Collaborative Semantic Occupancy Prediction with Hybrid Feature Fusion in Connected Automated Vehicles
2402.07635
0
0
🔮
Abstract
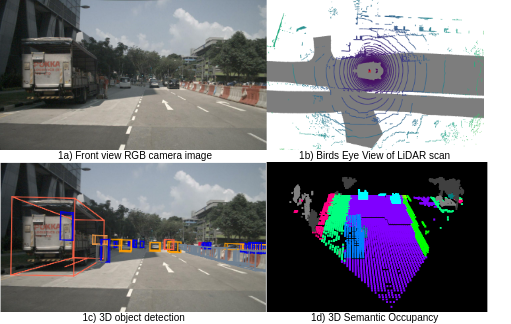
Collaborative perception in automated vehicles leverages the exchange of information between agents, aiming to elevate perception results. Previous camera-based collaborative 3D perception methods typically employ 3D bounding boxes or bird's eye views as representations of the environment. However, these approaches fall short in offering a comprehensive 3D environmental prediction. To bridge this gap, we introduce the first method for collaborative 3D semantic occupancy prediction. Particularly, it improves local 3D semantic occupancy predictions by hybrid fusion of (i) semantic and occupancy task features, and (ii) compressed orthogonal attention features shared between vehicles. Additionally, due to the lack of a collaborative perception dataset designed for semantic occupancy prediction, we augment a current collaborative perception dataset to include 3D collaborative semantic occupancy labels for a more robust evaluation. The experimental findings highlight that: (i) our collaborative semantic occupancy predictions excel above the results from single vehicles by over 30%, and (ii) models anchored on semantic occupancy outpace state-of-the-art collaborative 3D detection techniques in subsequent perception applications, showcasing enhanced accuracy and enriched semantic-awareness in road environments.
Create account to get full access
Overview
- This paper introduces a new method for collaborative 3D semantic occupancy prediction in automated vehicles.
- It aims to improve local 3D semantic occupancy predictions by fusing semantic and occupancy task features, as well as compressed attention features shared between vehicles.
- The authors also augment an existing collaborative perception dataset to include 3D collaborative semantic occupancy labels for more robust evaluation.
Plain English Explanation
Automated vehicles use sensors like cameras to perceive their surroundings. Collaborative perception is when these vehicles share information to improve their understanding of the environment. Previous collaborative 3D perception methods have used 3D bounding boxes or bird's eye views to represent the world. However, these approaches don't provide a comprehensive 3D prediction.
This paper introduces a new way for vehicles to collaboratively predict the 3D semantic occupancy of their surroundings. It does this by combining different types of information, like the semantic meaning of objects and whether spaces are occupied or not. Vehicles also share compressed attention features, which highlight important areas, to further improve the predictions.
Since there wasn't an existing dataset for this type of collaborative 3D semantic occupancy prediction, the authors created one by adding new labels to an existing dataset. Their experiments show that collaborative predictions are over 30% better than individual vehicle predictions. Additionally, the semantic occupancy approach outperforms state-of-the-art 3D detection techniques in subsequent perception tasks, providing more accurate and detailed understanding of the road environment.
Technical Explanation
This paper presents a novel method for collaborative 3D semantic occupancy prediction in automated vehicles. Previous collaborative 3D perception approaches have relied on representations like 3D bounding boxes or bird's eye views, which fail to provide a comprehensive 3D understanding of the environment.
To address this, the authors introduce a collaborative semantic occupancy prediction framework. It improves local 3D semantic occupancy predictions through a hybrid fusion of (i) semantic and occupancy task features, and (ii) compressed orthogonal attention features shared between vehicles. This allows the model to better capture the semantic meaning and spatial occupancy of the 3D environment.
Additionally, the authors augment an existing collaborative perception dataset to include 3D collaborative semantic occupancy labels. This provides a more robust evaluation platform for this new task.
The experimental results demonstrate that the collaborative semantic occupancy predictions outperform single vehicle predictions by over 30%. Furthermore, the semantic occupancy-based models outshine state-of-the-art collaborative 3D detection techniques in subsequent perception applications, showcasing enhanced accuracy and enriched semantic awareness in road environments.
Critical Analysis
The paper presents a promising approach for collaborative 3D semantic occupancy prediction in automated vehicles. By fusing semantic and occupancy information, as well as sharing attention features between vehicles, the method is able to provide a more comprehensive 3D understanding of the environment.
However, the paper does not delve into the potential limitations or challenges of this approach. For example, it does not discuss how the method would perform in complex or crowded urban environments, where occlusions and sensor noise may be more prevalent. Additionally, the reliance on shared attention features raises questions about the scalability and robustness of the approach as the number of collaborating vehicles increases.
Furthermore, the paper does not address potential privacy and security concerns that may arise from the exchange of sensitive sensor data between vehicles. As collaborative perception systems become more widespread, these issues will need to be carefully considered and addressed.
Overall, the research represents an important step forward in collaborative 3D perception for automated vehicles. However, further investigation is needed to fully understand the strengths, weaknesses, and real-world applicability of the proposed method.
Conclusion
This paper introduces a novel approach for collaborative 3D semantic occupancy prediction in automated vehicles. By fusing semantic and occupancy information, as well as sharing compressed attention features between vehicles, the method is able to provide a more comprehensive 3D understanding of the environment. The experimental results demonstrate significant improvements in prediction accuracy compared to single-vehicle approaches, as well as superior performance in subsequent perception tasks.
The development of robust and reliable collaborative perception systems is a crucial step towards the widespread adoption of automated vehicles. This research represents an important contribution to this field, offering a new way for vehicles to collectively perceive and understand their surroundings. While further research is needed to address potential limitations and challenges, this work highlights the potential of collaborative perception to enhance the safety and intelligence of self-driving technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Vision-based 3D occupancy prediction in autonomous driving: a review and outlook
Yanan Zhang, Jinqing Zhang, Zengran Wang, Junhao Xu, Di Huang
0
0
In recent years, autonomous driving has garnered escalating attention for its potential to relieve drivers' burdens and improve driving safety. Vision-based 3D occupancy prediction, which predicts the spatial occupancy status and semantics of 3D voxel grids around the autonomous vehicle from image inputs, is an emerging perception task suitable for cost-effective perception system of autonomous driving. Although numerous studies have demonstrated the greater advantages of 3D occupancy prediction over object-centric perception tasks, there is still a lack of a dedicated review focusing on this rapidly developing field. In this paper, we first introduce the background of vision-based 3D occupancy prediction and discuss the challenges in this task. Secondly, we conduct a comprehensive survey of the progress in vision-based 3D occupancy prediction from three aspects: feature enhancement, deployment friendliness and label efficiency, and provide an in-depth analysis of the potentials and challenges of each category of methods. Finally, we present a summary of prevailing research trends and propose some inspiring future outlooks. To provide a valuable reference for researchers, a regularly updated collection of related papers, datasets, and codes is organized at https://github.com/zya3d/Awesome-3D-Occupancy-Prediction.
5/7/2024
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
0
0
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
5/21/2024
🖼️
A Survey on Occupancy Perception for Autonomous Driving: The Information Fusion Perspective
Huaiyuan Xu, Junliang Chen, Shiyu Meng, Yi Wang, Lap-Pui Chau
0
0
3D occupancy perception technology aims to observe and understand dense 3D environments for autonomous vehicles. Owing to its comprehensive perception capability, this technology is emerging as a trend in autonomous driving perception systems, and is attracting significant attention from both industry and academia. Similar to traditional bird's-eye view (BEV) perception, 3D occupancy perception has the nature of multi-source input and the necessity for information fusion. However, the difference is that it captures vertical structures that are ignored by 2D BEV. In this survey, we review the most recent works on 3D occupancy perception, and provide in-depth analyses of methodologies with various input modalities. Specifically, we summarize general network pipelines, highlight information fusion techniques, and discuss effective network training. We evaluate and analyze the occupancy perception performance of the state-of-the-art on the most popular datasets. Furthermore, challenges and future research directions are discussed. We hope this paper will inspire the community and encourage more research work on 3D occupancy perception. A comprehensive list of studies in this survey is publicly available in an active repository that continuously collects the latest work: https://github.com/HuaiyuanXu/3D-Occupancy-Perception.
5/21/2024

Co-Occ: Coupling Explicit Feature Fusion with Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction
Jingyi Pan, Zipeng Wang, Lin Wang
0
0
3D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction. The project page is available at https://rorisis.github.io/Co-Occ_project-page/.
5/24/2024