Uncertainty Estimation of Large Language Models in Medical Question Answering

0

Sign in to get full access
Overview
- This paper investigates the uncertainty estimation of large language models (LLMs) in medical question answering.
- The researchers propose a method to quantify the uncertainty of LLM outputs and show how this can improve the reliability of medical question answering systems.
- They evaluate their approach on a medical question answering dataset and demonstrate that their uncertainty-aware model outperforms standard LLMs in terms of accuracy and calibration.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive performance on a variety of tasks, including answering medical questions. However, these models can sometimes be overconfident in their responses, even when they are wrong. This can be a problem in sensitive domains like healthcare, where relying on incorrect answers could have serious consequences.
The researchers in this paper address this issue by developing a way to estimate the uncertainty of an LLM's responses. Their approach allows the model to not only provide an answer, but also indicate how confident it is in that answer. This "uncertainty-aware" system can then be used to improve the reliability of medical question answering, by flagging responses where the model is unsure or potentially inaccurate.
To evaluate their method, the researchers tested it on a dataset of medical questions. They found that their uncertainty-aware model was more accurate and better calibrated than a standard LLM. This means it was able to provide more reliable answers, and better distinguish between questions it could answer confidently and those where it was more uncertain.
Technical Explanation
The researchers propose a method to estimate the uncertainty of large language models (LLMs) in the context of medical question answering. They build upon recent work on fact-checking the outputs of LLMs and generating confidence and uncertainty quantification for black-box models.
Their approach involves training a separate uncertainty estimation model that takes the LLM's output and other relevant features as input, and predicts a measure of uncertainty for the response. This uncertainty score is then used to calibrate the LLM's outputs, allowing the system to express confidence (or lack thereof) in its answers.
The researchers evaluate their uncertainty-aware LLM on the MedQA dataset, a benchmark for medical question answering. They show that their model achieves higher accuracy and better calibration compared to a standard LLM. This indicates that the uncertainty estimates are effective in identifying when the LLM is likely to make mistakes, which can be valuable in safety-critical domains like healthcare.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the uncertainty estimation model is trained separately from the LLM, which may not fully capture the model's internal uncertainty. Future work could explore ways to integrate uncertainty estimation more tightly into the LLM architecture.
Additionally, the paper focuses on a specific medical question answering task, and it's unclear how well the uncertainty estimation approach would generalize to other domains or applications of LLMs. Further research is needed to understand the broader applicability of this method.
Overall, the proposed approach represents an important step towards making LLMs more reliable and trustworthy, particularly in safety-critical domains. However, more work is still needed to fully address the challenges of uncertainty estimation and calibration for these powerful language models.
Conclusion
This paper presents a method for estimating the uncertainty of large language models (LLMs) in medical question answering. By training a separate uncertainty estimation model, the researchers are able to provide LLM outputs with calibrated confidence scores, which can improve the reliability of these systems in safety-critical domains like healthcare.
The evaluation on the MedQA dataset shows that the uncertainty-aware LLM outperforms a standard LLM in terms of both accuracy and calibration. This suggests that quantifying and expressing model uncertainty is an important capability for deploying LLMs in real-world applications.
While the proposed approach has limitations, it represents a valuable contribution to the ongoing efforts to make LLMs more trustworthy and robust. As these powerful language models continue to advance, developing reliable uncertainty estimation techniques will be crucial for their safe and responsible deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Uncertainty Estimation of Large Language Models in Medical Question Answering
Jiaxin Wu, Yizhou Yu, Hong-Yu Zhou
Large Language Models (LLMs) show promise for natural language generation in healthcare, but risk hallucinating factually incorrect information. Deploying LLMs for medical question answering necessitates reliable uncertainty estimation (UE) methods to detect hallucinations. In this work, we benchmark popular UE methods with different model sizes on medical question-answering datasets. Our results show that current approaches generally perform poorly in this domain, highlighting the challenge of UE for medical applications. We also observe that larger models tend to yield better results, suggesting a correlation between model size and the reliability of UE. To address these challenges, we propose Two-phase Verification, a probability-free Uncertainty Estimation approach. First, an LLM generates a step-by-step explanation alongside its initial answer, followed by formulating verification questions to check the factual claims in the explanation. The model then answers these questions twice: first independently, and then referencing the explanation. Inconsistencies between the two sets of answers measure the uncertainty in the original response. We evaluate our approach on three biomedical question-answering datasets using Llama 2 Chat models and compare it against the benchmarked baseline methods. The results show that our Two-phase Verification method achieves the best overall accuracy and stability across various datasets and model sizes, and its performance scales as the model size increases.
Read more7/12/2024

40
To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
Read more7/18/2024
0
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov
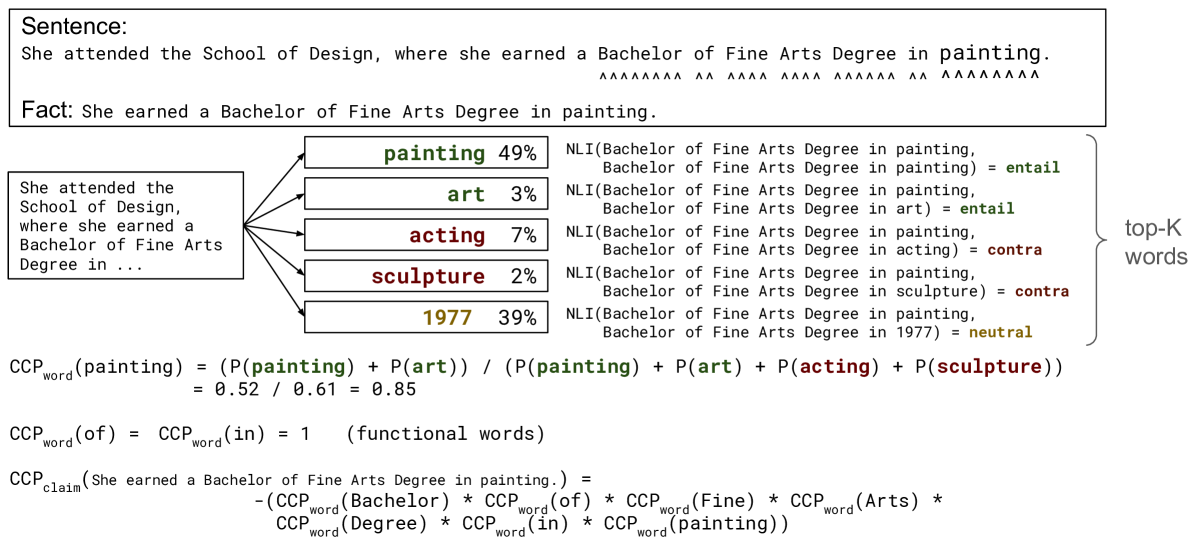
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factually correct, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of a particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for seven LLMs and four languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
Read more6/10/2024
0
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
Read more4/15/2024