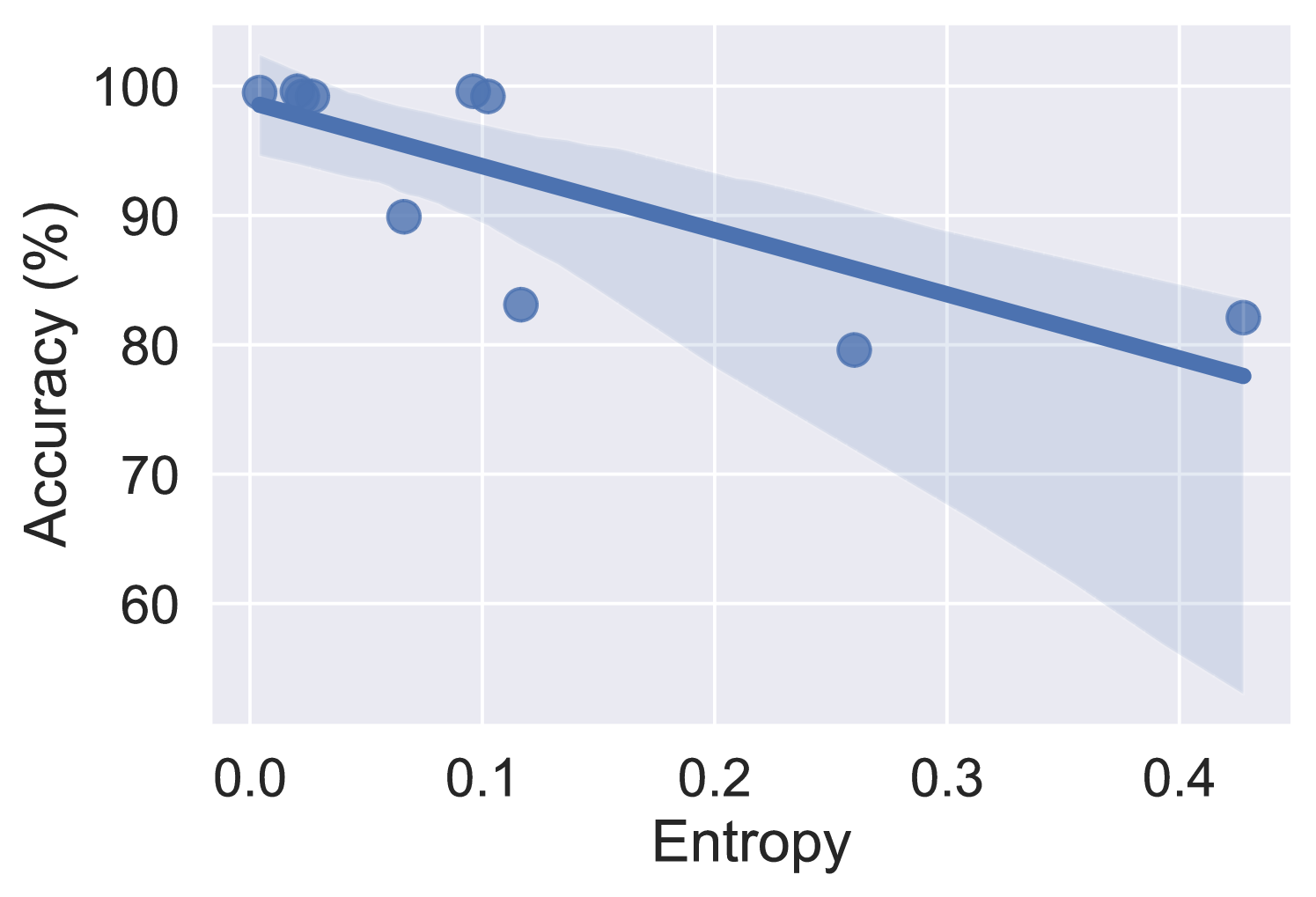
0
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
Read more4/15/2024
💬
0
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
Read more5/21/2024