Coherent 3D Portrait Video Reconstruction via Triplane Fusion
2405.00794
0
0

Abstract
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, potentially democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a personalized 3D prior, but fail to faithfully reconstruct the user's per-frame appearance (e.g., facial expressions and lighting). In this work, we recognize the need to maintain both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that fuses a personalized 3D subject prior with per-frame information, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearances. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction accuracy and temporal consistency on in-studio and in-the-wild datasets.
Create account to get full access
Overview
- This paper presents a novel approach for reconstructing coherent 3D portrait video from monocular input.
- The method uses a triplane representation, which combines multiple 2D feature planes to capture the 3D geometry and appearance of the portrait.
- The authors introduce a neural rendering pipeline that can generate high-fidelity, temporally coherent 3D portrait videos from a single input video.
Plain English Explanation
The paper describes a new way to create 3D video of a person's face and head from a regular 2D video. Typically, creating 3D video is challenging because it requires complex multi-camera setups or specialized hardware. However, this new method can do it using just a single video camera.
The key idea is to represent the 3D face and head using three 2D "feature planes" that capture different aspects of the 3D shape and appearance. By combining these three planes, the system can reconstruct a detailed 3D model of the subject that changes over time to match the input video. [This relates to the concept of tri-plane 3D representation used in other 3D reconstruction research.]
The authors developed a neural network-based pipeline that can take a normal 2D video as input and automatically generate the corresponding high-quality 3D video output. This allows for applications like 3D face re-enactment, dynamic 3D scene reconstruction, and real-time 3D portrait editing.
Technical Explanation
The paper proposes a method for reconstructing coherent 3D portrait video from a monocular input video. The key technical innovation is the use of a triplane representation, which combines three 2D feature planes to capture the 3D geometry and appearance of the subject's head and face.
The first plane encodes the 3D shape of the face, the second plane captures detailed facial details and texture, and the third plane represents dynamic expressions and head movements over time. By fusing these complementary 2D planes, the system can generate a high-fidelity 3D portrait model that evolves seamlessly with the input video.
The authors introduce a neural rendering pipeline that takes the triplane representation as input and outputs the final 3D portrait video. This pipeline includes components for predicting the triplane features, rendering the 3D face and head, and ensuring temporal coherence between frames. [This relates to work on high-fidelity talking portrait synthesis.]
Experiments demonstrate that the proposed method outperforms prior 3D portrait reconstruction techniques on a variety of metrics, including visual quality, temporal stability, and reconstruction accuracy.
Critical Analysis
The paper presents a compelling approach for 3D portrait video reconstruction that addresses several limitations of existing methods. By using the triplane representation, the system can capture the complex 3D geometry and appearance of the human face and head in a more effective manner than previous techniques.
However, the authors acknowledge that their method has some limitations. For example, it may struggle with extreme head poses or occlusions that are not well represented in the training data. Additionally, the computational complexity of the neural rendering pipeline could be a challenge for real-time applications.
Further research could explore ways to make the system more robust to a wider range of facial expressions and head movements, as well as investigate methods for improving the efficiency of the rendering process. Incorporating additional sensor data, such as depth information or multi-view video, could also be a promising direction to enhance the 3D reconstruction quality.
Overall, this paper represents an important step forward in the field of 3D portrait video reconstruction, with the triplane fusion approach offering a novel and effective solution to a challenging computer vision problem.
Conclusion
The Coherent 3D Portrait Video Reconstruction via Triplane Fusion paper introduces a novel neural rendering pipeline that can generate high-quality 3D portrait videos from monocular input. By representing the 3D face and head using a triplane feature fusion approach, the system can capture the complex geometry and appearance of the human face in a temporally coherent manner.
This work has significant implications for a range of applications, including 3D face re-enactment, dynamic 3D scene reconstruction, and real-time 3D portrait editing. While the method has some limitations, the authors' innovative triplane representation and neural rendering techniques represent an important advancement in the field of 3D portrait video reconstruction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
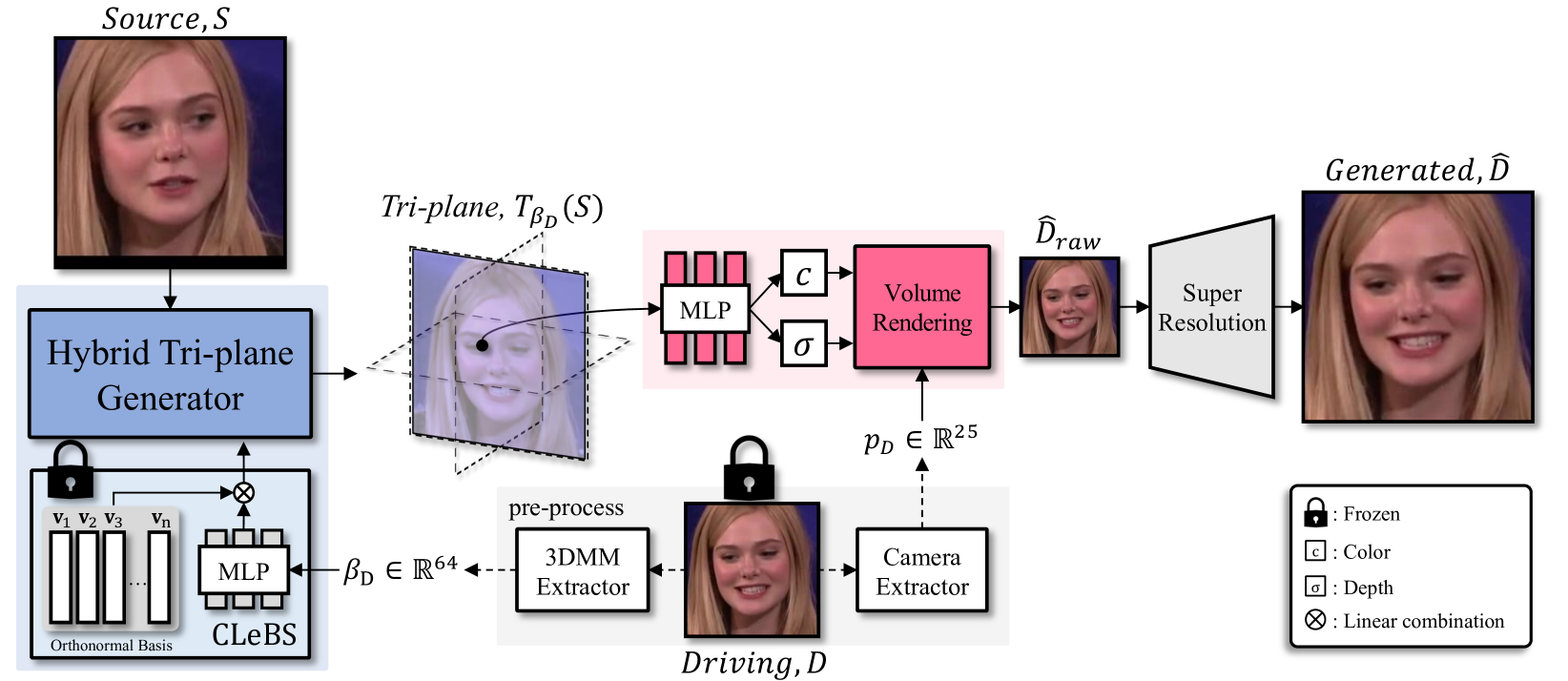
Learning to Generate Conditional Tri-plane for 3D-aware Expression Controllable Portrait Animation
Taekyung Ki, Dongchan Min, Gyeongsu Chae
0
0
In this paper, we present Export3D, a one-shot 3D-aware portrait animation method that is able to control the facial expression and camera view of a given portrait image. To achieve this, we introduce a tri-plane generator that directly generates a tri-plane of 3D prior by transferring the expression parameter of 3DMM into the source image. The tri-plane is then decoded into the image of different view through a differentiable volume rendering. Existing portrait animation methods heavily rely on image warping to transfer the expression in the motion space, challenging on disentanglement of appearance and expression. In contrast, we propose a contrastive pre-training framework for appearance-free expression parameter, eliminating undesirable appearance swap when transferring a cross-identity expression. Extensive experiments show that our pre-training framework can learn the appearance-free expression representation hidden in 3DMM, and our model can generate 3D-aware expression controllable portrait image without appearance swap in the cross-identity manner.
4/3/2024
⚙️
3DFlowRenderer: One-shot Face Re-enactment via Dense 3D Facial Flow Estimation
Siddharth Nijhawan, Takuya Yashima, Tamaki Kojima
0
0
Performing facial expression transfer under one-shot setting has been increasing in popularity among research community with a focus on precise control of expressions. Existing techniques showcase compelling results in perceiving expressions, but they lack robustness with extreme head poses. They also struggle to accurately reconstruct background details, thus hindering the realism. In this paper, we propose a novel warping technology which integrates the advantages of both 2D and 3D methods to achieve robust face re-enactment. We generate dense 3D facial flow fields in feature space to warp an input image based on target expressions without depth information. This enables explicit 3D geometric control for re-enacting misaligned source and target faces. We regularize the motion estimation capability of the 3D flow prediction network through proposed Cyclic warp loss by converting warped 3D features back into 2D RGB space. To ensure the generation of finer facial region with natural-background, our framework only renders the facial foreground region first and learns to inpaint the blank area which needs to be filled due to source face translation, thus reconstructing the detailed background without any unwanted pixel motion. Extensive evaluation reveals that our method outperforms state-of-the-art techniques in rendering artifact-free facial images.
4/24/2024
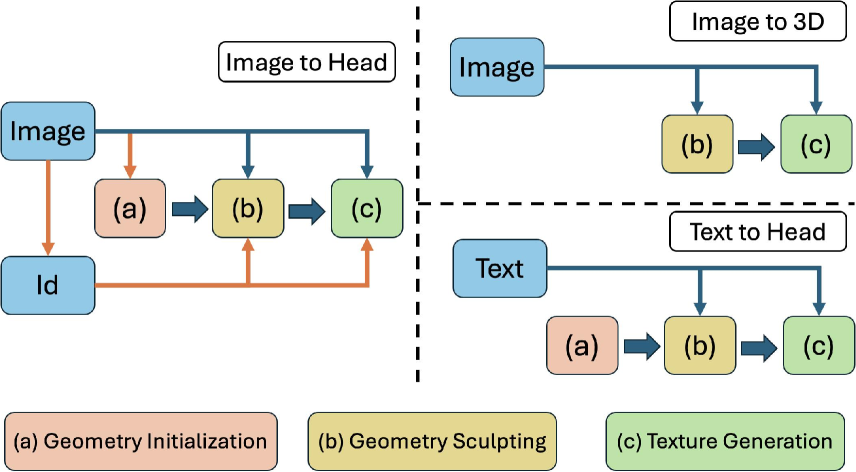
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024

Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
Inhee Lee, Byungjun Kim, Hanbyul Joo
0
0
In this paper, we present a method to reconstruct the world and multiple dynamic humans in 3D from a monocular video input. As a key idea, we represent both the world and multiple humans via the recently emerging 3D Gaussian Splatting (3D-GS) representation, enabling to conveniently and efficiently compose and render them together. In particular, we address the scenarios with severely limited and sparse observations in 3D human reconstruction, a common challenge encountered in the real world. To tackle this challenge, we introduce a novel approach to optimize the 3D-GS representation in a canonical space by fusing the sparse cues in the common space, where we leverage a pre-trained 2D diffusion model to synthesize unseen views while keeping the consistency with the observed 2D appearances. We demonstrate our method can reconstruct high-quality animatable 3D humans in various challenging examples, in the presence of occlusion, image crops, few-shot, and extremely sparse observations. After reconstruction, our method is capable of not only rendering the scene in any novel views at arbitrary time instances, but also editing the 3D scene by removing individual humans or applying different motions for each human. Through various experiments, we demonstrate the quality and efficiency of our methods over alternative existing approaches.
4/23/2024