Cognitive Visual-Language Mapper: Advancing Multimodal Comprehension with Enhanced Visual Knowledge Alignment
2402.13561
0
0

Abstract
Evaluating and Rethinking the current landscape of Large Multimodal Models (LMMs), we observe that widely-used visual-language projection approaches (e.g., Q-former or MLP) focus on the alignment of image-text descriptions yet ignore the visual knowledge-dimension alignment, i.e., connecting visuals to their relevant knowledge. Visual knowledge plays a significant role in analyzing, inferring, and interpreting information from visuals, helping improve the accuracy of answers to knowledge-based visual questions. In this paper, we mainly explore improving LMMs with visual-language knowledge alignment, especially aimed at challenging knowledge-based visual question answering (VQA). To this end, we present a Cognitive Visual-Language Mapper (CVLM), which contains a pretrained Visual Knowledge Aligner (VKA) and a Fine-grained Knowledge Adapter (FKA) used in the multimodal instruction tuning stage. Specifically, we design the VKA based on the interaction between a small language model and a visual encoder, training it on collected image-knowledge pairs to achieve visual knowledge acquisition and projection. FKA is employed to distill the fine-grained visual knowledge of an image and inject it into Large Language Models (LLMs). We conduct extensive experiments on knowledge-based VQA benchmarks and experimental results show that CVLM significantly improves the performance of LMMs on knowledge-based VQA (average gain by 5.0%). Ablation studies also verify the effectiveness of VKA and FKA, respectively. The codes are available at https://github.com/HITsz-TMG/Cognitive-Visual-Language-Mapper
Create account to get full access
Overview
- The paper proposes a Cognitive Visual-Language Mapper (CVLM) model to enhance multimodal comprehension by aligning visual knowledge with language understanding.
- The CVLM model aims to bridge the gap between vision and language processing, allowing for more effective reasoning and inference across modalities.
- The research explores techniques for improving visual knowledge alignment to enhance the performance of multimodal tasks like visual question answering.
Plain English Explanation
The paper introduces a new model called the Cognitive Visual-Language Mapper (CVLM) that aims to improve how AI systems understand and reason with information from both visual and language inputs. Current AI models can struggle to fully connect what they see in images with the meaning of words and language, limiting their ability to answer questions or make inferences that require integrating these two modalities.
The CVLM model seeks to address this by finding better ways to align the visual information an AI system processes with the language understanding it develops. This allows the model to more effectively reason across both visual and language inputs, leading to better performance on tasks like visual question answering where questions need to be answered based on both the image and accompanying text.
The authors explore different techniques to enhance this visual-language alignment, drawing inspiration from how the human brain processes and integrates information from sight and language. By improving this alignment, the CVLM model can build a more holistic understanding that bridges the gap between vision and language, as seen in other recent work on multimodal AI.
Technical Explanation
The core of the CVLM model is a neural network architecture that learns to align visual and language representations. It takes in both an image and a language input (e.g. a question about the image) and produces an integrated understanding that can be used for downstream tasks.
The model consists of several key components:
- Visual Encoder: A convolutional neural network that encodes the input image into a visual feature representation.
- Language Encoder: A transformer-based language model that encodes the input text (e.g. a question) into a language feature representation.
- Cognitive Mapper: A module that learns to map between the visual and language feature spaces, aligning them through cross-attention mechanisms.
- Task-Specific Head: A final layer tailored to the specific task, such as generating an answer for a visual question.
The training process encourages the model to discover meaningful connections between the visual and language representations, building an integrated understanding that can be leveraged for tasks like visual question answering or knowledge-based reasoning about visual inputs.
The authors evaluate the CVLM model on several benchmark datasets, demonstrating improved performance compared to prior state-of-the-art approaches. The results highlight the benefits of enhanced visual-language alignment for advancing multimodal comprehension.
Critical Analysis
The paper presents a compelling approach to improving multimodal AI systems, but there are a few potential limitations and areas for further research:
-
Scalability and Generalization: While the CVLM model shows strong performance on the evaluated benchmarks, it remains to be seen how well the approach scales to larger, more diverse datasets and real-world applications. Additional research is needed to assess the model's ability to generalize beyond the specific training scenarios.
-
Interpretability and Explainability: As with many deep learning models, the inner workings of the CVLM can be opaque, making it difficult to understand how the visual-language alignment is achieved and why certain decisions are made. Developing more interpretable and explainable approaches could enhance trust and enable better debugging and refinement of the model.
-
Multimodal Reasoning and Grounding: The paper focuses primarily on aligning visual and language representations, but further work is needed to explore how the CVLM can be leveraged for deeper multimodal reasoning, such as grounding language in visual concepts or reasoning about complex relationships between visual and linguistic elements.
-
Biases and Societal Impacts: As with any AI system, it is important to carefully examine the CVLM model for potential biases and consider the societal implications of its deployment, especially in high-stakes domains like healthcare or education.
Overall, the Cognitive Visual-Language Mapper represents an important step forward in bridging the gap between vision and language processing, and the insights from this research can inform the development of more robust and capable multimodal AI systems.
Conclusion
The Cognitive Visual-Language Mapper (CVLM) proposed in this paper aims to enhance multimodal comprehension by better aligning visual knowledge with language understanding. By developing techniques to map between visual and language representations, the CVLM model can more effectively reason across these modalities, leading to improved performance on tasks like visual question answering.
The research highlights the potential benefits of closer integration between vision and language processing, paving the way for more advanced multimodal AI systems that can fluidly combine information from different sensory inputs. As the field of multimodal AI continues to evolve, the insights and approaches presented in this work can contribute to the development of AI agents that can more holistically understand and interact with the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
KNVQA: A Benchmark for evaluation knowledge-based VQA
Sirui Cheng, Siyu Zhang, Jiayi Wu, Muchen Lan
0
0
Within the multimodal field, large vision-language models (LVLMs) have made significant progress due to their strong perception and reasoning capabilities in the visual and language systems. However, LVLMs are still plagued by the two critical issues of object hallucination and factual accuracy, which limit the practicality of LVLMs in different scenarios. Furthermore, previous evaluation methods focus more on the comprehension and reasoning of language content but lack a comprehensive evaluation of multimodal interactions, thereby resulting in potential limitations. To this end, we propose a novel KNVQA-Eval, which is devoted to knowledge-based VQA task evaluation to reflect the factuality of multimodal LVLMs. To ensure the robustness and scalability of the evaluation, we develop a new KNVQA dataset by incorporating human judgment and perception, aiming to evaluate the accuracy of standard answers relative to AI-generated answers in knowledge-based VQA. This work not only comprehensively evaluates the contextual information of LVLMs using reliable human annotations, but also further analyzes the fine-grained capabilities of current methods to reveal potential avenues for subsequent optimization of LVLMs-based estimators. Our proposed VQA-Eval and corresponding dataset KNVQA will facilitate the development of automatic evaluation tools with the advantages of low cost, privacy protection, and reproducibility. Our code will be released upon publication.
6/14/2024
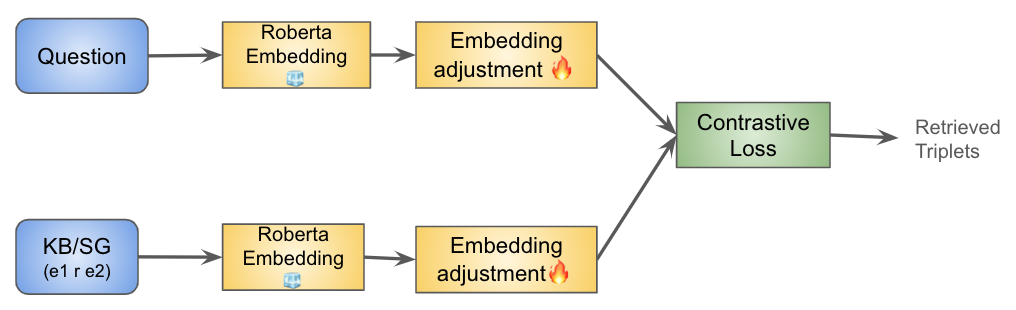
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024
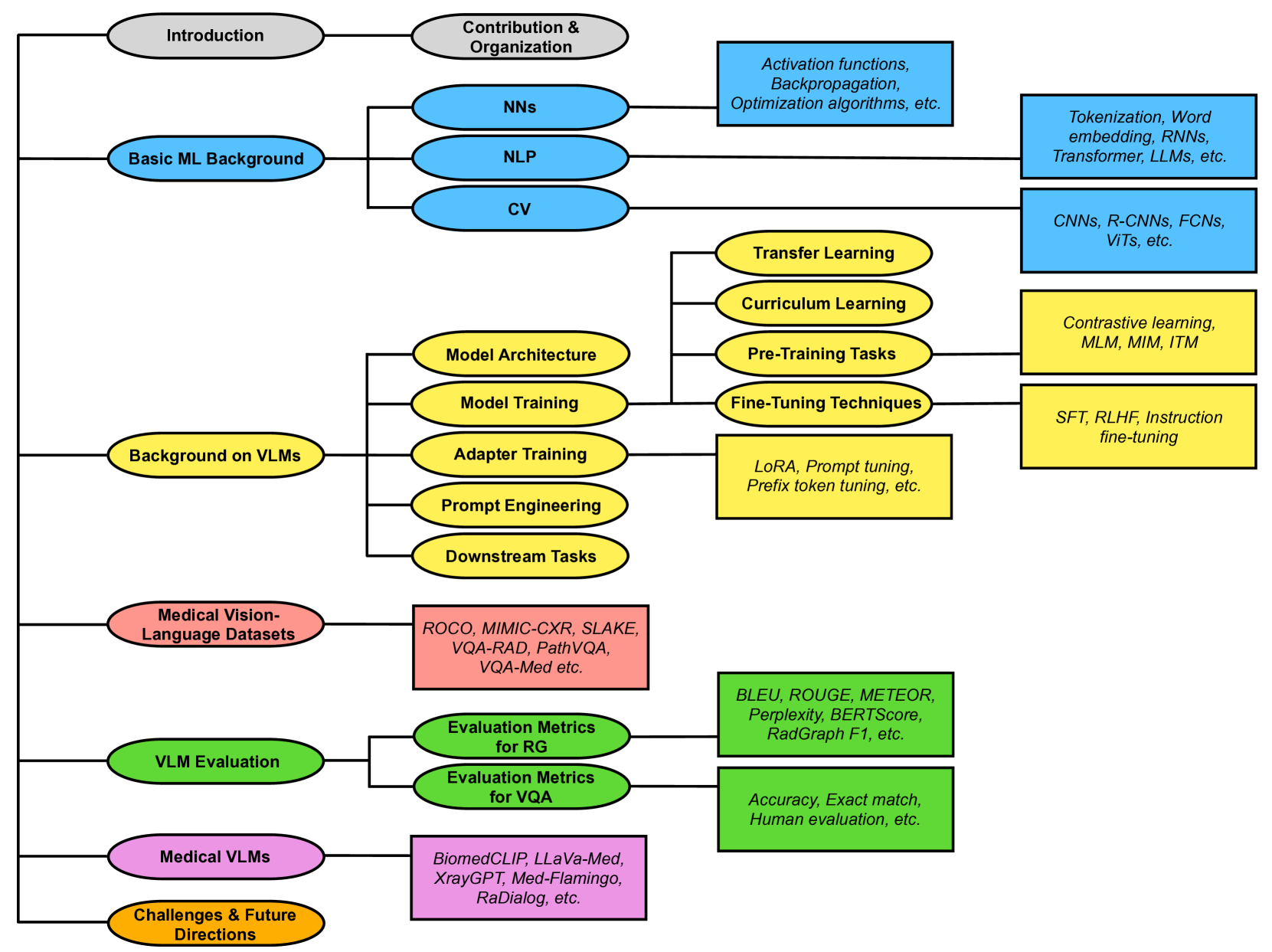
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
0
0
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
4/16/2024

Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
0
0
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
6/17/2024