Clustering in Dynamic Environments: A Framework for Benchmark Dataset Generation With Heterogeneous Changes

0
Sign in to get full access
Overview
- This paper proposes a framework for generating benchmark datasets for clustering in dynamic environments, where the underlying data distribution changes over time.
- The framework allows for the creation of datasets with heterogeneous changes, including changes in the number of clusters, cluster shapes, and cluster locations.
- The paper also introduces several dynamic clustering evaluation metrics to assess the performance of clustering algorithms in these dynamic environments.
Plain English Explanation
The research paper describes a way to create test datasets that can be used to evaluate how well clustering algorithms perform when the data they are working with changes over time. Clustering is the process of grouping similar data points together, and it's a common task in machine learning. However, in the real world, the data we're working with often changes, and the clusters can shift, appear, or disappear. This makes it challenging to test and compare different clustering algorithms.
The framework proposed in the paper allows researchers to generate benchmark datasets that mimic these dynamic changes. They can control things like the number of clusters, their shapes, and their locations, and make them change in different ways over time. This gives algorithm developers a way to rigorously test their methods and see how well they hold up as the data evolves.
The paper also introduces some new metrics that can be used to evaluate the performance of clustering algorithms in these dynamic settings. This gives researchers a way to quantify how well a particular algorithm is able to adapt to the changing data, rather than just looking at how well it performs on a static snapshot.
Overall, this work provides a valuable tool for advancing the state of the art in dynamic clustering, which has important applications in areas like customer segmentation, anomaly detection, and more. By creating a standardized way to benchmark algorithms, it helps drive progress in this area of research.
Technical Explanation
The paper introduces a framework for generating benchmark datasets for clustering in dynamic environments. The framework allows for the creation of datasets with heterogeneous changes, including changes in the number of clusters, cluster shapes, and cluster locations over time.
The authors propose several dynamic clustering evaluation metrics to assess the performance of clustering algorithms in these dynamic environments. These metrics go beyond just looking at accuracy on a single snapshot, and instead measure how well the algorithms can adapt to the changing data distribution over time.
To generate the benchmark datasets, the framework uses a dynamic graph model to simulate the evolution of the clusters. This allows for precise control over the type and timing of changes to the underlying data structure.
The authors demonstrate the utility of their framework by evaluating several popular clustering algorithms on the generated datasets. The results show that existing methods struggle to maintain performance as the data changes, highlighting the need for more robust and adaptive clustering approaches.
Critical Analysis
The framework proposed in this paper is a valuable contribution to the field of dynamic clustering. By providing a systematic way to generate benchmark datasets, it enables more rigorous and reproducible evaluation of algorithms in realistic evolving environments.
One potential limitation is that the dynamic graph model used to generate the datasets, while flexible, may not capture all the nuances of real-world data evolution. The authors acknowledge this and suggest incorporating additional domain-specific knowledge to enhance the realism of the generated datasets.
Additionally, the evaluation metrics introduced in the paper, while well-designed, may not fully capture all the desirable properties of a good dynamic clustering algorithm. Factors like cluster interpretability, stability, and the ability to handle outliers could also be important considerations.
Further research could explore ways to extend the framework to support other types of dynamic changes, such as concept drift or the emergence of entirely new clusters. Investigating the robustness of the evaluation metrics to different types of changes would also be a valuable direction.
Overall, this work represents an important step forward in the study of clustering in dynamic environments, and the proposed framework and metrics provide a solid foundation for future research in this area.
Conclusion
This paper presents a framework for generating benchmark datasets to evaluate clustering algorithms in dynamic environments, where the underlying data distribution changes over time. The framework allows for the creation of datasets with heterogeneous changes, including variations in the number of clusters, cluster shapes, and cluster locations.
The paper also introduces several dynamic clustering evaluation metrics that go beyond just measuring accuracy on a single snapshot, and instead assess how well algorithms can adapt to the changing data over time. This provides a more comprehensive way to assess the performance of clustering methods in real-world, evolving scenarios.
The proposed framework and metrics represent an important contribution to the field of dynamic clustering, which has significant practical applications in areas like customer segmentation, anomaly detection, and more. By providing a standardized way to benchmark algorithms, this work helps drive progress in the development of more robust and adaptive clustering techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Clustering in Dynamic Environments: A Framework for Benchmark Dataset Generation With Heterogeneous Changes
Danial Yazdani, Juergen Branke, Mohammad Sadegh Khorshidi, Mohammad Nabi Omidvar, Xiaodong Li, Amir H. Gandomi, Xin Yao
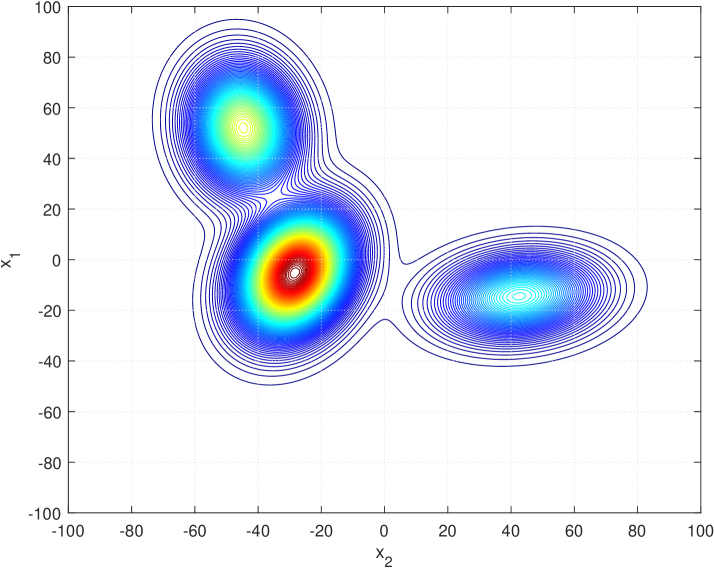
Clustering in dynamic environments is of increasing importance, with broad applications ranging from real-time data analysis and online unsupervised learning to dynamic facility location problems. While meta-heuristics have shown promising effectiveness in static clustering tasks, their application for tracking optimal clustering solutions or robust clustering over time in dynamic environments remains largely underexplored. This is partly due to a lack of dynamic datasets with diverse, controllable, and realistic dynamic characteristics, hindering systematic performance evaluations of clustering algorithms in various dynamic scenarios. This deficiency leads to a gap in our understanding and capability to effectively design algorithms for clustering in dynamic environments. To bridge this gap, this paper introduces the Dynamic Dataset Generator (DDG). DDG features multiple dynamic Gaussian components integrated with a range of heterogeneous, local, and global changes. These changes vary in spatial and temporal severity, patterns, and domain of influence, providing a comprehensive tool for simulating a wide range of dynamic scenarios.
Read more4/10/2024
0
Dynamic Quality-Diversity Search
Roberto Gallotta, Antonios Liapis, Georgios N. Yannakakis
Evolutionary search via the quality-diversity (QD) paradigm can discover highly performing solutions in different behavioural niches, showing considerable potential in complex real-world scenarios such as evolutionary robotics. Yet most QD methods only tackle static tasks that are fixed over time, which is rarely the case in the real world. Unlike noisy environments, where the fitness of an individual changes slightly at every evaluation, dynamic environments simulate tasks where external factors at unknown and irregular intervals alter the performance of the individual with a severity that is unknown a priori. Literature on optimisation in dynamic environments is extensive, yet such environments have not been explored in the context of QD search. This paper introduces a novel and generalisable Dynamic QD methodology that aims to keep the archive of past solutions updated in the case of environment changes. Secondly, we present a novel characterisation of dynamic environments that can be easily applied to well-known benchmarks, with minor interventions to move them from a static task to a dynamic one. Our Dynamic QD intervention is applied on MAP-Elites and CMA-ME, two powerful QD algorithms, and we test the dynamic variants on different dynamic tasks.
Read more4/10/2024

0
Dynamic Spectral Clustering with Provable Approximation Guarantee
Steinar Laenen, He Sun
This paper studies clustering algorithms for dynamically evolving graphs ${G_t}$, in which new edges (and potential new vertices) are added into a graph, and the underlying cluster structure of the graph can gradually change. The paper proves that, under some mild condition on the cluster-structure, the clusters of the final graph $G_T$ of $n_T$ vertices at time $T$ can be well approximated by a dynamic variant of the spectral clustering algorithm. The algorithm runs in amortised update time $O(1)$ and query time $o(n_T)$. Experimental studies on both synthetic and real-world datasets further confirm the practicality of our designed algorithm.
Read more6/6/2024
🔗
0
Improving the Utility of Differentially Private Clustering through Dynamical Processing
Junyoung Byun, Yujin Choi, Jaewook Lee
This study aims to alleviate the trade-off between utility and privacy of differentially private clustering. Existing works focus on simple methods, which show poor performance for non-convex clusters. To fit complex cluster distributions, we propose sophisticated dynamical processing inspired by Morse theory, with which we hierarchically connect the Gaussian sub-clusters obtained through existing methods. Our theoretical results imply that the proposed dynamical processing introduces little to no additional privacy loss. Experiments show that our framework can improve the clustering performance of existing methods at the same privacy level.
Read more8/23/2024