Coding historical causes of death data with Large Language Models

0
📊
Sign in to get full access
Overview
- This paper investigates using pre-trained large language models (LLMs) to automatically assign ICD-10 codes to historical causes of death.
- ICD-10 codes are a standardized system for classifying diseases and causes of death, traditionally assigned manually by coding experts.
- The authors evaluate the performance of GPT-3.5, GPT-4, and Llama 2 LLMs on the HiCaD dataset, which contains over 19,000 historical causes of death.
- The findings show that LLMs can achieve reasonable accuracy, but standard machine learning techniques still outperform them for this task.
Plain English Explanation
The paper explores using advanced AI language models to automatically categorize historical causes of death. Causes of death are often recorded in complex, narrative form, making them difficult to classify.
The researchers tested three powerful language models - GPT-3.5, GPT-4, and Llama 2 - on a dataset of over 19,000 historical causes of death. These models are trained on vast amounts of text data and can generate human-like language. The goal was to see if they could accurately assign standardized ICD-10 medical codes to the causes of death.
The results were mixed. The language models were able to correctly code between 40-83% of the causes, depending on the model. However, traditional machine learning techniques achieved even higher accuracy at 89%.
The language models performed better on causes that used common medical terms, compared to older, more obscure language. They also did better on short, simple causes versus longer, more complex ones.
Overall, while the language models showed promise, they still struggle to match human experts for this specialized task of historical cause of death coding. The researchers suggest further training or different approaches may be needed to truly automate this process.
Technical Explanation
The paper evaluates the feasibility of using large language models (LLMs) to automate the assignment of ICD-10 codes to historical causes of death. ICD-10 is a standardized system for classifying diseases and causes of mortality, traditionally assigned manually by coding experts.
The authors tested three prominent LLMs - GPT-3.5, GPT-4, and Llama 2 - on the HiCaD dataset, which contains over 19,000 historical causes of death recorded in civil death registers in the UK between 1861-1901. These causes often contain complex, narrative language that makes manual coding challenging.
The results showed that the LLMs could achieve reasonably high accuracy, correctly coding 69%, 83%, and 40% of causes for GPT-3.5, GPT-4, and Llama 2 respectively. However, the authors found that standard machine learning techniques could achieve even higher accuracy at 89%.
Further analysis revealed that the LLMs performed better on causes containing terms still in common medical use, compared to more archaic language. They also did better on short, simple causes versus longer, more complex ones.
Overall, the findings indicate that while LLMs show promise, they do not currently perform well enough to fully automate the historical ICD-10 coding task. The authors suggest further fine-tuning or alternative frameworks may be needed to reach adequate performance levels.
Critical Analysis
The paper provides a thorough evaluation of using LLMs to assist with medical coding tasks, which is an important step towards automating laborious manual processes. However, the authors acknowledge several limitations and areas for further research.
One key limitation is the narrow scope of the dataset, which only includes historical causes of death from three UK regions. Expanding the evaluation to a broader, more diverse set of medical narratives would be helpful to assess the generalizability of the findings.
Additionally, the authors do not explore the potential benefits of combining LLMs with other techniques, such as structured knowledge bases or ensembles of machine learning models. Such hybrid approaches may be able to achieve higher accuracy than any single method alone.
It would also be worthwhile to investigate the interpretability and explainability of the LLM coding decisions. Understanding the reasoning behind the model's outputs could aid in building trust and acceptance for this type of AI-assisted medical coding.
Overall, this paper represents an important step in advancing our understanding of LLM capabilities for specialized medical tasks. However, further research is needed to fully realize the potential of these models in real-world healthcare applications.
Conclusion
This paper explores the use of pre-trained large language models (LLMs) to automate the assignment of ICD-10 codes to historical causes of death. While the tested LLMs (GPT-3.5, GPT-4, and Llama 2) demonstrated reasonable performance, standard machine learning techniques still outperformed them for this task.
The findings suggest that LLMs struggle with the complex, narrative nature of historical causes of death, particularly when they contain archaic medical terminology. However, the models performed better on short causes using common medical terms, indicating they may have potential for certain coding applications.
Overall, this research highlights the need for further advancements in LLM capabilities, potentially through fine-tuning or hybrid approaches, to reliably automate the complex task of historical medical coding. As AI language models continue to evolve, they may become increasingly valuable tools for streamlining medical documentation and improving healthcare efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Coding historical causes of death data with Large Language Models
Bj{o}rn Pedersen, Maisha Islam, Doris Tove Kristoffersen, Lars Ailo Bongo, Eilidh Garrett, Alice Reid, Hilde Sommerseth
This paper investigates the feasibility of using pre-trained generative Large Language Models (LLMs) to automate the assignment of ICD-10 codes to historical causes of death. Due to the complex narratives often found in historical causes of death, this task has traditionally been manually performed by coding experts. We evaluate the ability of GPT-3.5, GPT-4, and Llama 2 LLMs to accurately assign ICD-10 codes on the HiCaD dataset that contains causes of death recorded in the civil death register entries of 19,361 individuals from Ipswich, Kilmarnock, and the Isle of Skye from the UK between 1861-1901. Our findings show that GPT-3.5, GPT-4, and Llama 2 assign the correct code for 69%, 83%, and 40% of causes, respectively. However, we achieve a maximum accuracy of 89% by standard machine learning techniques. All LLMs performed better for causes of death that contained terms still in use today, compared to archaic terms. Also they perform better for short causes (1-2 words) compared to longer causes. LLMs therefore do not currently perform well enough for historical ICD-10 code assignment tasks. We suggest further fine-tuning or alternative frameworks to achieve adequate performance.
Read more5/14/2024

0
Can Large Language Models abstract Medical Coded Language?
Simon A. Lee, Timothy Lindsey
Large Language Models (LLMs) have become a pivotal research area, potentially making beneficial contributions in fields like healthcare where they can streamline automated billing and decision support. However, the frequent use of specialized coded languages like ICD-10, which are regularly updated and deviate from natural language formats, presents potential challenges for LLMs in creating accurate and meaningful latent representations. This raises concerns among healthcare professionals about potential inaccuracies or ``hallucinations that could result in the direct impact of a patient. Therefore, this study evaluates whether large language models (LLMs) are aware of medical code ontologies and can accurately generate names from these codes. We assess the capabilities and limitations of both general and biomedical-specific generative models, such as GPT, LLaMA-2, and Meditron, focusing on their proficiency with domain-specific terminologies. While the results indicate that LLMs struggle with coded language, we offer insights on how to adapt these models to reason more effectively.
Read more6/10/2024
💬
0
Large language models are good medical coders, if provided with tools
Keith Kwan
This study presents a novel two-stage Retrieve-Rank system for automated ICD-10-CM medical coding, comparing its performance against a Vanilla Large Language Model (LLM) approach. Evaluating both systems on a dataset of 100 single-term medical conditions, the Retrieve-Rank system achieved 100% accuracy in predicting correct ICD-10-CM codes, significantly outperforming the Vanilla LLM (GPT-3.5-turbo), which achieved only 6% accuracy. Our analysis demonstrates the Retrieve-Rank system's superior precision in handling various medical terms across different specialties. While these results are promising, we acknowledge the limitations of using simplified inputs and the need for further testing on more complex, realistic medical cases. This research contributes to the ongoing effort to improve the efficiency and accuracy of medical coding, highlighting the importance of retrieval-based approaches.
Read more7/19/2024
0
Causality extraction from medical text using Large Language Models (LLMs)
Seethalakshmi Gopalakrishnan, Luciana Garbayo, Wlodek Zadrozny
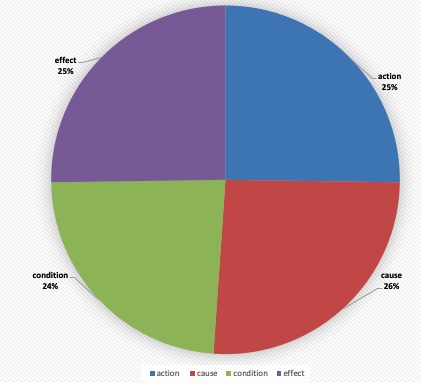
This study explores the potential of natural language models, including large language models, to extract causal relations from medical texts, specifically from Clinical Practice Guidelines (CPGs). The outcomes causality extraction from Clinical Practice Guidelines for gestational diabetes are presented, marking a first in the field. We report on a set of experiments using variants of BERT (BioBERT, DistilBERT, and BERT) and using Large Language Models (LLMs), namely GPT-4 and LLAMA2. Our experiments show that BioBERT performed better than other models, including the Large Language Models, with an average F1-score of 0.72. GPT-4 and LLAMA2 results show similar performance but less consistency. We also release the code and an annotated a corpus of causal statements within the Clinical Practice Guidelines for gestational diabetes.
Read more7/16/2024