Co-Speech Gesture Detection through Multi-Phase Sequence Labeling

0
🔎
Sign in to get full access
Overview
- This paper introduces a novel framework for automatic gesture detection that treats the problem as a multi-phase sequence labeling task rather than binary classification.
- The proposed model processes sequences of skeletal movements over time, uses Transformer encoders to learn contextual embeddings, and leverages Conditional Random Fields for sequence labeling.
- The framework is evaluated on a large dataset of diverse co-speech gestures in task-oriented face-to-face dialogues, demonstrating significant improvements over baseline models in detecting gesture strokes.
Plain English Explanation
Gestures are an integral part of face-to-face communication. They typically involve a sequence of movements, including preparation, the main stroke, and retraction. However, the prevalent approach to automatic gesture detection treats this as a simple binary classification problem, where a segment is labeled as either containing a gesture or not. This fails to capture the inherently sequential and contextual nature of gestures.
To address this, the researchers have developed a new framework that reframes the task as a multi-phase sequence labeling problem. Their model takes in a sequence of skeletal movements over time and uses Transformer encoders to learn contextual embeddings. It then leverages Conditional Random Fields to perform the sequence labeling, identifying the different phases of a gesture (preparation, stroke, retraction).
The researchers evaluated their framework on a large dataset of co-speech gestures in task-oriented dialogues. The results show that their method significantly outperforms strong baseline models in detecting the key gesture stroke phase. Furthermore, the use of Transformer encoders to learn contextual embeddings from the movement sequences substantially improves the overall gesture detection accuracy.
These findings highlight the importance of modeling the sequential and contextual nature of gestures, which is crucial for more nuanced and accurate gesture detection and analysis in various applications, such as sign language scoring.
Technical Explanation
The paper presents a novel framework for automatic gesture detection that treats the problem as a multi-phase sequence labeling task rather than a binary classification problem. The key components of the proposed model are:
- Sequence processing: The model takes in a sequence of skeletal movements over a time window and processes them.
- Transformer encoders: The model uses Transformer encoders to learn contextual embeddings from the movement sequences, capturing the inherently sequential and contextual nature of gestures.
- Conditional Random Fields: The model leverages Conditional Random Fields (CRFs) to perform the sequence labeling, identifying the different phases of a gesture (preparation, stroke, retraction).
The researchers evaluated their framework on a large dataset of diverse co-speech gestures in task-oriented face-to-face dialogues. The results consistently demonstrate that their method significantly outperforms strong baseline models in detecting the gesture stroke phase, which is considered the most important part of a gesture. Furthermore, the application of Transformer encoders to learn contextual embeddings from the movement sequences substantially improves the overall gesture unit detection performance.
Critical Analysis
The paper presents a compelling approach to gesture detection that addresses the limitations of the prevalent binary classification methods. By reframing the problem as a multi-phase sequence labeling task, the researchers have shown the importance of capturing the inherently sequential and contextual nature of gestures.
One potential limitation of the research is the reliance on skeletal movement data, which may not be readily available in all real-world scenarios. It would be interesting to see how the framework could be extended to work with other modalities, such as video-based gesture recognition or audio-driven gesture generation.
Additionally, the paper could have delved deeper into the potential challenges and limitations of the CRF-based sequence labeling approach, as well as explored other sequence modeling techniques, such as recurrent neural networks or attention-based models, and how they might compare to the proposed framework.
Overall, the research presents a promising step forward in the field of gesture detection and analysis, and the findings could have significant implications for various applications, such as human-computer interaction, virtual reality, and sign language recognition.
Conclusion
This paper introduces a novel framework for automatic gesture detection that reframes the problem as a multi-phase sequence labeling task rather than a binary classification problem. By leveraging Transformer encoders to learn contextual embeddings from skeletal movement sequences and using Conditional Random Fields for sequence labeling, the proposed model is able to capture the inherently sequential and contextual nature of gestures, significantly outperforming strong baseline models in detecting the crucial gesture stroke phase.
These findings highlight the importance of modeling the fine-grained dynamics of co-speech gestures, paving the way for more nuanced and accurate gesture detection and analysis in a wide range of applications, from human-computer interaction to sign language recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Co-Speech Gesture Detection through Multi-Phase Sequence Labeling
Esam Ghaleb, Ilya Burenko, Marlou Rasenberg, Wim Pouw, Peter Uhrig, Judith Holler, Ivan Toni, Asl{i} Ozyurek, Raquel Fern'andez
Gestures are integral components of face-to-face communication. They unfold over time, often following predictable movement phases of preparation, stroke, and retraction. Yet, the prevalent approach to automatic gesture detection treats the problem as binary classification, classifying a segment as either containing a gesture or not, thus failing to capture its inherently sequential and contextual nature. To address this, we introduce a novel framework that reframes the task as a multi-phase sequence labeling problem rather than binary classification. Our model processes sequences of skeletal movements over time windows, uses Transformer encoders to learn contextual embeddings, and leverages Conditional Random Fields to perform sequence labeling. We evaluate our proposal on a large dataset of diverse co-speech gestures in task-oriented face-to-face dialogues. The results consistently demonstrate that our method significantly outperforms strong baseline models in detecting gesture strokes. Furthermore, applying Transformer encoders to learn contextual embeddings from movement sequences substantially improves gesture unit detection. These results highlight our framework's capacity to capture the fine-grained dynamics of co-speech gesture phases, paving the way for more nuanced and accurate gesture detection and analysis.
Read more4/24/2024

0
Leveraging Speech for Gesture Detection in Multimodal Communication
Esam Ghaleb, Ilya Burenko, Marlou Rasenberg, Wim Pouw, Ivan Toni, Peter Uhrig, Anna Wilson, Judith Holler, Asl{i} Ozyurek, Raquel Fern'andez
Gestures are inherent to human interaction and often complement speech in face-to-face communication, forming a multimodal communication system. An important task in gesture analysis is detecting a gesture's beginning and end. Research on automatic gesture detection has primarily focused on visual and kinematic information to detect a limited set of isolated or silent gestures with low variability, neglecting the integration of speech and vision signals to detect gestures that co-occur with speech. This work addresses this gap by focusing on co-speech gesture detection, emphasising the synchrony between speech and co-speech hand gestures. We address three main challenges: the variability of gesture forms, the temporal misalignment between gesture and speech onsets, and differences in sampling rate between modalities. We investigate extended speech time windows and employ separate backbone models for each modality to address the temporal misalignment and sampling rate differences. We utilize Transformer encoders in cross-modal and early fusion techniques to effectively align and integrate speech and skeletal sequences. The study results show that combining visual and speech information significantly enhances gesture detection performance. Our findings indicate that expanding the speech buffer beyond visual time segments improves performance and that multimodal integration using cross-modal and early fusion techniques outperforms baseline methods using unimodal and late fusion methods. Additionally, we find a correlation between the models' gesture prediction confidence and low-level speech frequency features potentially associated with gestures. Overall, the study provides a better understanding and detection methods for co-speech gestures, facilitating the analysis of multimodal communication.
Read more4/24/2024
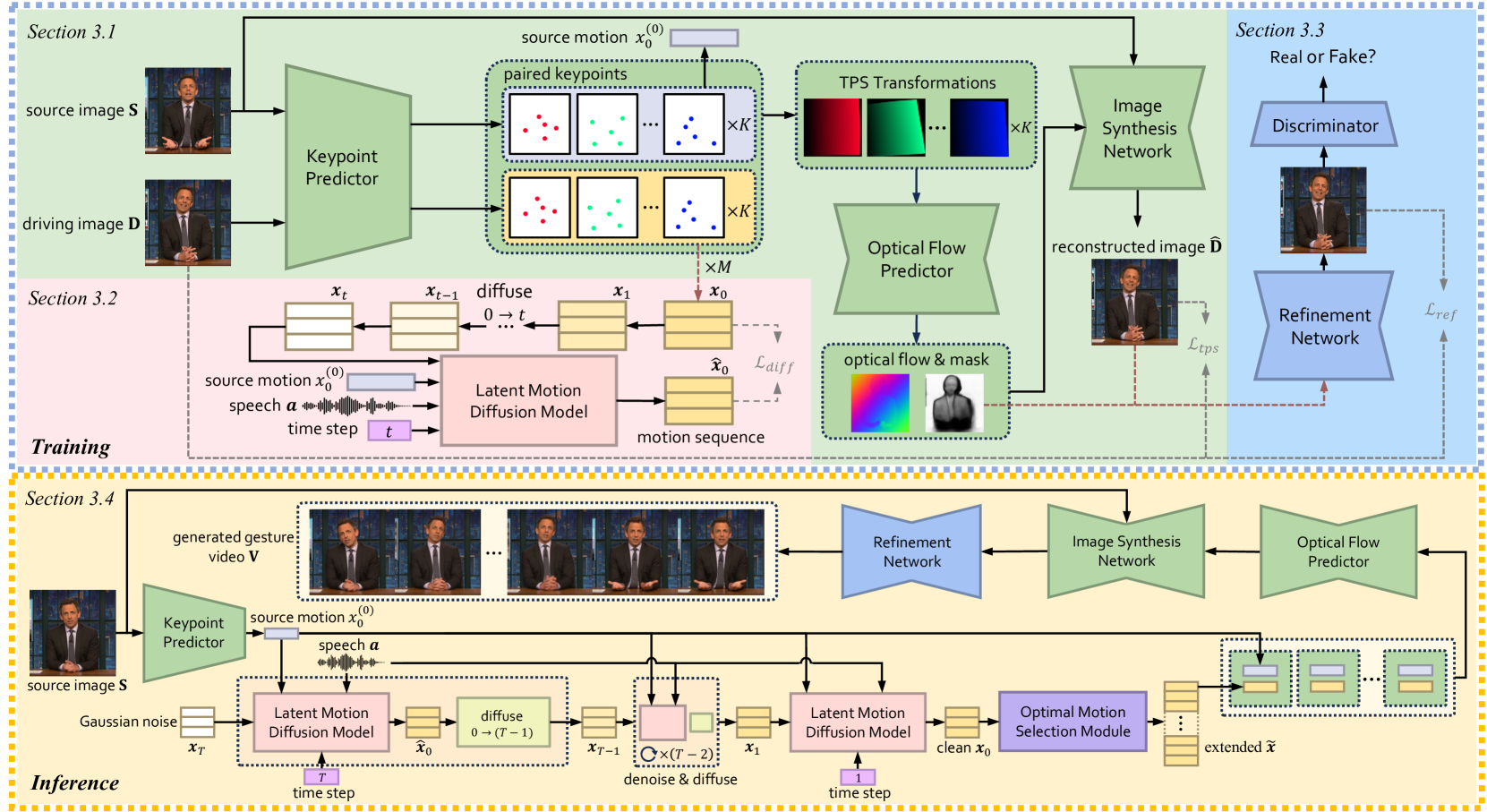
0
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Xu He, Qiaochu Huang, Zhensong Zhang, Zhiwei Lin, Zhiyong Wu, Sicheng Yang, Minglei Li, Zhiyi Chen, Songcen Xu, Xiaofei Wu
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Read more4/3/2024

0
Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis
Zeyi Zhang, Tenglong Ao, Yuyao Zhang, Qingzhe Gao, Chuan Lin, Baoquan Chen, Libin Liu
In this work, we present Semantic Gesticulator, a novel framework designed to synthesize realistic gestures accompanying speech with strong semantic correspondence. Semantically meaningful gestures are crucial for effective non-verbal communication, but such gestures often fall within the long tail of the distribution of natural human motion. The sparsity of these movements makes it challenging for deep learning-based systems, trained on moderately sized datasets, to capture the relationship between the movements and the corresponding speech semantics. To address this challenge, we develop a generative retrieval framework based on a large language model. This framework efficiently retrieves suitable semantic gesture candidates from a motion library in response to the input speech. To construct this motion library, we summarize a comprehensive list of commonly used semantic gestures based on findings in linguistics, and we collect a high-quality motion dataset encompassing both body and hand movements. We also design a novel GPT-based model with strong generalization capabilities to audio, capable of generating high-quality gestures that match the rhythm of speech. Furthermore, we propose a semantic alignment mechanism to efficiently align the retrieved semantic gestures with the GPT's output, ensuring the naturalness of the final animation. Our system demonstrates robustness in generating gestures that are rhythmically coherent and semantically explicit, as evidenced by a comprehensive collection of examples. User studies confirm the quality and human-likeness of our results, and show that our system outperforms state-of-the-art systems in terms of semantic appropriateness by a clear margin.
Read more5/20/2024