CodeTaxo: Enhancing Taxonomy Expansion with Limited Examples via Code Language Prompts

0

Sign in to get full access
Overview
- Enhances taxonomy expansion using limited examples and code language prompts
- Proposes a novel method called "CodeTaxo" that leverages code-based language models
- Demonstrates improved performance over existing approaches for taxonomy expansion
Plain English Explanation
[object Object] is the process of adding new concepts and relationships to an existing taxonomy or category structure. This can be challenging when limited training data is available.
The researchers introduce a novel approach called [object Object] that uses code-based language models to enhance taxonomy expansion. Instead of relying solely on textual data, CodeTaxo incorporates code-related prompts and examples to guide the model in identifying new taxonomy elements.
By [object Object], the model can better understand the context and relationships within the taxonomy, leading to more accurate expansion. This is particularly useful when the available training data is limited, as the code-based prompts can provide additional information to the model.
The researchers demonstrate that CodeTaxo outperforms existing methods for taxonomy expansion, making it a promising approach for [object Object] and other applications that require taxonomic knowledge.
Technical Explanation
The paper proposes a novel method called CodeTaxo for enhancing taxonomy expansion with limited examples. The key idea is to leverage code language prompts and examples to guide the model in identifying new taxonomy elements.
The authors first define the taxonomy expansion problem, where the goal is to add new concepts and relationships to an existing taxonomy given a small set of examples. They then introduce the CodeTaxo approach, which combines textual and code-based information to address this challenge.
The CodeTaxo architecture consists of a [object Object] mechanism that allows the model to progressively refine its understanding of the taxonomy based on code-related prompts and examples. By [object Object], the model can effectively expand the taxonomy while maintaining its coherence and structure.
The researchers conduct extensive experiments to evaluate the performance of CodeTaxo on various taxonomy expansion tasks. They compare their approach to [object Object] and demonstrate significant improvements, especially when working with limited training data.
Critical Analysis
The paper presents a compelling approach to enhancing taxonomy expansion by incorporating code-based language prompts and examples. The authors clearly identify the limitations of existing methods, especially when dealing with scarce training data, and provide a novel solution to address this challenge.
One potential caveat is the reliance on the availability of code-related information, which may not always be present or easily accessible. Additionally, the performance of CodeTaxo may be influenced by the quality and relevance of the code-based prompts and examples used during training.
It would be interesting to see further research exploring the robustness of the CodeTaxo approach, such as its ability to handle noisy or diverse code-related inputs, and its generalization to different domains beyond the ones studied in the paper.
Conclusion
The CodeTaxo method proposed in this paper represents a significant advancement in the field of taxonomy expansion. By leveraging code language prompts and examples, the model can effectively expand taxonomies even with limited training data, outperforming existing approaches.
The potential implications of this research extend beyond taxonomy expansion, as the ability to [object Object] can have far-reaching applications in areas such as source code classification, knowledge management, and information retrieval.
Overall, the CodeTaxo approach demonstrates the value of integrating diverse data sources and modalities to tackle challenging problems in machine learning and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CodeTaxo: Enhancing Taxonomy Expansion with Limited Examples via Code Language Prompts
Qingkai Zeng, Yuyang Bai, Zhaoxuan Tan, Zhenyu Wu, Shangbin Feng, Meng Jiang
Taxonomies play a crucial role in various applications by providing a structural representation of knowledge. The task of taxonomy expansion involves integrating emerging concepts into existing taxonomies by identifying appropriate parent concepts for these new query concepts. Previous approaches typically relied on self-supervised methods that generate annotation data from existing taxonomies. However, these methods are less effective when the existing taxonomy is small (fewer than 100 entities). In this work, we introduce textsc{CodeTaxo}, a novel approach that leverages large language models through code language prompts to capture the taxonomic structure. Extensive experiments on five real-world benchmarks from different domains demonstrate that textsc{CodeTaxo} consistently achieves superior performance across all evaluation metrics, significantly outperforming previous state-of-the-art methods. The code and data are available at url{https://github.com/QingkaiZeng/CodeTaxo-Pub}.
Read more8/20/2024
0
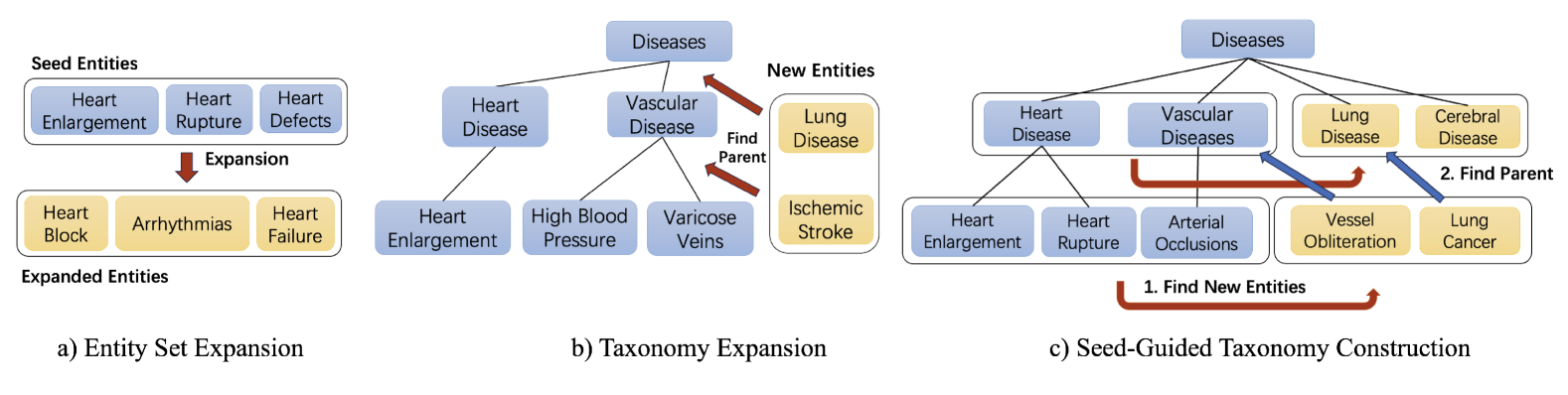
A Unified Taxonomy-Guided Instruction Tuning Framework for Entity Set Expansion and Taxonomy Expansion
Yanzhen Shen, Yu Zhang, Yunyi Zhang, Jiawei Han
Entity set expansion, taxonomy expansion, and seed-guided taxonomy construction are three representative tasks that can be applied to automatically populate an existing taxonomy with emerging concepts. Previous studies view them as three separate tasks. Therefore, their proposed techniques usually work for one specific task only, lacking generalizability and a holistic perspective. In this paper, we aim at a unified solution to the three tasks. To be specific, we identify two common skills needed for entity set expansion, taxonomy expansion, and seed-guided taxonomy construction: finding siblings and finding parents. We propose a taxonomy-guided instruction tuning framework to teach a large language model to generate siblings and parents for query entities, where the joint pre-training process facilitates the mutual enhancement of the two skills. Extensive experiments on multiple benchmark datasets demonstrate the efficacy of our proposed TaxoInstruct framework, which outperforms task-specific baselines across all three tasks.
Read more8/16/2024

0
Chain-of-Layer: Iteratively Prompting Large Language Models for Taxonomy Induction from Limited Examples
Qingkai Zeng, Yuyang Bai, Zhaoxuan Tan, Shangbin Feng, Zhenwen Liang, Zhihan Zhang, Meng Jiang
Automatic taxonomy induction is crucial for web search, recommendation systems, and question answering. Manual curation of taxonomies is expensive in terms of human effort, making automatic taxonomy construction highly desirable. In this work, we introduce Chain-of-Layer which is an in-context learning framework designed to induct taxonomies from a given set of entities. Chain-of-Layer breaks down the task into selecting relevant candidate entities in each layer and gradually building the taxonomy from top to bottom. To minimize errors, we introduce the Ensemble-based Ranking Filter to reduce the hallucinated content generated at each iteration. Through extensive experiments, we demonstrate that Chain-of-Layer achieves state-of-the-art performance on four real-world benchmarks.
Read more7/26/2024
✨
0
Taxonomy Completion with Probabilistic Scorer via Box Embedding
Wei Xue, Yongliang Shen, Wenqi Ren, Jietian Guo, Shiliang Pu, Weiming Lu
Taxonomy completion, enriching existing taxonomies by inserting new concepts as parents or attaching them as children, has gained significant interest. Previous approaches embed concepts as vectors in Euclidean space, which makes it difficult to model asymmetric relations in taxonomy. In addition, they introduce pseudo-leaves to convert attachment cases into insertion cases, leading to an incorrect bias in network learning dominated by numerous pseudo-leaves. Addressing these, our framework, TaxBox, leverages box containment and center closeness to design two specialized geometric scorers within the box embedding space. These scorers are tailored for insertion and attachment operations and can effectively capture intrinsic relationships between concepts by optimizing on a granular box constraint loss. We employ a dynamic ranking loss mechanism to balance the scores from these scorers, allowing adaptive adjustments of insertion and attachment scores. Experiments on four real-world datasets show that TaxBox significantly outperforms previous methods, yielding substantial improvements over prior methods in real-world datasets, with average performance boosts of 6.7%, 34.9%, and 51.4% in MRR, Hit@1, and Prec@1, respectively.
Read more6/19/2024