FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment

0
Sign in to get full access
Overview
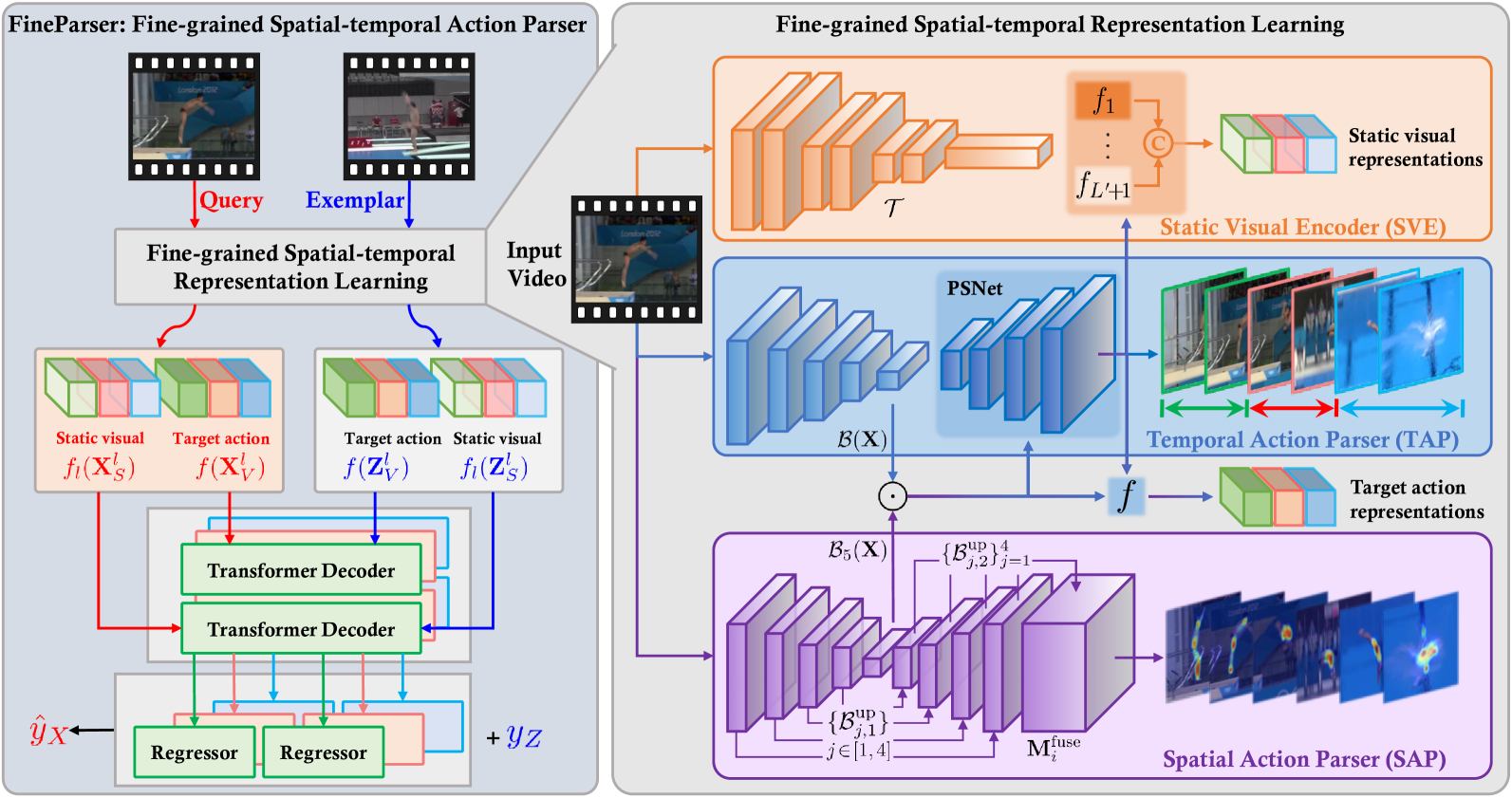
- The paper proposes a fine-grained spatio-temporal action parser called FineParser for human-centric action quality assessment.
- FineParser aims to capture the nuanced details of human actions by parsing action sequences into fine-grained spatial and temporal components.
- This allows for a more comprehensive evaluation of action quality, which is important for applications like sports training and rehabilitation.
Plain English Explanation
FineParser is a tool that can analyze and break down human actions in great detail. It looks at not just the overall action, but the specific movements and timing that make up that action. This allows for a more thorough assessment of the quality of the action.
For example, say you're observing someone practicing a tennis swing. FineParser could analyze the positioning of their body, the speed and timing of their arm movements, the coordination of their steps, and other fine details. This provides a much richer understanding of the quality of their swing compared to just looking at the overall motion.
The ability to assess action quality in this granular way is valuable for applications like sports training, rehabilitation exercises, and other human-centric activities where mastering the subtle nuances of a movement is important. FineParser aims to enable this level of detailed analysis.
Technical Explanation
The key innovation of FineParser is its ability to parse action sequences into fine-grained spatial and temporal components. Rather than just considering the action as a whole, FineParser breaks it down into detailed sub-actions and their timing.
To achieve this, the system uses a multi-stage neural network architecture. First, it extracts visual and skeletal features from input video data. These features are then fed into a series of modules that progressively refine the spatial and temporal understanding of the action.
The final output of FineParser is a structured representation of the action that captures things like the position and movement of individual body parts over time. This rich description enables a more comprehensive assessment of action quality compared to simpler holistic approaches.
The authors evaluate FineParser on several human-centric action datasets and demonstrate its superior performance for tasks like action quality scoring and fine-grained action recognition. The system is shown to outperform prior state-of-the-art methods, highlighting the value of its fine-grained spatio-temporal analysis.
Critical Analysis
The key strength of FineParser is its ability to deeply analyze the nuanced details of human actions, which is crucial for applications like sports training and rehabilitation. By parsing actions into their fine-grained spatial and temporal components, the system provides a much richer understanding compared to previous approaches.
That said, the complexity of the FineParser architecture may limit its practical deployment, as the multi-stage neural network could be computationally intensive. Additionally, the reliance on detailed skeletal and visual features means the system may struggle with lower-quality or occluded input data.
Further research could explore ways to streamline the FineParser architecture without sacrificing its core fine-grained analysis capabilities. Investigating its robustness to noisy or partial input data would also be valuable. Additionally, exploring applications beyond action quality assessment, such as human-robot interaction or virtual reality training, could uncover new use cases for this technology.
Conclusion
The FineParser system represents an important advance in human-centric action analysis by enabling fine-grained spatio-temporal parsing of actions. This granular understanding of movements and their timing is crucial for applications where mastering subtle action details is essential, such as sports training, rehabilitation, and human-robot interaction.
While there are some practical challenges to address, the core capabilities of FineParser demonstrate the value of moving beyond coarse-grained action recognition towards a more comprehensive, nuanced analysis of human behavior. As this field continues to evolve, tools like FineParser will play an increasingly important role in unlocking new applications and insights.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment
Jinglin Xu, Sibo Yin, Guohao Zhao, Zishuo Wang, Yuxin Peng
Existing action quality assessment (AQA) methods mainly learn deep representations at the video level for scoring diverse actions. Due to the lack of a fine-grained understanding of actions in videos, they harshly suffer from low credibility and interpretability, thus insufficient for stringent applications, such as Olympic diving events. We argue that a fine-grained understanding of actions requires the model to perceive and parse actions in both time and space, which is also the key to the credibility and interpretability of the AQA technique. Based on this insight, we propose a new fine-grained spatial-temporal action parser named textbf{FineParser}. It learns human-centric foreground action representations by focusing on target action regions within each frame and exploiting their fine-grained alignments in time and space to minimize the impact of invalid backgrounds during the assessment. In addition, we construct fine-grained annotations of human-centric foreground action masks for the FineDiving dataset, called textbf{FineDiving-HM}. With refined annotations on diverse target action procedures, FineDiving-HM can promote the development of real-world AQA systems. Through extensive experiments, we demonstrate the effectiveness of FineParser, which outperforms state-of-the-art methods while supporting more tasks of fine-grained action understanding. Data and code are available at url{https://github.com/PKU-ICST-MIPL/FineParser_CVPR2024}.
Read more5/14/2024
0
CoFInAl: Enhancing Action Quality Assessment with Coarse-to-Fine Instruction Alignment
Kanglei Zhou, Junlin Li, Ruizhi Cai, Liyuan Wang, Xingxing Zhang, Xiaohui Liang
Action Quality Assessment (AQA) is pivotal for quantifying actions across domains like sports and medical care. Existing methods often rely on pre-trained backbones from large-scale action recognition datasets to boost performance on smaller AQA datasets. However, this common strategy yields suboptimal results due to the inherent struggle of these backbones to capture the subtle cues essential for AQA. Moreover, fine-tuning on smaller datasets risks overfitting. To address these issues, we propose Coarse-to-Fine Instruction Alignment (CoFInAl). Inspired by recent advances in large language model tuning, CoFInAl aligns AQA with broader pre-trained tasks by reformulating it as a coarse-to-fine classification task. Initially, it learns grade prototypes for coarse assessment and then utilizes fixed sub-grade prototypes for fine-grained assessment. This hierarchical approach mirrors the judging process, enhancing interpretability within the AQA framework. Experimental results on two long-term AQA datasets demonstrate CoFInAl achieves state-of-the-art performance with significant correlation gains of 5.49% and 3.55% on Rhythmic Gymnastics and Fis-V, respectively. Our code is available at https://github.com/ZhouKanglei/CoFInAl_AQA.
Read more4/23/2024

0
FinePseudo: Improving Pseudo-Labelling through Temporal-Alignablity for Semi-Supervised Fine-Grained Action Recognition
Ishan Rajendrakumar Dave, Mamshad Nayeem Rizve, Mubarak Shah
Real-life applications of action recognition often require a fine-grained understanding of subtle movements, e.g., in sports analytics, user interactions in AR/VR, and surgical videos. Although fine-grained actions are more costly to annotate, existing semi-supervised action recognition has mainly focused on coarse-grained action recognition. Since fine-grained actions are more challenging due to the absence of scene bias, classifying these actions requires an understanding of action-phases. Hence, existing coarse-grained semi-supervised methods do not work effectively. In this work, we for the first time thoroughly investigate semi-supervised fine-grained action recognition (FGAR). We observe that alignment distances like dynamic time warping (DTW) provide a suitable action-phase-aware measure for comparing fine-grained actions, a concept previously unexploited in FGAR. However, since regular DTW distance is pairwise and assumes strict alignment between pairs, it is not directly suitable for classifying fine-grained actions. To utilize such alignment distances in a limited-label setting, we propose an Alignability-Verification-based Metric learning technique to effectively discriminate between fine-grained action pairs. Our learnable alignability score provides a better phase-aware measure, which we use to refine the pseudo-labels of the primary video encoder. Our collaborative pseudo-labeling-based framework `textit{FinePseudo}' significantly outperforms prior methods on four fine-grained action recognition datasets: Diving48, FineGym99, FineGym288, and FineDiving, and shows improvement on existing coarse-grained datasets: Kinetics400 and Something-SomethingV2. We also demonstrate the robustness of our collaborative pseudo-labeling in handling novel unlabeled classes in open-world semi-supervised setups. Project Page: https://daveishan.github.io/finepsuedo-webpage/.
Read more9/4/2024

0
Hierarchical NeuroSymbolic Approach for Comprehensive and Explainable Action Quality Assessment
Lauren Okamoto, Paritosh Parmar
Action quality assessment (AQA) applies computer vision to quantitatively assess the performance or execution of a human action. Current AQA approaches are end-to-end neural models, which lack transparency and tend to be biased because they are trained on subjective human judgements as ground-truth. To address these issues, we introduce a neuro-symbolic paradigm for AQA, which uses neural networks to abstract interpretable symbols from video data and makes quality assessments by applying rules to those symbols. We take diving as the case study. We found that domain experts prefer our system and find it more informative than purely neural approaches to AQA in diving. Our system also achieves state-of-the-art action recognition and temporal segmentation, and automatically generates a detailed report that breaks the dive down into its elements and provides objective scoring with visual evidence. As verified by a group of domain experts, this report may be used to assist judges in scoring, help train judges, and provide feedback to divers. Annotated training data and code: https://github.com/laurenok24/NSAQA.
Read more5/27/2024