Large Language Models Must Be Taught to Know What They Don't Know
2406.08391
0
0

Abstract
When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
Create account to get full access
Overview
- Large language models (LLMs) have become increasingly capable, but they often struggle to convey the limits of their knowledge and capabilities.
- This can lead to issues like overconfidence and poor decision-making.
- The researchers argue that LLMs must be equipped with the ability to recognize and express their uncertainty in order to be used safely and effectively.
Plain English Explanation
The paper discusses the challenges posed by the growing capabilities of large language models (LLMs). These AI systems have become remarkably good at generating human-like text, answering questions, and completing a wide variety of language-related tasks. However, the authors point out that LLMs often struggle to convey the boundaries of their knowledge and skills.
This can be a significant problem. When an LLM is overly confident in its abilities, it may produce responses that seem authoritative but are actually incorrect or misguided. This could lead to poor decision-making, the propagation of misinformation, or other harmful outcomes. The research on the importance of uncertainty in decision-making with LLMs highlights the need for these models to be able to express their level of confidence and uncertainty.
To address this issue, the researchers argue that LLMs must be "taught to know what they don't know." In other words, these models need to be equipped with the ability to recognize the limits of their knowledge and capabilities, and to effectively communicate that uncertainty to users. This could involve techniques like uncertainty estimation or confidence calibration, which help the LLM understand and express the reliability of its outputs.
By developing LLMs that are more self-aware and transparent about their limitations, the researchers hope to create AI systems that can be used more safely and effectively, without the risk of overconfidence leading to harmful outcomes.
Technical Explanation
The paper argues that as large language models (LLMs) become more capable, it is critical that they be equipped with the ability to recognize and express the limits of their knowledge and capabilities. The authors note that LLMs often struggle to convey their uncertainty, which can lead to issues like overconfidence and poor decision-making.
To address this, the researchers propose that LLMs must be "taught to know what they don't know." This could involve techniques like uncertainty estimation, which helps the model quantify the reliability of its outputs, or confidence calibration, which aligns the model's confidence with its actual capabilities.
The paper discusses the importance of uncertainty awareness in decision-making with LLMs, as well as research on LLM confidence estimation. The authors argue that by developing LLMs that can faithfully express their uncertainty, these systems can be used more safely and effectively, without the risk of overconfidence leading to harmful outcomes.
Critical Analysis
The paper makes a compelling case for the need to equip large language models (LLMs) with the ability to recognize and communicate their uncertainty. The authors rightly point out that overconfidence in LLM outputs can lead to significant issues, and that addressing this problem is critical for the safe and effective deployment of these systems.
One potential limitation of the research is that the specific techniques for teaching LLMs to know what they don't know are not fully explored. The paper discusses uncertainty estimation and confidence calibration as potential approaches, but more details on the implementation and evaluation of these methods would be helpful.
Additionally, the paper does not address the challenge of communicating uncertainty to end-users in a way that is easily understood and actionable. Even if an LLM can internally quantify its uncertainty, effectively conveying that information to users in a meaningful way may require further research and innovation.
Overall, the paper makes a strong case for the importance of uncertainty awareness in LLMs, and the researchers' call to action is well-justified. By continuing to explore methods for enhancing LLM transparency and self-awareness, the field can work towards developing AI systems that are more trustworthy and reliable.
Conclusion
The researchers argue that as large language models (LLMs) become increasingly capable, it is critical that they be equipped with the ability to recognize and express the limits of their knowledge and capabilities. Overconfidence in LLM outputs can lead to significant issues, such as poor decision-making and the propagation of misinformation.
To address this problem, the authors propose that LLMs must be "taught to know what they don't know." This could involve techniques like uncertainty estimation and confidence calibration, which help the models quantify and communicate the reliability of their outputs. By developing LLMs that are more self-aware and transparent about their limitations, the researchers hope to create AI systems that can be used more safely and effectively.
Overall, the paper makes a compelling case for the importance of uncertainty awareness in LLMs, and the researchers' call to action is an important step towards developing more trustworthy and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
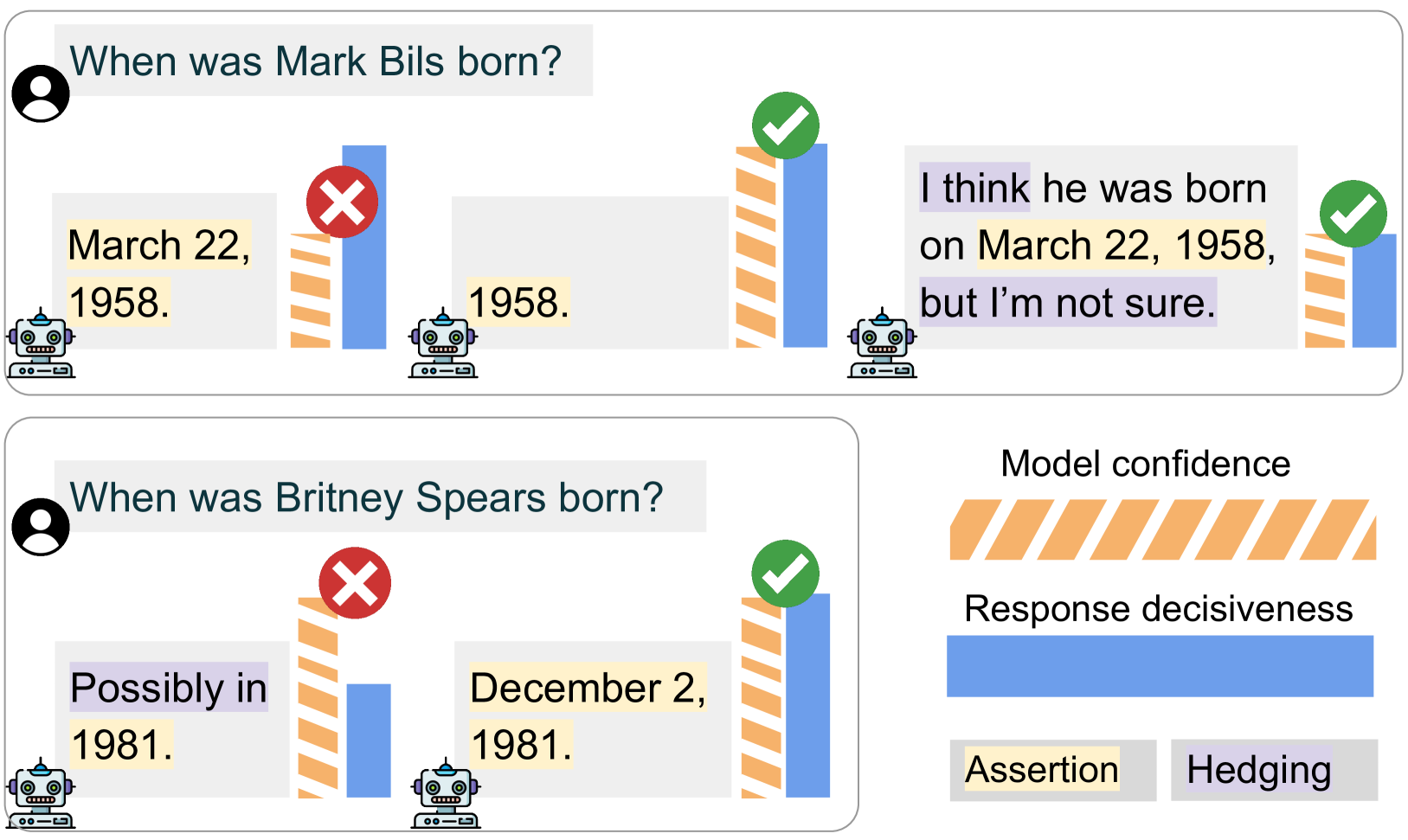
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
0
0
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
5/28/2024
💬
Knowledge of Knowledge: Exploring Known-Unknowns Uncertainty with Large Language Models
Alfonso Amayuelas, Liangming Pan, Wenhu Chen, William Wang
0
0
This paper investigates the capabilities of Large Language Models (LLMs) in the context of understanding their knowledge and uncertainty over questions. Specifically, we focus on addressing known-unknown questions, characterized by high uncertainty due to the absence of definitive answers. To facilitate our study, we collect a new dataset with Known-Unknown Questions (KUQ) and establish a categorization framework to clarify the origins of uncertainty in such queries. Subsequently, we examine the performance of open-source LLMs, fine-tuned using this dataset, in distinguishing between known and unknown queries within open-ended question-answering scenarios. The fine-tuned models demonstrated a significant improvement, achieving a considerable increase in F1-score relative to their pre-fine-tuning state. Through a comprehensive analysis, we reveal insights into the models' improved uncertainty articulation and their consequent efficacy in multi-agent debates. These findings help us understand how LLMs can be trained to identify and express uncertainty, improving our knowledge of how they understand and express complex or unclear information.
6/24/2024
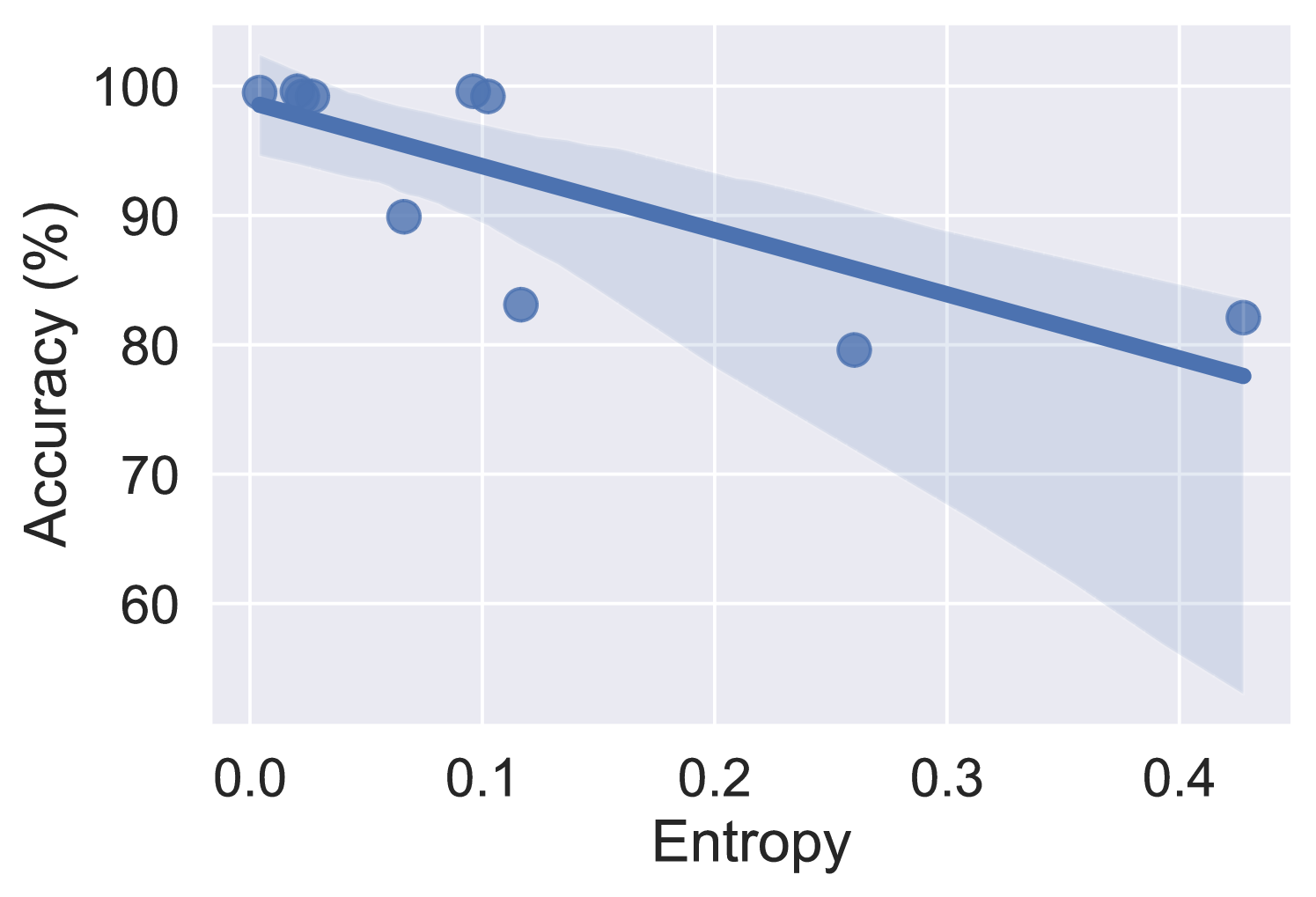
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
0
0
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
4/15/2024

To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
0
0
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
6/5/2024