Combating Missing Modalities in Egocentric Videos at Test Time
2404.15161
0
0
🌿
Abstract
Understanding videos that contain multiple modalities is crucial, especially in egocentric videos, where combining various sensory inputs significantly improves tasks like action recognition and moment localization. However, real-world applications often face challenges with incomplete modalities due to privacy concerns, efficiency needs, or hardware issues. Current methods, while effective, often necessitate retraining the model entirely to handle missing modalities, making them computationally intensive, particularly with large training datasets. In this study, we propose a novel approach to address this issue at test time without requiring retraining. We frame the problem as a test-time adaptation task, where the model adjusts to the available unlabeled data at test time. Our method, MiDl~(Mutual information with self-Distillation), encourages the model to be insensitive to the specific modality source present during testing by minimizing the mutual information between the prediction and the available modality. Additionally, we incorporate self-distillation to maintain the model's original performance when both modalities are available. MiDl represents the first self-supervised, online solution for handling missing modalities exclusively at test time. Through experiments with various pretrained models and datasets, MiDl demonstrates substantial performance improvement without the need for retraining.
Create account to get full access
Overview
- Effectively understanding videos with multiple sensory inputs (such as sight, sound, and touch) is crucial, especially for egocentric videos where combining these inputs significantly improves tasks like action recognition and moment localization.
- However, real-world applications often face challenges with incomplete or missing modalities due to privacy concerns, efficiency needs, or hardware issues.
- Current methods require retraining the model entirely to handle missing modalities, which can be computationally intensive, particularly with large training datasets.
Plain English Explanation
Understanding videos that contain multiple types of information, such as visual, audio, and tactile cues, is very important, especially for videos from a person's perspective where combining these different inputs can greatly improve tasks like recognizing actions and identifying important moments.
However, in real-world applications, there are often problems with not having access to all the different types of information, either because of privacy concerns, the need to be efficient, or issues with the hardware. The current methods to deal with this require completely retraining the model, which can be computationally expensive, especially when working with large datasets.
Technical Explanation
This study proposes a novel approach to address the issue of missing modalities at test time without requiring retraining. The researchers frame the problem as a test-time adaptation task, where the model adjusts to the available unlabeled data at test time.
Their method, called MiDl (Mutual information with self-Distillation), encourages the model to be less sensitive to the specific modality source present during testing. It does this by minimizing the mutual information between the model's prediction and the available modality. Additionally, MiDl incorporates self-distillation to help maintain the model's original performance when both modalities are available.
MiDl represents the first self-supervised, online solution for handling missing modalities exclusively at test time. Through experiments with various pretrained models and datasets, the researchers show that MiDl can substantially improve performance without the need for retraining, as is required by current methods for dealing with missing modalities.
Critical Analysis
The paper presents a promising approach to a relevant problem in the field of multimodal learning. By framing the issue as a test-time adaptation task and leveraging techniques like mutual information minimization and self-distillation, the researchers have developed a novel solution that avoids the need for retraining.
However, the paper does not provide a thorough analysis of the limitations or potential drawbacks of the MiDl method. For example, it is unclear how well the approach would scale to scenarios with more than two modalities or how sensitive the performance is to the quality and consistency of the available modality.
Additionally, the researchers could have explored alternative approaches for handling missing modalities, such as interpretable detection of out-of-context information, to provide a more comprehensive perspective on the problem and potential solutions.
Conclusion
This study presents a novel approach, MiDl, for addressing the challenge of missing modalities in multimodal learning, particularly in the context of egocentric video understanding. By framing the problem as a test-time adaptation task and leveraging techniques like mutual information minimization and self-distillation, the researchers have developed a self-supervised, online solution that can significantly improve performance without the need for retraining.
While the paper demonstrates the effectiveness of MiDl through experiments, it would benefit from a more thorough analysis of the method's limitations and potential areas for further research. Nonetheless, this work represents an important step forward in the field of multimodal learning, with the potential to enable more robust and practical applications in real-world scenarios where modalities may be incomplete or unavailable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Enhancing Multi-modal Learning: Meta-learned Cross-modal Knowledge Distillation for Handling Missing Modalities
Hu Wang, Congbo Ma, Yuyuan Liu, Yuanhong Chen, Yu Tian, Jodie Avery, Louise Hull, Gustavo Carneiro
0
0
In multi-modal learning, some modalities are more influential than others, and their absence can have a significant impact on classification/segmentation accuracy. Hence, an important research question is if it is possible for trained multi-modal models to have high accuracy even when influential modalities are absent from the input data. In this paper, we propose a novel approach called Meta-learned Cross-modal Knowledge Distillation (MCKD) to address this research question. MCKD adaptively estimates the importance weight of each modality through a meta-learning process. These dynamically learned modality importance weights are used in a pairwise cross-modal knowledge distillation process to transfer the knowledge from the modalities with higher importance weight to the modalities with lower importance weight. This cross-modal knowledge distillation produces a highly accurate model even with the absence of influential modalities. Differently from previous methods in the field, our approach is designed to work in multiple tasks (e.g., segmentation and classification) with minimal adaptation. Experimental results on the Brain tumor Segmentation Dataset 2018 (BraTS2018) and the Audiovision-MNIST classification dataset demonstrate the superiority of MCKD over current state-of-the-art models. Particularly in BraTS2018, we achieve substantial improvements of 3.51% for enhancing tumor, 2.19% for tumor core, and 1.14% for the whole tumor in terms of average segmentation Dice score.
5/14/2024
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
0
0
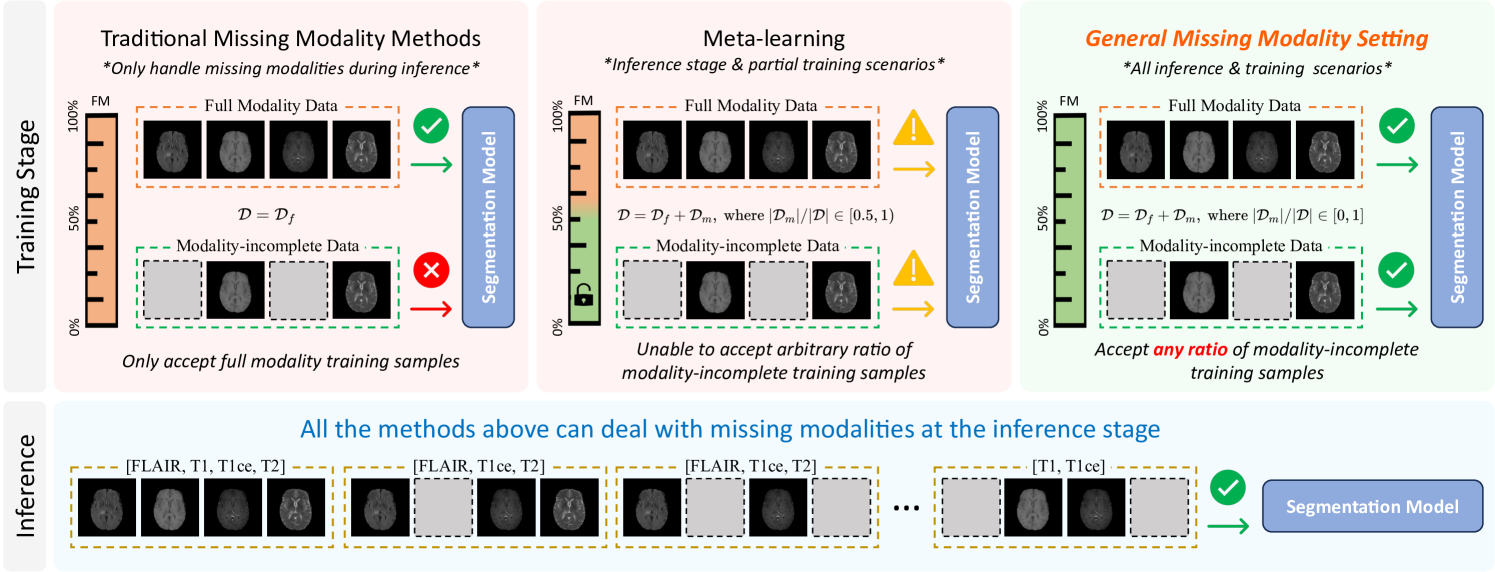
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
6/5/2024
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
0
0
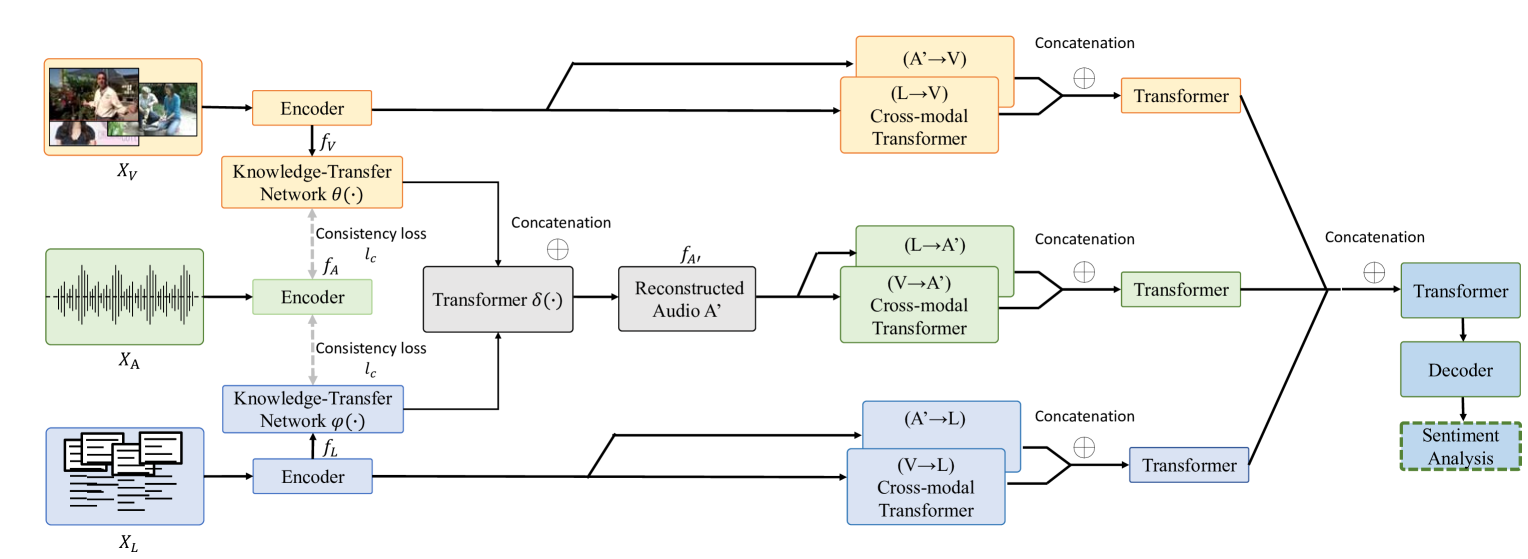
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
6/21/2024
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Luciana Trinkaus Menon, Luiz Carlos Ribeiro Neduziak, Jean Paul Barddal, Alessandro Lameiras Koerich, Alceu de Souza Britto Jr
0
0
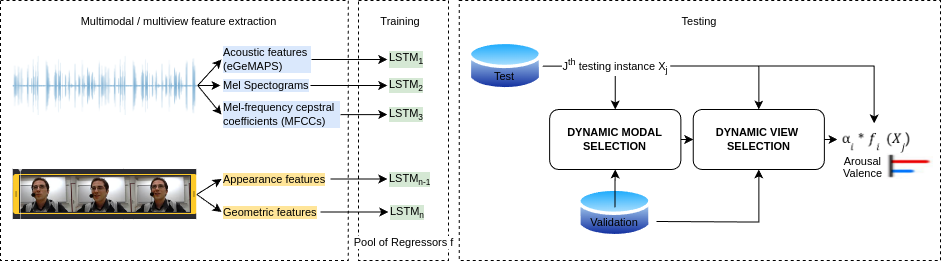
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
4/19/2024