Survival of the Fittest Representation: A Case Study with Modular Addition

0
Sign in to get full access
Overview
- This paper investigates the "survival of the fittest" representation in the context of modular addition, a fundamental arithmetic operation.
- The authors study how different representations of inputs and outputs can impact the performance and interpretability of machine learning models that perform modular addition.
- The findings provide insights into the dynamics and specialization of neural modules, which is relevant to research on Dynamics of Specialization in Neural Modules Under Resource Constraints and Exactly Solvable Model of the Emergence of Scaling Laws.
Plain English Explanation
The paper looks at how the way we represent numbers and mathematical operations can affect the performance and understandability of machine learning models that do basic arithmetic like addition. The researchers focus on a specific type of addition called "modular addition," where the results "wrap around" after reaching a certain limit (like a clock that goes back to 12 after 11).
By trying different ways of representing the inputs and outputs, the authors find that some representations work better than others. This suggests that the choice of representation can have a big impact on how well the model learns and how easy it is to understand what the model is doing.
The findings connect to other research on how neural networks specialize and develop internal structure as they learn. Understanding these dynamics can help us build more efficient and interpretable machine learning models, especially for tasks that involve basic mathematical operations.
Technical Explanation
The paper investigates the impact of representation on the performance and interpretability of machine learning models trained to perform modular addition. The authors consider various input and output representations, including binary, one-hot, and residue number system encodings.
Through experiments, the researchers find that certain representations lead to more efficient and interpretable models compared to others. For example, the residue number system representation enables the emergence of specialized neural modules that directly correspond to the individual digits in the modular addition operation.
This connects to prior work on the dynamics of specialization in neural modules under resource constraints and the emergence of scaling laws in neural network training. The authors suggest that the choice of representation can profoundly impact the weight dynamics and learning in neural networks as well as the frequency biases that arise.
Critical Analysis
The paper provides valuable insights into the importance of representation in the performance and interpretability of machine learning models. However, the authors acknowledge that the study is limited to the specific task of modular addition, and it remains to be seen whether the findings generalize to other arithmetic operations or more complex machine learning problems.
Additionally, while the residue number system representation enables the emergence of specialized modules, the paper does not explore the potential scalability challenges that may arise as the problem size increases. Further research is needed to understand the practical limitations and trade-offs of this approach.
The authors also do not discuss the computational overhead or memory requirements associated with the different representations, which could be important considerations in real-world applications. Exploring these aspects would provide a more comprehensive understanding of the practical implications of their findings.
Conclusion
This paper highlights the crucial role that representation plays in the performance and interpretability of machine learning models, even for fundamental arithmetic operations like modular addition. The authors' findings suggest that the choice of input and output representations can significantly impact the model's ability to learn and the degree to which its internal workings can be understood.
These insights have broader implications for the design and development of efficient and interpretable machine learning systems, particularly in domains where basic mathematical operations are a core component. By considering the representation aspect, researchers and practitioners can work towards building more robust and transparent models that can better serve real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Survival of the Fittest Representation: A Case Study with Modular Addition
Xiaoman Delores Ding, Zifan Carl Guo, Eric J. Michaud, Ziming Liu, Max Tegmark
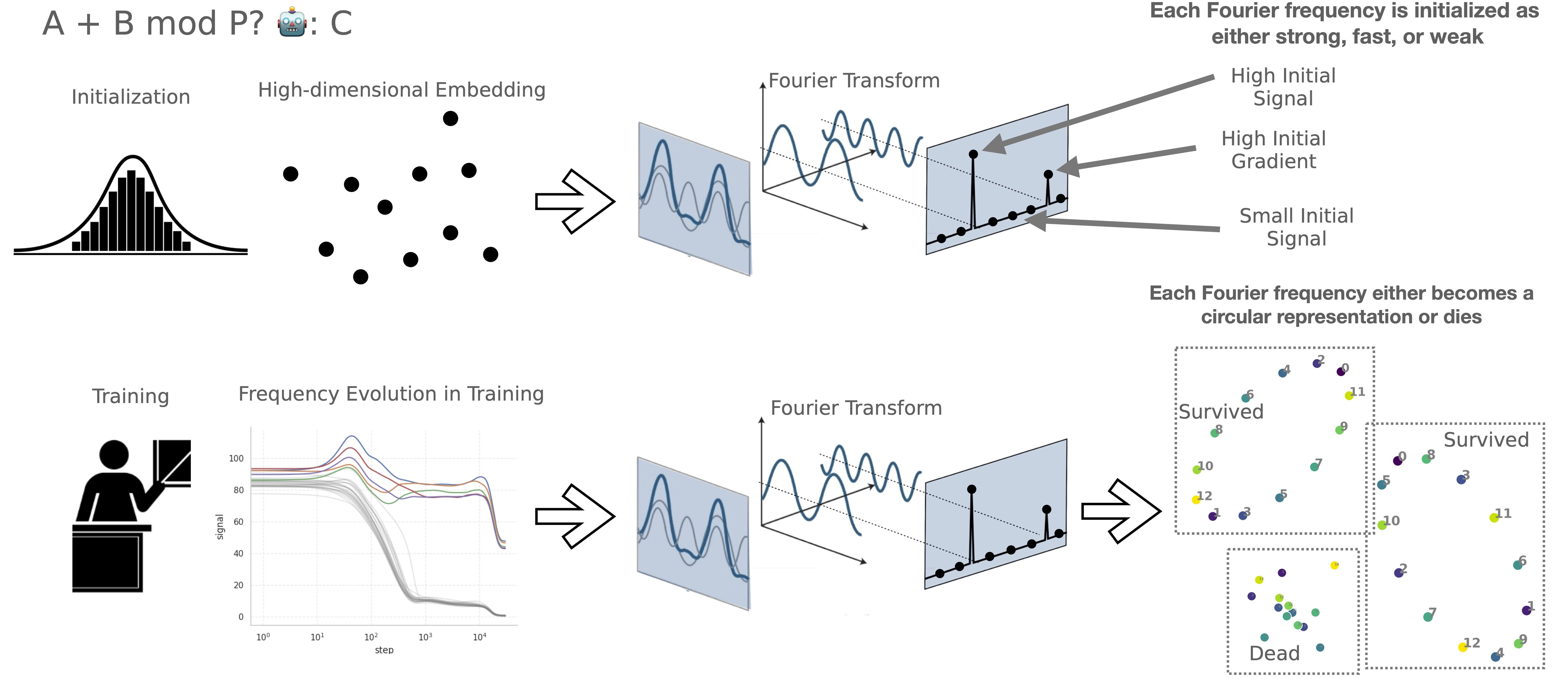
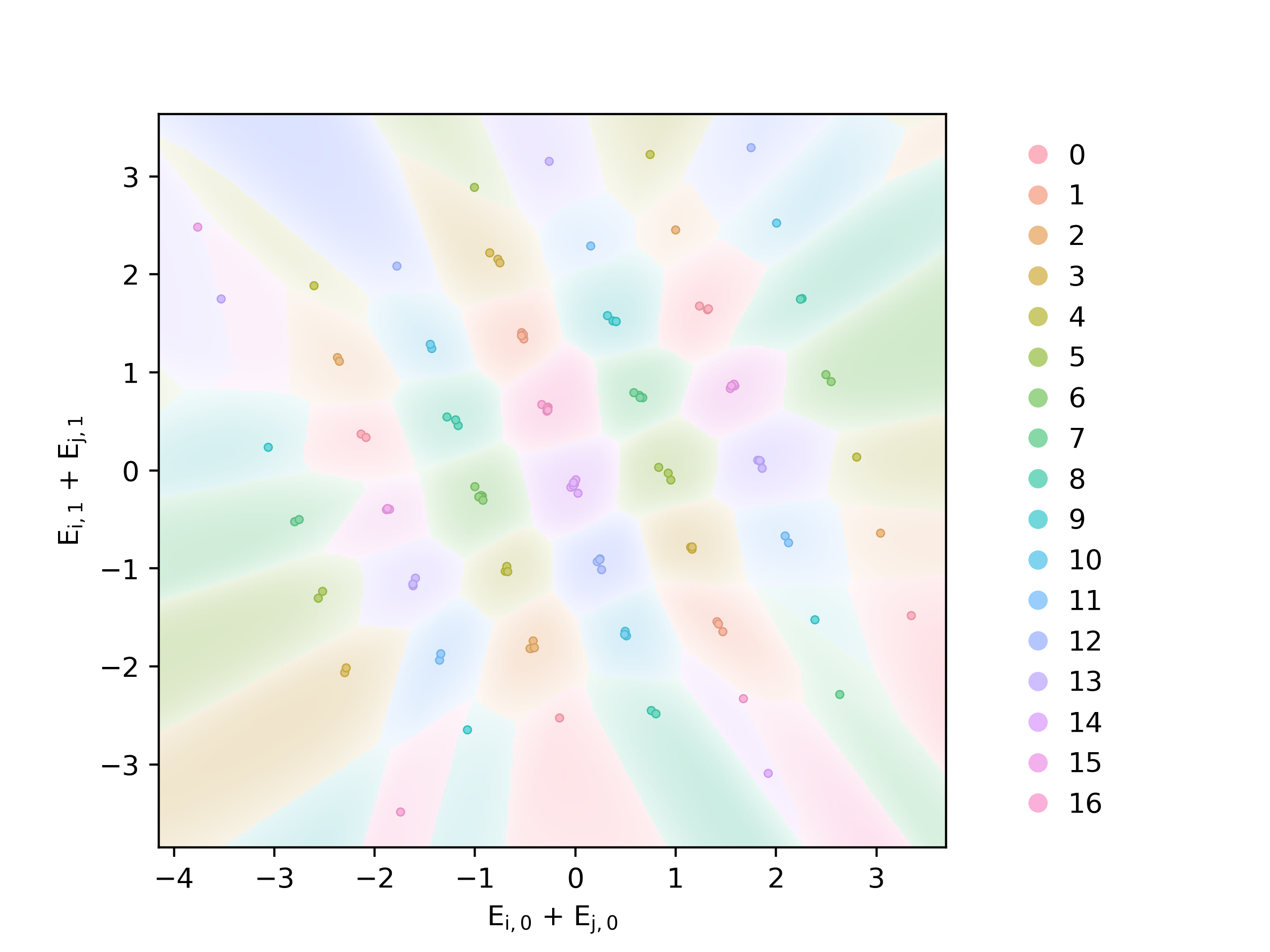
When a neural network can learn multiple distinct algorithms to solve a task, how does it choose between them during training? To approach this question, we take inspiration from ecology: when multiple species coexist, they eventually reach an equilibrium where some survive while others die out. Analogously, we suggest that a neural network at initialization contains many solutions (representations and algorithms), which compete with each other under pressure from resource constraints, with the fittest ultimately prevailing. To investigate this Survival of the Fittest hypothesis, we conduct a case study on neural networks performing modular addition, and find that these networks' multiple circular representations at different Fourier frequencies undergo such competitive dynamics, with only a few circles surviving at the end. We find that the frequencies with high initial signals and gradients, the fittest, are more likely to survive. By increasing the embedding dimension, we also observe more surviving frequencies. Inspired by the Lotka-Volterra equations describing the dynamics between species, we find that the dynamics of the circles can be nicely characterized by a set of linear differential equations. Our results with modular addition show that it is possible to decompose complicated representations into simpler components, along with their basic interactions, to offer insight on the training dynamics of representations.
Read more5/28/2024
0
Clustering and Alignment: Understanding the Training Dynamics in Modular Addition
Tiberiu Musat
Recent studies have revealed that neural networks learn interpretable algorithms for many simple problems. However, little is known about how these algorithms emerge during training. In this article, we study the training dynamics of a simplified transformer with 2-dimensional embeddings on the problem of modular addition. We observe that embedding vectors tend to organize into two types of structures: grids and circles. We study these structures and explain their emergence as a result of two simple tendencies exhibited by pairs of embeddings: clustering and alignment. We propose explicit formulae for these tendencies as interaction forces between different pairs of embeddings. To show that our formulae can fully account for the emergence of these structures, we construct an equivalent particle simulation where we find that identical structures emerge. We use our insights to discuss the role of weight decay and reveal a new mechanism that links regularization and training dynamics. We also release an interactive demo to support our findings: https://modular-addition.vercel.app/.
Read more8/20/2024

0
Fourier Circuits in Neural Networks: Unlocking the Potential of Large Language Models in Mathematical Reasoning and Modular Arithmetic
Jiuxiang Gu, Chenyang Li, Yingyu Liang, Zhenmei Shi, Zhao Song, Tianyi Zhou
In the evolving landscape of machine learning, a pivotal challenge lies in deciphering the internal representations harnessed by neural networks and Transformers. Building on recent progress toward comprehending how networks execute distinct target functions, our study embarks on an exploration of the underlying reasons behind networks adopting specific computational strategies. We direct our focus to the complex algebraic learning task of modular addition involving $k$ inputs. Our research presents a thorough analytical characterization of the features learned by stylized one-hidden layer neural networks and one-layer Transformers in addressing this task. A cornerstone of our theoretical framework is the elucidation of how the principle of margin maximization shapes the features adopted by one-hidden layer neural networks. Let $p$ denote the modulus, $D_p$ denote the dataset of modular arithmetic with $k$ inputs and $m$ denote the network width. We demonstrate that a neuron count of $ m geq 2^{2k-2} cdot (p-1) $, these networks attain a maximum $ L_{2,k+1} $-margin on the dataset $ D_p $. Furthermore, we establish that each hidden-layer neuron aligns with a specific Fourier spectrum, integral to solving modular addition problems. By correlating our findings with the empirical observations of similar studies, we contribute to a deeper comprehension of the intrinsic computational mechanisms of neural networks. Furthermore, we observe similar computational mechanisms in the attention matrix of the one-layer Transformer. This research stands as a significant stride in unraveling their operation complexities, particularly in the realm of complex algebraic tasks.
Read more5/27/2024
🧠
0
Dynamics of specialization in neural modules under resource constraints
Gabriel B'ena, Dan F. M. Goodman
It has long been believed that the brain is highly modular both in terms of structure and function, although recent evidence has led some to question the extent of both types of modularity. We used artificial neural networks to test the hypothesis that structural modularity is sufficient to guarantee functional specialization, and find that in general, this doesn't necessarily hold. We then systematically tested which features of the environment and network do lead to the emergence of specialization. We used a simple toy environment, task and network, allowing us precise control, and show that in this setup, several distinct measures of specialization give qualitatively similar results. We further find that in this setup (1) specialization can only emerge in environments where features of that environment are meaningfully separable, (2) specialization preferentially emerges when the network is strongly resource-constrained, and (3) these findings are qualitatively similar across the different variations of network architectures that we tested, but that the quantitative relationships depend on the precise architecture. Finally, we show that functional specialization varies dynamically across time, and demonstrate that these dynamics depend on both the timing and bandwidth of information flow in the network. We conclude that a static notion of specialization, based on structural modularity, is likely too simple a framework for understanding intelligence in situations of real-world complexity, from biology to brain-inspired neuromorphic systems. We propose that thoroughly stress testing candidate definitions of functional modularity in simplified scenarios before extending to more complex data, network models and electrophysiological recordings is likely to be a fruitful approach.
Read more5/21/2024