Clustering and Alignment: Understanding the Training Dynamics in Modular Addition

0
Sign in to get full access
Overview
- Examines the training dynamics of modular addition in neural networks
- Explores how representations are shaped during training, leading to clustering and alignment
- Provides insights into the mechanisms driving the performance of neural networks on this task
Plain English Explanation
The paper explores how neural networks learn to perform the task of modular addition, where the goal is to add two numbers and output the result, taking into account the modulo (remainder) of the addition. The researchers investigate the training dynamics, or how the network's internal representations change over the course of training.
They find that during training, the network's representations [object Object] - the network learns to group similar inputs together in its hidden layers. Additionally, the researchers observe [object Object] between the network's representations and the target output, where the network's internal states become closely tied to the desired output.
These insights into the clustering and alignment of representations during training help explain the remarkable performance of neural networks on the modular addition task, and potentially other related tasks as well.
Technical Explanation
The paper examines the training dynamics of neural networks on the task of modular addition. The researchers analyze how the network's internal representations evolve during training, observing two key phenomena:
-
Representation Clustering: The network learns to group similar inputs together in its hidden layers, forming distinct clusters of representations.
-
Representation Alignment: The network's internal representations become closely aligned with the desired output, indicating a strong coupling between the network's internal states and the target modular addition result.
The researchers hypothesize that these mechanisms of clustering and alignment play a crucial role in enabling the impressive performance of neural networks on the modular addition task.
Critical Analysis
The paper provides valuable insights into the training dynamics of neural networks on the modular addition task. The observed phenomena of representation clustering and alignment offer a compelling explanation for the networks' strong performance.
However, the paper does not explore the potential limitations or caveats of these findings. For instance, it would be interesting to understand how these dynamics might change for more complex or larger-scale tasks, or whether they generalize to other arithmetic operations beyond modular addition.
Additionally, the paper does not delve into the implications of these findings for the broader field of deep learning. Further research could investigate whether the observed mechanisms play a role in the success of neural networks on a wider range of tasks, and how these insights might inform the design of more efficient and robust neural network architectures.
Conclusion
This paper offers a detailed examination of the training dynamics in neural networks performing modular addition. The key findings of representation clustering and alignment provide a deeper understanding of the mechanisms underlying the remarkable performance of these models on this task.
While the paper does not explore all the potential implications and limitations of these insights, it serves as an important step in unraveling the inner workings of neural networks and their ability to learn complex mathematical operations. Further research building on these findings could yield valuable insights for the continued advancement of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Clustering and Alignment: Understanding the Training Dynamics in Modular Addition
Tiberiu Musat
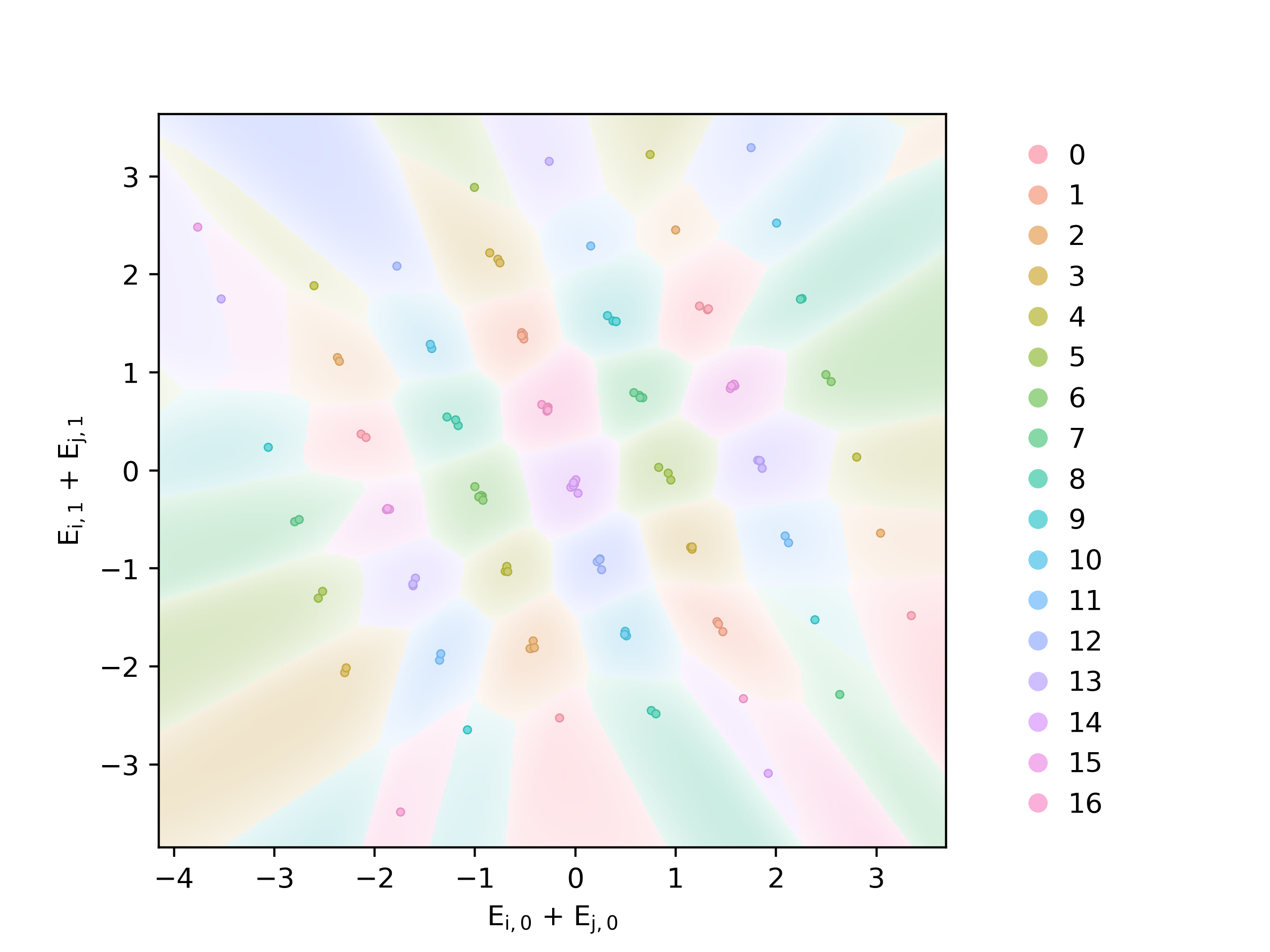
Recent studies have revealed that neural networks learn interpretable algorithms for many simple problems. However, little is known about how these algorithms emerge during training. In this article, we study the training dynamics of a simplified transformer with 2-dimensional embeddings on the problem of modular addition. We observe that embedding vectors tend to organize into two types of structures: grids and circles. We study these structures and explain their emergence as a result of two simple tendencies exhibited by pairs of embeddings: clustering and alignment. We propose explicit formulae for these tendencies as interaction forces between different pairs of embeddings. To show that our formulae can fully account for the emergence of these structures, we construct an equivalent particle simulation where we find that identical structures emerge. We use our insights to discuss the role of weight decay and reveal a new mechanism that links regularization and training dynamics. We also release an interactive demo to support our findings: https://modular-addition.vercel.app/.
Read more8/20/2024

0
Transformer Alignment in Large Language Models
Murdock Aubry, Haoming Meng, Anton Sugolov, Vardan Papyan
Large Language Models (LLMs) have made significant strides in natural language processing, and a precise understanding of the internal mechanisms driving their success is essential. We regard LLMs as transforming embeddings via a discrete, coupled, nonlinear, dynamical system in high dimensions. This perspective motivates tracing the trajectories of individual tokens as they pass through transformer blocks, and linearizing the system along these trajectories through their Jacobian matrices. In our analysis of 38 openly available LLMs, we uncover the alignment of top left and right singular vectors of Residual Jacobians, as well as the emergence of linearity and layer-wise exponential growth. Notably, we discover that increased alignment $textit{positively correlates}$ with model performance. Metrics evaluated post-training show significant improvement in comparison to measurements made with randomly initialized weights, highlighting the significant effects of training in transformers. These findings reveal a remarkable level of regularity that has previously been overlooked, reinforcing the dynamical interpretation and paving the way for deeper understanding and optimization of LLM architectures.
Read more7/11/2024

0
Breaking Neural Network Scaling Laws with Modularity
Akhilan Boopathy, Sunshine Jiang, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
Modular neural networks outperform nonmodular neural networks on tasks ranging from visual question answering to robotics. These performance improvements are thought to be due to modular networks' superior ability to model the compositional and combinatorial structure of real-world problems. However, a theoretical explanation of how modularity improves generalizability, and how to leverage task modularity while training networks remains elusive. Using recent theoretical progress in explaining neural network generalization, we investigate how the amount of training data required to generalize on a task varies with the intrinsic dimensionality of a task's input. We show theoretically that when applied to modularly structured tasks, while nonmodular networks require an exponential number of samples with task dimensionality, modular networks' sample complexity is independent of task dimensionality: modular networks can generalize in high dimensions. We then develop a novel learning rule for modular networks to exploit this advantage and empirically show the improved generalization of the rule, both in- and out-of-distribution, on high-dimensional, modular tasks.
Read more9/10/2024
0
Survival of the Fittest Representation: A Case Study with Modular Addition
Xiaoman Delores Ding, Zifan Carl Guo, Eric J. Michaud, Ziming Liu, Max Tegmark
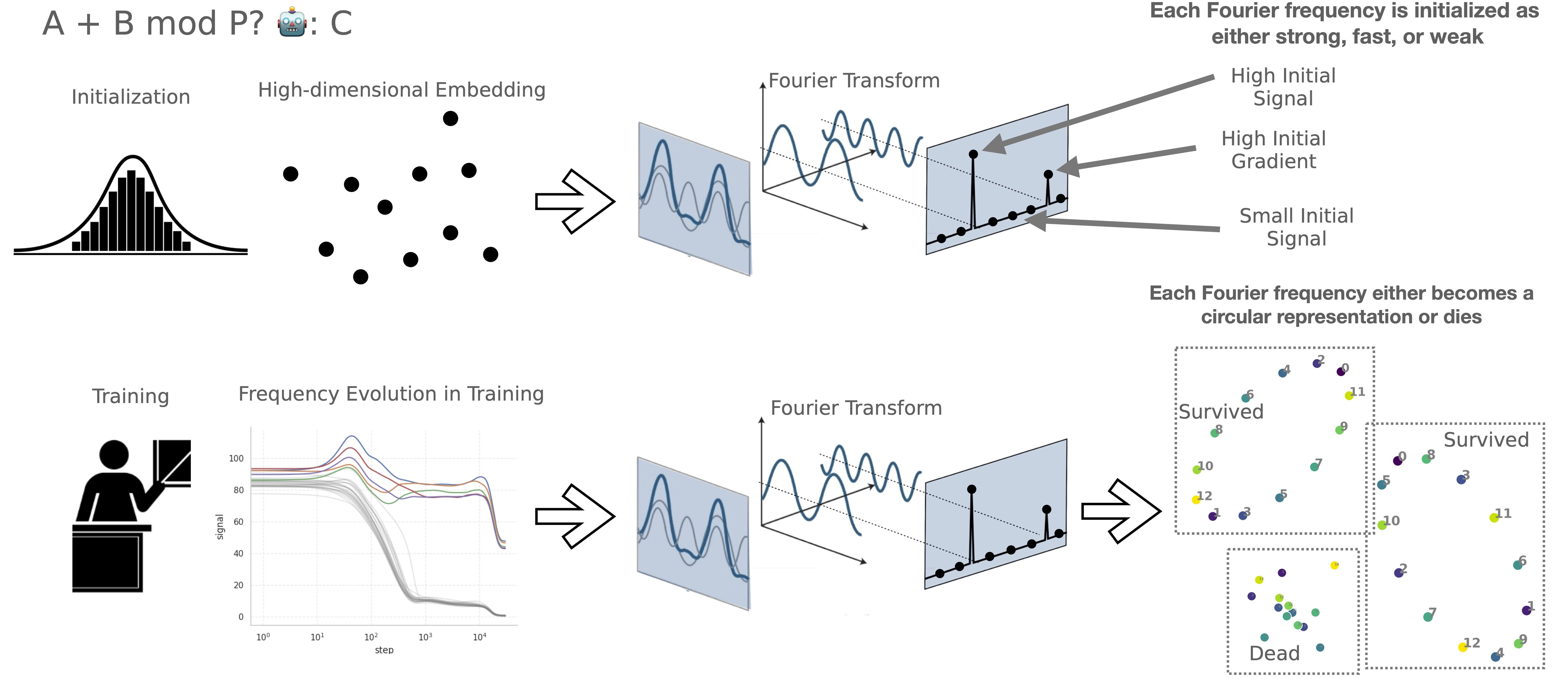
When a neural network can learn multiple distinct algorithms to solve a task, how does it choose between them during training? To approach this question, we take inspiration from ecology: when multiple species coexist, they eventually reach an equilibrium where some survive while others die out. Analogously, we suggest that a neural network at initialization contains many solutions (representations and algorithms), which compete with each other under pressure from resource constraints, with the fittest ultimately prevailing. To investigate this Survival of the Fittest hypothesis, we conduct a case study on neural networks performing modular addition, and find that these networks' multiple circular representations at different Fourier frequencies undergo such competitive dynamics, with only a few circles surviving at the end. We find that the frequencies with high initial signals and gradients, the fittest, are more likely to survive. By increasing the embedding dimension, we also observe more surviving frequencies. Inspired by the Lotka-Volterra equations describing the dynamics between species, we find that the dynamics of the circles can be nicely characterized by a set of linear differential equations. Our results with modular addition show that it is possible to decompose complicated representations into simpler components, along with their basic interactions, to offer insight on the training dynamics of representations.
Read more5/28/2024