A Unified Taxonomy-Guided Instruction Tuning Framework for Entity Set Expansion and Taxonomy Expansion

0
Sign in to get full access
Overview
- This paper presents a unified framework for two related tasks: entity set expansion and taxonomy expansion.
- The framework uses a large language model (LLM) that is fine-tuned on both entity set expansion and taxonomy expansion tasks, guided by the hierarchical structure of taxonomies.
- The model learns to generate entity sets and taxonomies in a unified way, leveraging the inherent connections between the two tasks.
Plain English Explanation
The paper describes a new approach for expanding the set of entities (e.g. types of animals, professions, or products) and for expanding taxonomies (hierarchical categorizations of related entities). The key idea is to use a single large language model that is trained on both tasks in a unified way, guided by the structure of taxonomies.
Typically, these two tasks - entity set expansion and taxonomy expansion - are addressed separately. But the paper argues that they are inherently related, as the expansion of an entity set often depends on understanding its position in a taxonomy. By training a single model to handle both tasks together, the framework can leverage the connections between them to generate more accurate and comprehensive results.
The model is fine-tuned on a large corpus of existing taxonomies and entity sets. It then learns to generate new entities and expand taxonomies in a way that is consistent with the hierarchical structure and relationships it has learned. This allows the model to produce high-quality expansions that are well-grounded in real-world knowledge.
Technical Explanation
The paper introduces a Unified Taxonomy-Guided Instruction Tuning (ULTIT) framework for jointly tackling entity set expansion and taxonomy expansion tasks. The key components of the framework are:
-
Taxonomy-Guided Instruction Tuning: The large language model is fine-tuned on a diverse set of instruction tasks related to entity set expansion and taxonomy expansion. This instruction tuning is guided by the hierarchical structure of taxonomies, allowing the model to learn the inherent connections between the two tasks.
-
Unified Generation Module: The framework uses a single generation module to produce entity sets and taxonomies in a unified manner. This shared module enables the model to leverage knowledge gained from one task to improve performance on the other.
-
Iterative Refinement: The framework supports iterative refinement, where the model can refine its outputs by incorporating feedback or additional information, such as user interactions or new data sources.
The paper demonstrates the effectiveness of the ULTIT framework on a range of entity set expansion and taxonomy expansion benchmarks, including UltraWiki, QLarify, and CRAFT. The results show that the unified framework outperforms state-of-the-art approaches that tackle the two tasks separately.
Critical Analysis
The paper presents a compelling approach to jointly tackling entity set expansion and taxonomy expansion tasks. The key strengths of the ULTIT framework are its ability to leverage the inherent connections between the two tasks and its flexibility in incorporating feedback and additional information for iterative refinement.
However, the paper does not address potential limitations or caveats of the framework. For example, the performance of the model may depend on the quality and coverage of the training data, particularly the existing taxonomies and entity sets used for fine-tuning. Additionally, the framework may face challenges in handling highly specialized or rapidly evolving domains, where the available data may be limited or quickly become outdated.
Further research could explore ways to address these potential limitations, such as investigating techniques for data augmentation, active learning, or meta-learning to improve the framework's adaptability to new domains and data sources. Additionally, a deeper analysis of the model's internal representations and decision-making processes could shed light on the strengths and weaknesses of the unified approach compared to more specialized models.
Conclusion
This paper presents a novel Unified Taxonomy-Guided Instruction Tuning (ULTIT) framework that jointly tackles the tasks of entity set expansion and taxonomy expansion. By leveraging the inherent connections between these two tasks and using a single generation module guided by taxonomic structures, the framework demonstrates state-of-the-art performance on a range of benchmarks.
The unified approach offers significant advantages, as it allows the model to effectively share knowledge and insights across the two related tasks. This, in turn, can lead to more accurate and comprehensive expansions of both entity sets and taxonomies, which has important applications in fields like knowledge base construction, question answering, and information retrieval.
While the paper does not address potential limitations or caveats, the ULTIT framework represents an important step forward in the field of knowledge representation and reasoning, and its core ideas could inspire further innovations in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Unified Taxonomy-Guided Instruction Tuning Framework for Entity Set Expansion and Taxonomy Expansion
Yanzhen Shen, Yu Zhang, Yunyi Zhang, Jiawei Han
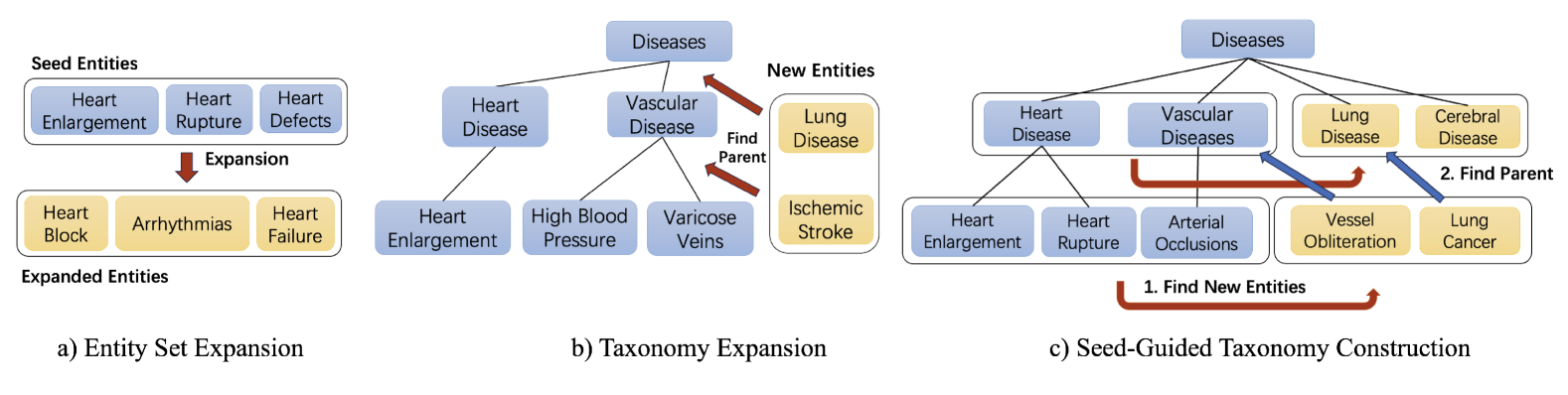
Entity set expansion, taxonomy expansion, and seed-guided taxonomy construction are three representative tasks that can be applied to automatically populate an existing taxonomy with emerging concepts. Previous studies view them as three separate tasks. Therefore, their proposed techniques usually work for one specific task only, lacking generalizability and a holistic perspective. In this paper, we aim at a unified solution to the three tasks. To be specific, we identify two common skills needed for entity set expansion, taxonomy expansion, and seed-guided taxonomy construction: finding siblings and finding parents. We propose a taxonomy-guided instruction tuning framework to teach a large language model to generate siblings and parents for query entities, where the joint pre-training process facilitates the mutual enhancement of the two skills. Extensive experiments on multiple benchmark datasets demonstrate the efficacy of our proposed TaxoInstruct framework, which outperforms task-specific baselines across all three tasks.
Read more8/16/2024

0
CodeTaxo: Enhancing Taxonomy Expansion with Limited Examples via Code Language Prompts
Qingkai Zeng, Yuyang Bai, Zhaoxuan Tan, Zhenyu Wu, Shangbin Feng, Meng Jiang
Taxonomies play a crucial role in various applications by providing a structural representation of knowledge. The task of taxonomy expansion involves integrating emerging concepts into existing taxonomies by identifying appropriate parent concepts for these new query concepts. Previous approaches typically relied on self-supervised methods that generate annotation data from existing taxonomies. However, these methods are less effective when the existing taxonomy is small (fewer than 100 entities). In this work, we introduce textsc{CodeTaxo}, a novel approach that leverages large language models through code language prompts to capture the taxonomic structure. Extensive experiments on five real-world benchmarks from different domains demonstrate that textsc{CodeTaxo} consistently achieves superior performance across all evaluation metrics, significantly outperforming previous state-of-the-art methods. The code and data are available at url{https://github.com/QingkaiZeng/CodeTaxo-Pub}.
Read more8/20/2024
✨
0
Taxonomy Completion with Probabilistic Scorer via Box Embedding
Wei Xue, Yongliang Shen, Wenqi Ren, Jietian Guo, Shiliang Pu, Weiming Lu
Taxonomy completion, enriching existing taxonomies by inserting new concepts as parents or attaching them as children, has gained significant interest. Previous approaches embed concepts as vectors in Euclidean space, which makes it difficult to model asymmetric relations in taxonomy. In addition, they introduce pseudo-leaves to convert attachment cases into insertion cases, leading to an incorrect bias in network learning dominated by numerous pseudo-leaves. Addressing these, our framework, TaxBox, leverages box containment and center closeness to design two specialized geometric scorers within the box embedding space. These scorers are tailored for insertion and attachment operations and can effectively capture intrinsic relationships between concepts by optimizing on a granular box constraint loss. We employ a dynamic ranking loss mechanism to balance the scores from these scorers, allowing adaptive adjustments of insertion and attachment scores. Experiments on four real-world datasets show that TaxBox significantly outperforms previous methods, yielding substantial improvements over prior methods in real-world datasets, with average performance boosts of 6.7%, 34.9%, and 51.4% in MRR, Hit@1, and Prec@1, respectively.
Read more6/19/2024

0
SymTax: Symbiotic Relationship and Taxonomy Fusion for Effective Citation Recommendation
Karan Goyal, Mayank Goel, Vikram Goyal, Mukesh Mohania
Citing pertinent literature is pivotal to writing and reviewing a scientific document. Existing techniques mainly focus on the local context or the global context for recommending citations but fail to consider the actual human citation behaviour. We propose SymTax, a three-stage recommendation architecture that considers both the local and the global context, and additionally the taxonomical representations of query-candidate tuples and the Symbiosis prevailing amongst them. SymTax learns to embed the infused taxonomies in the hyperbolic space and uses hyperbolic separation as a latent feature to compute query-candidate similarity. We build a novel and large dataset ArSyTa containing 8.27 million citation contexts and describe the creation process in detail. We conduct extensive experiments and ablation studies to demonstrate the effectiveness and design choice of each module in our framework. Also, combinatorial analysis from our experiments shed light on the choice of language models (LMs) and fusion embedding, and the inclusion of section heading as a signal. Our proposed module that captures the symbiotic relationship solely leads to performance gains of 26.66% and 39.25% in Recall@5 w.r.t. SOTA on ACL-200 and RefSeer datasets, respectively. The complete framework yields a gain of 22.56% in Recall@5 wrt SOTA on our proposed dataset. The code and dataset are available at https://github.com/goyalkaraniit/SymTax
Read more6/5/2024