CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation

0
🤔
Sign in to get full access
Overview
- Large Language Models (LLMs) have shown impressive performance in assisting humans with programming and automating programming tasks.
- However, existing benchmarks for evaluating LLMs' code understanding and generation capabilities have significant limitations.
- These benchmarks often focus on a narrow range of programming languages and specific tasks, rather than reflecting the diverse real-world needs of software development.
- Additionally, most benchmarks fail to consider the actual executability and consistency of the generated code.
Plain English Explanation
To address these limitations, the researchers have introduced a new benchmark called CodeScope. CodeScope is an execution-based, multilingual, multitask, and multidimensional evaluation framework for comprehensively assessing LLM capabilities in coding tasks.
The benchmark covers 43 programming languages and eight different coding tasks, such as code generation, code translation, and code optimization. It evaluates the coding performance of LLMs from three perspectives: length, difficulty, and efficiency. To enable execution-based evaluations, the researchers have developed an automated code execution engine called MultiCodeEngine that supports 14 programming languages.
By using CodeScope, the researchers have systematically evaluated and analyzed eight mainstream LLMs, demonstrating the superior breadth and challenges of this new benchmark compared to other existing approaches. The goal is to provide a more comprehensive and realistic assessment of LLMs' capabilities in real-world software development scenarios.
Technical Explanation
The researchers have developed the CodeScope benchmark to address the limitations of existing benchmarks for evaluating LLMs' code understanding and generation capabilities.
CodeScope covers a wide range of programming languages (43 in total) and eight different coding tasks, including code generation, code translation, and code optimization. This broad coverage aims to better reflect the diverse requirements of real-world software development, unlike many existing benchmarks that focus on a narrow set of languages and tasks.
To ensure the code generated by LLMs is not only syntactically correct but also executable, the researchers have developed the MultiCodeEngine automated code execution engine. This engine supports 14 programming languages, allowing for a more comprehensive and realistic evaluation of the generated code's executability and consistency.
The CodeScope benchmark evaluates LLMs' coding performance from three dimensions: length, difficulty, and efficiency. This multidimensional approach provides a more nuanced assessment of LLMs' capabilities, going beyond simplistic metrics like code generation accuracy.
The researchers have systematically evaluated eight mainstream LLMs using the CodeScope benchmark and compared the results to those from other existing benchmarks. Their findings demonstrate the superior breadth and challenges of the CodeScope benchmark, highlighting its potential to better capture the real-world demands faced by LLMs in software development scenarios.
Critical Analysis
While the CodeScope benchmark represents a significant advancement in evaluating LLMs' code understanding and generation capabilities, it is important to acknowledge some potential limitations and areas for further research.
One concern is the coverage of programming languages and coding tasks. Although the benchmark covers 43 languages, there may still be a need to expand the range to include more niche or domain-specific languages used in certain industries or applications. Similarly, the eight coding tasks, while comprehensive, may not capture the full spectrum of activities required in real-world software development.
Another area for consideration is the scalability and practical applicability of the MultiCodeEngine automated code execution engine. As the number of supported languages and the complexity of coding tasks increase, ensuring the reliability and efficiency of the execution engine may become a challenge.
Additionally, while the multidimensional evaluation approach (length, difficulty, efficiency) provides a more nuanced assessment, it may be worthwhile to explore the development of composite or weighted metrics that can better capture the overall coding performance of LLMs. This could help in understanding their strengths and weaknesses across different aspects of software development.
Finally, the researchers could consider integrating the CodeScope benchmark with other proposed frameworks, such as CodemindBench or CyberSecEval-2, to create a more comprehensive and holistic evaluation suite for LLMs in the context of software engineering and cybersecurity.
Conclusion
The introduction of the CodeScope benchmark represents a significant step forward in the evaluation of LLMs' code understanding and generation capabilities. By addressing the limitations of existing benchmarks, CodeScope provides a more realistic and comprehensive assessment of LLMs' performance in diverse programming languages and coding tasks.
The development of the MultiCodeEngine automated code execution engine further enhances the benchmark's ability to evaluate the executability and consistency of the generated code, a crucial aspect for practical applications.
The systematic evaluation of eight mainstream LLMs using CodeScope has revealed the superior breadth and challenges of this new benchmark, highlighting its potential to drive the development of more capable and versatile LLMs in the field of software engineering and programming automation.
As the field of large language models continues to evolve, the CodeScope benchmark and the insights it provides will be invaluable in shaping the future of AI-powered programming assistance and automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation
Weixiang Yan, Haitian Liu, Yunkun Wang, Yunzhe Li, Qian Chen, Wen Wang, Tingyu Lin, Weishan Zhao, Li Zhu, Hari Sundaram, Shuiguang Deng
Large Language Models (LLMs) have demonstrated remarkable performance on assisting humans in programming and facilitating programming automation. However, existing benchmarks for evaluating the code understanding and generation capacities of LLMs suffer from severe limitations. First, most benchmarks are insufficient as they focus on a narrow range of popular programming languages and specific tasks, whereas real-world software development scenarios show a critical need to implement systems with multilingual and multitask programming environments to satisfy diverse requirements. Second, most benchmarks fail to consider the actual executability and the consistency of execution results of the generated code. To bridge these gaps between existing benchmarks and expectations from practical applications, we introduce CodeScope, an execution-based, multilingual, multitask, multidimensional evaluation benchmark for comprehensively measuring LLM capabilities on coding tasks. CodeScope covers 43 programming languages and eight coding tasks. It evaluates the coding performance of LLMs from three dimensions (perspectives): length, difficulty, and efficiency. To facilitate execution-based evaluations of code generation, we develop MultiCodeEngine, an automated code execution engine that supports 14 programming languages. Finally, we systematically evaluate and analyze eight mainstream LLMs and demonstrate the superior breadth and challenges of CodeScope for evaluating LLMs on code understanding and generation tasks compared to other benchmarks. The CodeScope benchmark and code are publicly available at https://github.com/WeixiangYAN/CodeScope.
Read more6/10/2024

0
Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models
Jiasheng Zheng, Boxi Cao, Zhengzhao Ma, Ruotong Pan, Hongyu Lin, Yaojie Lu, Xianpei Han, Le Sun
In recent years, researchers have proposed numerous benchmarks to evaluate the impressive coding capabilities of large language models (LLMs). However, existing benchmarks primarily focus on assessing the correctness of code generated by LLMs, while neglecting other critical dimensions that also significantly impact code quality. Therefore, this paper proposes the RACE benchmark, which comprehensively evaluates the quality of code generated by LLMs across 4 dimensions: Readability, mAintainability, Correctness, and Efficiency. Specifically, considering the demand-dependent nature of dimensions beyond correctness, we design various types of user requirements for each dimension to assess the model's ability to generate correct code that also meets user demands. We evaluate 18 representative LLMs on RACE and find that: 1) the current LLMs' ability to generate high-quality code on demand does not yet meet the requirements of software development; 2) readability serves as a critical indicator of the overall quality of generated code; 3) most LLMs exhibit an inherent preference for specific coding style. These findings can help researchers gain a deeper understanding of the coding capabilities of current LLMs and shed light on future directions for model improvement.
Read more7/17/2024

0
CRUXEval-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution
Ruiyang Xu, Jialun Cao, Yaojie Lu, Hongyu Lin, Xianpei Han, Ben He, Shing-Chi Cheung, Le Sun
Code benchmarks such as HumanEval are widely adopted to evaluate Large Language Models' (LLMs) coding capabilities. However, there is an unignorable programming language bias in existing code benchmarks -- over 95% code generation benchmarks are dominated by Python, leaving the LLMs' capabilities in other programming languages such as Java and C/C++ unknown. Moreover, coding task bias is also crucial. Most benchmarks focus on code generation capability, while benchmarks for code reasoning (given input, reasoning output; and given output, reasoning input), an essential coding capability, are insufficient. Yet, constructing multi-lingual benchmarks can be expensive and labor-intensive, and codes in contest websites such as Leetcode suffer from data contamination during training. To fill this gap, we propose CRUXEVAL-X, a multi-lingual code reasoning benchmark that contains 19 programming languages. It comprises at least 600 subjects for each language, along with 19K content-consistent tests in total. In particular, the construction pipeline of CRUXEVAL-X works in a fully automated and test-guided manner, which iteratively generates and repairs based on execution feedback. Also, to cross language barriers (e.g., dynamic/static type systems in Python/C++), we formulated various transition rules between language pairs to facilitate translation. Our intensive evaluation of 24 representative LLMs reveals the correlation between language pairs. For example, TypeScript and JavaScript show a significant positive correlation, while Racket has less correlation with other languages. More interestingly, even a model trained solely on Python can achieve at most 34.4% Pass@1 in other languages, revealing the cross-language generalization of LLMs.
Read more8/26/2024
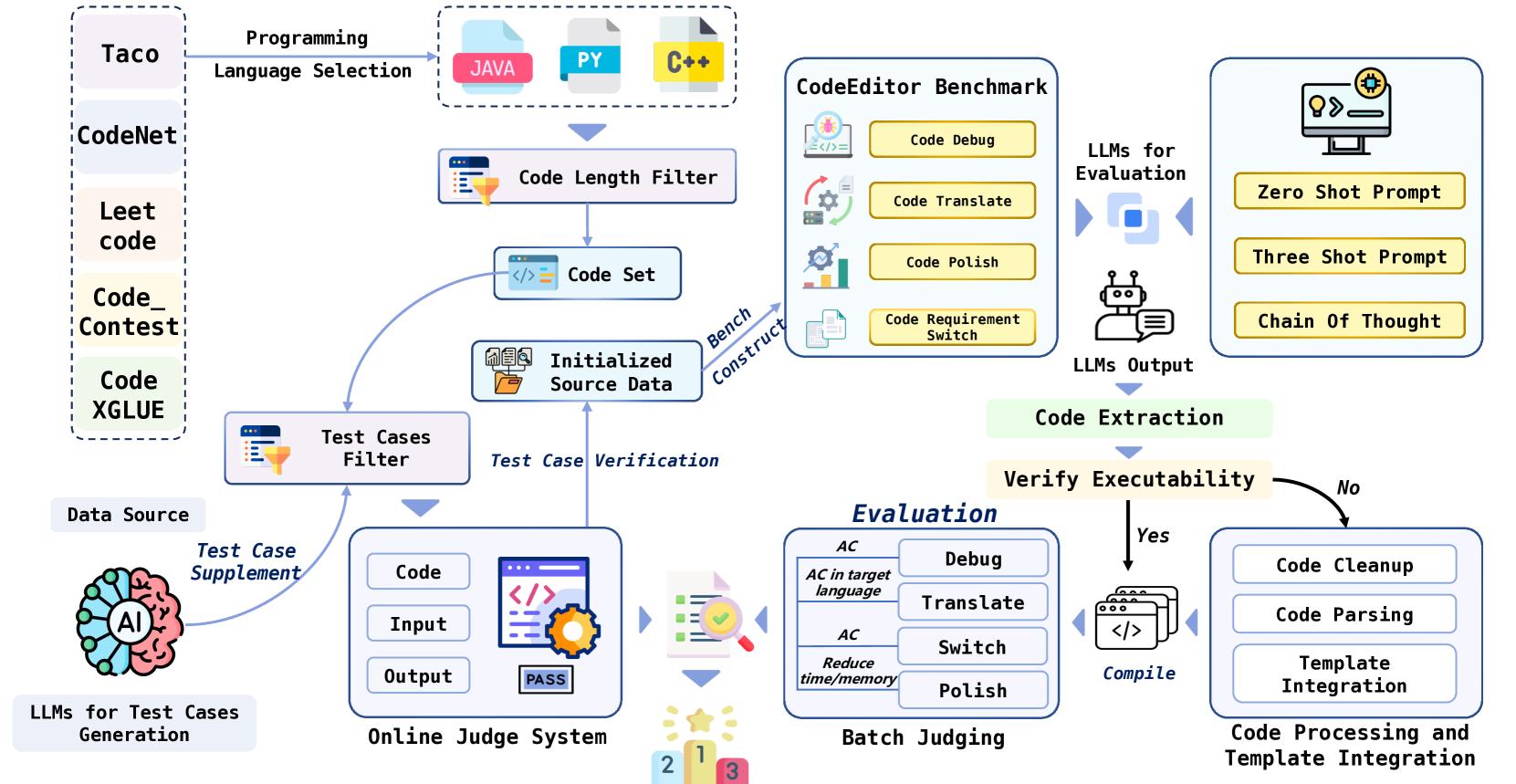
0
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Read more4/9/2024